 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-contact Vital Signs Detection in Dynamic Environments
May 13, 2025


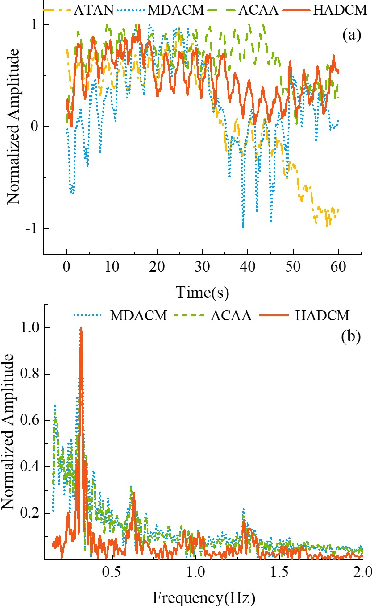
Accurate phase demodulation is critical for vital sign detection using millimeter-wave radar. However, in complex environments, time-varying DC offsets and phase imbalances can severely degrade demodulation performance. To address this, we propose a novel DC offset calibration method alongside a Hilbert and Differential Cross-Multiply (HADCM) demodulation algorithm. The approach estimates time-varying DC offsets from neighboring signal peaks and valleys, then employs both differential forms and Hilbert transforms of the I/Q channel signals to extract vital sign information. Simulation and experimental results demonstrate that the proposed method maintains robust performance under low signal-to-noise ratios. Compared to existing demodulation techniques, it offers more accurate signal recovery in challenging scenarios and effectively suppresses noise interference.
CCL: Collaborative Curriculum Learning for Sparse-Reward Multi-Agent Reinforcement Learning via Co-evolutionary Task Evolution
May 08, 2025



Sparse reward environments pose significant challenges in reinforcement learning, especially within multi-agent systems (MAS) where feedback is delayed and shared across agents, leading to suboptimal learning. We propose Collaborative Multi-dimensional Course Learning (CCL), a novel curriculum learning framework that addresses this by (1) refining intermediate tasks for individual agents, (2) using a variational evolutionary algorithm to generate informative subtasks, and (3) co-evolving agents with their environment to enhance training stability. Experiments on five cooperative tasks in the MPE and Hide-and-Seek environments show that CCL outperforms existing methods in sparse reward settings.
GaMNet: A Hybrid Network with Gabor Fusion and NMamba for Efficient 3D Glioma Segmentation
May 08, 2025Gliomas are aggressive brain tumors that pose serious health risks. Deep learning aids in lesion segmentation, but CNN and Transformer-based models often lack context modeling or demand heavy computation, limiting real-time use on mobile medical devices. We propose GaMNet, integrating the NMamba module for global modeling and a multi-scale CNN for efficient local feature extraction. To improve interpretability and mimic the human visual system, we apply Gabor filters at multiple scales. Our method achieves high segmentation accuracy with fewer parameters and faster computation. Extensive experiments show GaMNet outperforms existing methods, notably reducing false positives and negatives, which enhances the reliability of clinical diagnosis.
GAME: Learning Multimodal Interactions via Graph Structures for Personality Trait Estimation
May 05, 2025Apparent personality analysis from short videos poses significant chal-lenges due to the complex interplay of visual, auditory, and textual cues. In this paper, we propose GAME, a Graph-Augmented Multimodal Encoder designed to robustly model and fuse multi-source features for automatic personality prediction. For the visual stream, we construct a facial graph and introduce a dual-branch Geo Two-Stream Network, which combines Graph Convolutional Networks (GCNs) and Convolutional Neural Net-works (CNNs) with attention mechanisms to capture both structural and appearance-based facial cues. Complementing this, global context and iden-tity features are extracted using pretrained ResNet18 and VGGFace back-bones. To capture temporal dynamics, frame-level features are processed by a BiGRU enhanced with temporal attention modules. Meanwhile, audio representations are derived from the VGGish network, and linguistic se-mantics are captured via the XLM-Roberta transformer. To achieve effective multimodal integration, we propose a Channel Attention-based Fusion module, followed by a Multi-Layer Perceptron (MLP) regression head for predicting personality traits. Extensive experiments show that GAME con-sistently outperforms existing methods across multiple benchmarks, vali-dating its effectiveness and generalizability.
Efficient Knowledge Transfer in Multi-Task Learning through Task-Adaptive Low-Rank Representation
Apr 20, 2025Pre-trained language models (PLMs) demonstrate remarkable intelligence but struggle with emerging tasks unseen during training in real-world applications. Training separate models for each new task is usually impractical. Multi-task learning (MTL) addresses this challenge by transferring shared knowledge from source tasks to target tasks. As an dominant parameter-efficient fine-tuning method, prompt tuning (PT) enhances MTL by introducing an adaptable vector that captures task-specific knowledge, which acts as a prefix to the original prompt that preserves shared knowledge, while keeping PLM parameters frozen. However, PT struggles to effectively capture the heterogeneity of task-specific knowledge due to its limited representational capacity. To address this challenge, we propose Task-Adaptive Low-Rank Representation (TA-LoRA), an MTL method built on PT, employing the low-rank representation to model task heterogeneity and a fast-slow weights mechanism where the slow weight encodes shared knowledge, while the fast weight captures task-specific nuances, avoiding the mixing of shared and task-specific knowledge, caused by training low-rank representations from scratch. Moreover, a zero-initialized attention mechanism is introduced to minimize the disruption of immature low-rank components on original prompts during warm-up epochs. Experiments on 16 tasks demonstrate that TA-LoRA achieves state-of-the-art performance in full-data and few-shot settings while maintaining superior parameter efficiency.
Graph-Driven Multimodal Feature Learning Framework for Apparent Personality Assessment
Apr 15, 2025Predicting personality traits automatically has become a challenging problem in computer vision. This paper introduces an innovative multimodal feature learning framework for personality analysis in short video clips. For visual processing, we construct a facial graph and design a Geo-based two-stream network incorporating an attention mechanism, leveraging both Graph Convolutional Networks (GCN) and Convolutional Neural Networks (CNN) to capture static facial expressions. Additionally, ResNet18 and VGGFace networks are employed to extract global scene and facial appearance features at the frame level. To capture dynamic temporal information, we integrate a BiGRU with a temporal attention module for extracting salient frame representations. To enhance the model's robustness, we incorporate the VGGish CNN for audio-based features and XLM-Roberta for text-based features. Finally, a multimodal channel attention mechanism is introduced to integrate different modalities, and a Multi-Layer Perceptron (MLP) regression model is used to predict personality traits. Experimental results confirm that our proposed framework surpasses existing state-of-the-art approaches in performance.
CreDes: Causal Reasoning Enhancement and Dual-End Searching for Solving Long-Range Reasoning Problems using LLMs
Oct 02, 2024Large language models (LLMs) have demonstrated limitations in handling combinatorial optimization problems involving long-range reasoning, partially due to causal hallucinations and huge search space. As for causal hallucinations, i.e., the inconsistency between reasoning and corresponding state transition, this paper introduces the Causal Relationship Enhancement (CRE) mechanism combining cause-effect interventions and the Individual Treatment Effect (ITE) to guarantee the solid causal rightness between each step of reasoning and state transition. As for the long causal range and huge search space limiting the performances of existing models featuring single-direction search, a Dual-End Searching (DES) approach is proposed to seek solutions by simultaneously starting from both the initial and goal states on the causal probability tree. By integrating CRE and DES (CreDes), our model has realized simultaneous multi-step reasoning, circumventing the inefficiencies from cascading multiple one-step reasoning like the Chain-of-Thought (CoT). Experiments demonstrate that CreDes significantly outperforms existing State-Of-The-Art (SOTA) solutions in long-range reasoning tasks in terms of both accuracy and time efficiency.
Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition
Sep 15, 2024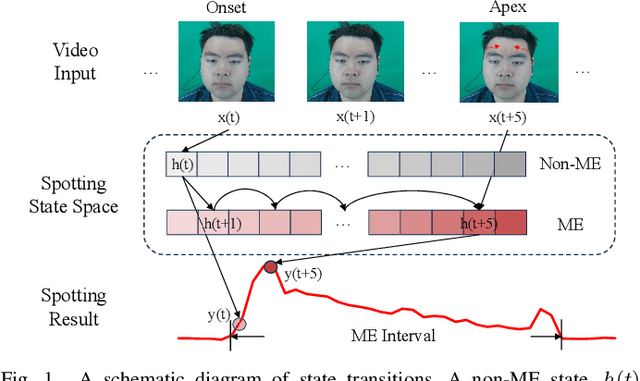
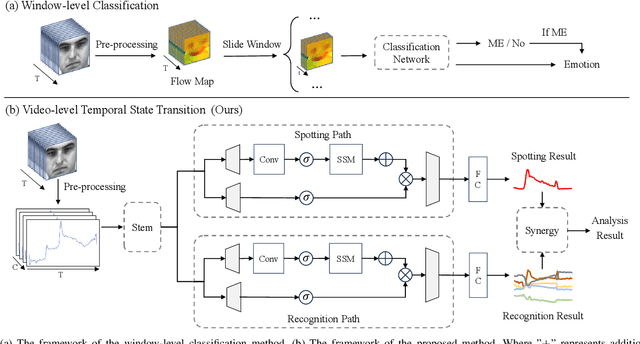
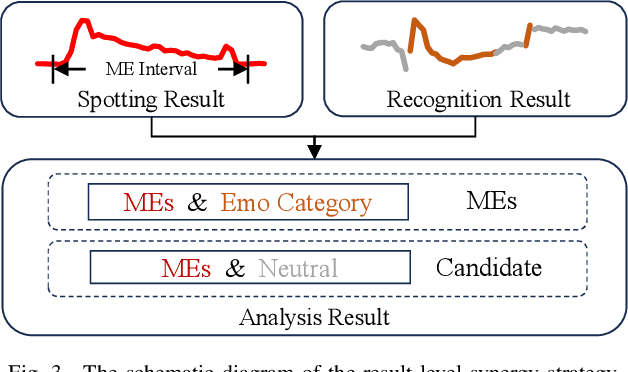
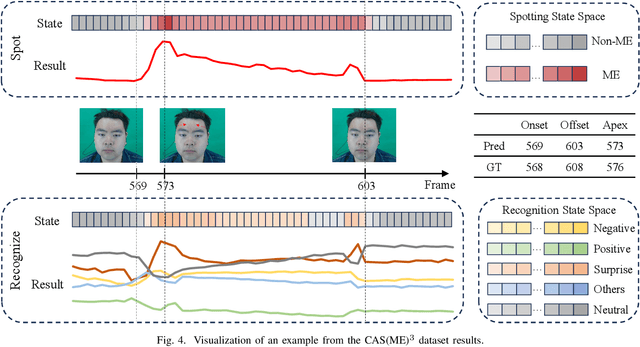
Micro-expressions are involuntary facial movements that cannot be consciously controlled, conveying subtle cues with substantial real-world applications. The analysis of micro-expressions generally involves two main tasks: spotting micro-expression intervals in long videos and recognizing the emotions associated with these intervals. Previous deep learning methods have primarily relied on classification networks utilizing sliding windows. However, fixed window sizes and window-level hard classification introduce numerous constraints. Additionally, these methods have not fully exploited the potential of complementary pathways for spotting and recognition. In this paper, we present a novel temporal state transition architecture grounded in the state space model, which replaces conventional window-level classification with video-level regression. Furthermore, by leveraging the inherent connections between spotting and recognition tasks, we propose a synergistic strategy that enhances overall analysis performance. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The codes and pre-trained models are available at https://github.com/zizheng-guo/ME-TST.