 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDashed Line Defense: Plug-And-Play Defense Against Adaptive Score-Based Query Attacks
Feb 09, 2026Score-based query attacks pose a serious threat to deep learning models by crafting adversarial examples (AEs) using only black-box access to model output scores, iteratively optimizing inputs based on observed loss values. While recent runtime defenses attempt to disrupt this process via output perturbation, most either require access to model parameters or fail when attackers adapt their tactics. In this paper, we first reveal that even the state-of-the-art plug-and-play defense can be bypassed by adaptive attacks, exposing a critical limitation of existing runtime defenses. We then propose Dashed Line Defense (DLD), a plug-and-play post-processing method specifically designed to withstand adaptive query strategies. By introducing ambiguity in how the observed loss reflects the true adversarial strength of candidate examples, DLD prevents attackers from reliably analyzing and adapting their queries, effectively disrupting the AE generation process. We provide theoretical guarantees of DLD's defense capability and validate its effectiveness through experiments on ImageNet, demonstrating that DLD consistently outperforms prior defenses--even under worst-case adaptive attacks--while preserving the model's predicted labels.
Boosting Micro-Expression Analysis via Prior-Guided Video-Level Regression
Aug 26, 2025Micro-expressions (MEs) are involuntary, low-intensity, and short-duration facial expressions that often reveal an individual's genuine thoughts and emotions. Most existing ME analysis methods rely on window-level classification with fixed window sizes and hard decisions, which limits their ability to capture the complex temporal dynamics of MEs. Although recent approaches have adopted video-level regression frameworks to address some of these challenges, interval decoding still depends on manually predefined, window-based methods, leaving the issue only partially mitigated. In this paper, we propose a prior-guided video-level regression method for ME analysis. We introduce a scalable interval selection strategy that comprehensively considers the temporal evolution, duration, and class distribution characteristics of MEs, enabling precise spotting of the onset, apex, and offset phases. In addition, we introduce a synergistic optimization framework, in which the spotting and recognition tasks share parameters except for the classification heads. This fully exploits complementary information, makes more efficient use of limited data, and enhances the model's capability. Extensive experiments on multiple benchmark datasets demonstrate the state-of-the-art performance of our method, with an STRS of 0.0562 on CAS(ME)$^3$ and 0.2000 on SAMMLV. The code is available at https://github.com/zizheng-guo/BoostingVRME.
ME-TST+: Micro-expression Analysis via Temporal State Transition with ROI Relationship Awareness
Aug 11, 2025Micro-expressions (MEs) are regarded as important indicators of an individual's intrinsic emotions, preferences, and tendencies. ME analysis requires spotting of ME intervals within long video sequences and recognition of their corresponding emotional categories. Previous deep learning approaches commonly employ sliding-window classification networks. However, the use of fixed window lengths and hard classification presents notable limitations in practice. Furthermore, these methods typically treat ME spotting and recognition as two separate tasks, overlooking the essential relationship between them. To address these challenges, this paper proposes two state space model-based architectures, namely ME-TST and ME-TST+, which utilize temporal state transition mechanisms to replace conventional window-level classification with video-level regression. This enables a more precise characterization of the temporal dynamics of MEs and supports the modeling of MEs with varying durations. In ME-TST+, we further introduce multi-granularity ROI modeling and the slowfast Mamba framework to alleviate information loss associated with treating ME analysis as a time-series task. Additionally, we propose a synergy strategy for spotting and recognition at both the feature and result levels, leveraging their intrinsic connection to enhance overall analysis performance. Extensive experiments demonstrate that the proposed methods achieve state-of-the-art performance. The codes are available at https://github.com/zizheng-guo/ME-TST.
Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition
Sep 15, 2024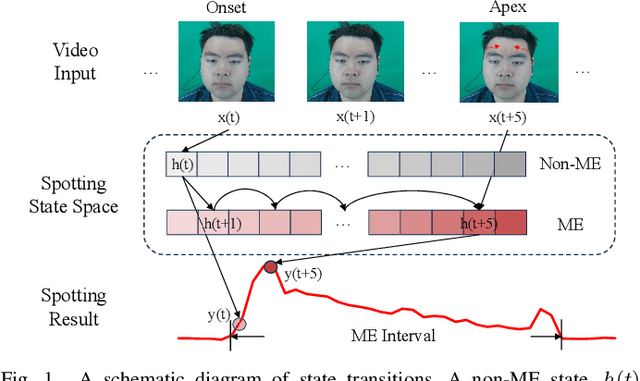
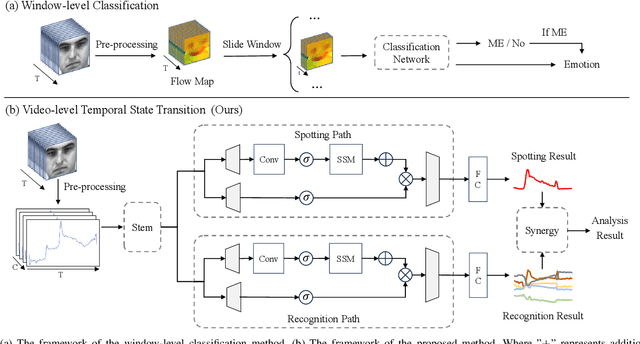
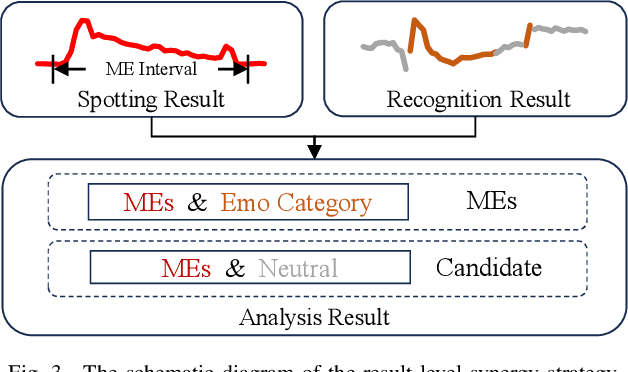
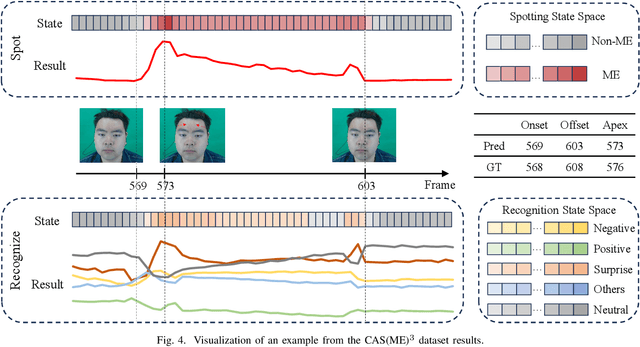
Micro-expressions are involuntary facial movements that cannot be consciously controlled, conveying subtle cues with substantial real-world applications. The analysis of micro-expressions generally involves two main tasks: spotting micro-expression intervals in long videos and recognizing the emotions associated with these intervals. Previous deep learning methods have primarily relied on classification networks utilizing sliding windows. However, fixed window sizes and window-level hard classification introduce numerous constraints. Additionally, these methods have not fully exploited the potential of complementary pathways for spotting and recognition. In this paper, we present a novel temporal state transition architecture grounded in the state space model, which replaces conventional window-level classification with video-level regression. Furthermore, by leveraging the inherent connections between spotting and recognition tasks, we propose a synergistic strategy that enhances overall analysis performance. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The codes and pre-trained models are available at https://github.com/zizheng-guo/ME-TST.
Data Debugging is NP-hard for Classifiers Trained with SGD
Aug 02, 2024Data debugging is to find a subset of the training data such that the model obtained by retraining on the subset has a better accuracy. A bunch of heuristic approaches are proposed, however, none of them are guaranteed to solve this problem effectively. This leaves an open issue whether there exists an efficient algorithm to find the subset such that the model obtained by retraining on it has a better accuracy. To answer this open question and provide theoretical basis for further study on developing better algorithms for data debugging, we investigate the computational complexity of the problem named Debuggable. Given a machine learning model $\mathcal{M}$ obtained by training on dataset $D$ and a test instance $(\mathbf{x}_\text{test},y_\text{test})$ where $\mathcal{M}(\mathbf{x}_\text{test})\neq y_\text{test}$, Debuggable is to determine whether there exists a subset $D^\prime$ of $D$ such that the model $\mathcal{M}^\prime$ obtained by retraining on $D^\prime$ satisfies $\mathcal{M}^\prime(\mathbf{x}_\text{test})=y_\text{test}$. To cover a wide range of commonly used models, we take SGD-trained linear classifier as the model and derive the following main results. (1) If the loss function and the dimension of the model are not fixed, Debuggable is NP-complete regardless of the training order in which all the training samples are processed during SGD. (2) For hinge-like loss functions, a comprehensive analysis on the computational complexity of Debuggable is provided; (3) If the loss function is a linear function, Debuggable can be solved in linear time, that is, data debugging can be solved easily in this case. These results not only highlight the limitations of current approaches but also offer new insights into data debugging.
RhythmMamba: Fast Remote Physiological Measurement with Arbitrary Length Videos
Apr 09, 2024



Remote photoplethysmography (rPPG) is a non-contact method for detecting physiological signals from facial videos, holding great potential in various applications such as healthcare, affective computing, and anti-spoofing. Existing deep learning methods struggle to address two core issues of rPPG simultaneously: extracting weak rPPG signals from video segments with large spatiotemporal redundancy and understanding the periodic patterns of rPPG among long contexts. This represents a trade-off between computational complexity and the ability to capture long-range dependencies, posing a challenge for rPPG that is suitable for deployment on mobile devices. Based on the in-depth exploration of Mamba's comprehension of spatial and temporal information, this paper introduces RhythmMamba, an end-to-end Mamba-based method that employs multi-temporal Mamba to constrain both periodic patterns and short-term trends, coupled with frequency domain feed-forward to enable Mamba to robustly understand the quasi-periodic patterns of rPPG. Extensive experiments show that RhythmMamba achieves state-of-the-art performance with reduced parameters and lower computational complexity. The proposed RhythmMamba can be applied to video segments of any length without performance degradation. The codes are available at https://github.com/zizheng-guo/RhythmMamba.
RhythmFormer: Extracting rPPG Signals Based on Hierarchical Temporal Periodic Transformer
Feb 20, 2024Remote photoplethysmography (rPPG) is a non-contact method for detecting physiological signals based on facial videos, holding high potential in various applications such as healthcare, affective computing, anti-spoofing, etc. Due to the periodicity nature of rPPG, the long-range dependency capturing capacity of the Transformer was assumed to be advantageous for such signals. However, existing approaches have not conclusively demonstrated the superior performance of Transformer over traditional convolutional neural network methods, this gap may stem from a lack of thorough exploration of rPPG periodicity. In this paper, we propose RhythmFormer, a fully end-to-end transformer-based method for extracting rPPG signals by explicitly leveraging the quasi-periodic nature of rPPG. The core module, Hierarchical Temporal Periodic Transformer, hierarchically extracts periodic features from multiple temporal scales. It utilizes dynamic sparse attention based on periodicity in the temporal domain, allowing for fine-grained modeling of rPPG features. Furthermore, a fusion stem is proposed to guide self-attention to rPPG features effectively, and it can be easily transferred to existing methods to enhance their performance significantly. RhythmFormer achieves state-of-the-art performance with fewer parameters and reduced computational complexity in comprehensive experiments compared to previous approaches. The codes are available at https://github.com/zizheng-guo/RhythmFormer.
VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects
Jun 28, 2021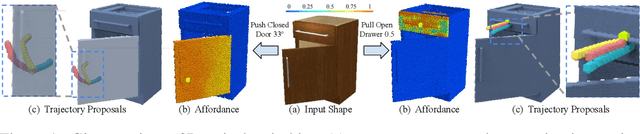

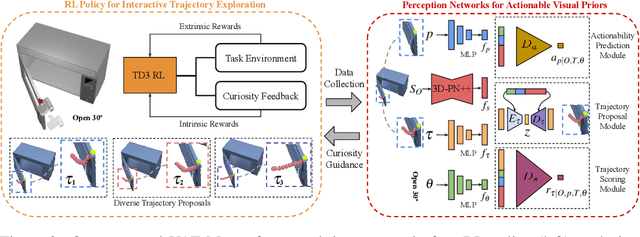

Perceiving and manipulating 3D articulated objects (e.g., cabinets, doors) in human environments is an important yet challenging task for future home-assistant robots. The space of 3D articulated objects is exceptionally rich in their myriad semantic categories, diverse shape geometry, and complicated part functionality. Previous works mostly abstract kinematic structure with estimated joint parameters and part poses as the visual representations for manipulating 3D articulated objects. In this paper, we propose object-centric actionable visual priors as a novel perception-interaction handshaking point that the perception system outputs more actionable guidance than kinematic structure estimation, by predicting dense geometry-aware, interaction-aware, and task-aware visual action affordance and trajectory proposals. We design an interaction-for-perception framework VAT-Mart to learn such actionable visual representations by simultaneously training a curiosity-driven reinforcement learning policy exploring diverse interaction trajectories and a perception module summarizing and generalizing the explored knowledge for pointwise predictions among diverse shapes. Experiments prove the effectiveness of the proposed approach using the large-scale PartNet-Mobility dataset in SAPIEN environment and show promising generalization capabilities to novel test shapes, unseen object categories, and real-world data. Project page: https://hyperplane-lab.github.io/vat-mart