 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Only ToM: Enhancing Theory of Mind in Multimodal Large Language Models
Mar 25, 2026As large language models (LLMs) continue to advance, there is increasing interest in their ability to infer human mental states and demonstrate a human-like Theory of Mind (ToM). Most existing ToM evaluations, however, are centered on text-based inputs, while scenarios relying solely on visual information receive far less attention. This leaves a gap, since real-world human-AI interaction typically requires multimodal understanding. In addition, many current methods regard the model as a black box and rarely probe how its internal attention behaves in multiple-choice question answering (QA). The impact of LLM hallucinations on such tasks is also underexplored from an interpretability perspective. To address these issues, we introduce VisionToM, a vision-oriented intervention framework designed to strengthen task-aware reasoning. The core idea is to compute intervention vectors that align visual representations with the correct semantic targets, thereby steering the model's attention through different layers of visual features. This guidance reduces the model's reliance on spurious linguistic priors, leading to more reliable multimodal language model (MLLM) outputs and better QA performance. Experiments on the EgoToM benchmark-an egocentric, real-world video dataset for ToM with three multiple-choice QA settings-demonstrate that our method substantially improves the ToM abilities of MLLMs. Furthermore, results on an additional open-ended generation task show that VisionToM enables MLLMs to produce free-form explanations that more accurately capture agents' mental states, pushing machine-human collaboration toward greater alignment.
ME-TST+: Micro-expression Analysis via Temporal State Transition with ROI Relationship Awareness
Aug 11, 2025Micro-expressions (MEs) are regarded as important indicators of an individual's intrinsic emotions, preferences, and tendencies. ME analysis requires spotting of ME intervals within long video sequences and recognition of their corresponding emotional categories. Previous deep learning approaches commonly employ sliding-window classification networks. However, the use of fixed window lengths and hard classification presents notable limitations in practice. Furthermore, these methods typically treat ME spotting and recognition as two separate tasks, overlooking the essential relationship between them. To address these challenges, this paper proposes two state space model-based architectures, namely ME-TST and ME-TST+, which utilize temporal state transition mechanisms to replace conventional window-level classification with video-level regression. This enables a more precise characterization of the temporal dynamics of MEs and supports the modeling of MEs with varying durations. In ME-TST+, we further introduce multi-granularity ROI modeling and the slowfast Mamba framework to alleviate information loss associated with treating ME analysis as a time-series task. Additionally, we propose a synergy strategy for spotting and recognition at both the feature and result levels, leveraging their intrinsic connection to enhance overall analysis performance. Extensive experiments demonstrate that the proposed methods achieve state-of-the-art performance. The codes are available at https://github.com/zizheng-guo/ME-TST.
Confusing Pair Correction Based on Category Prototype for Domain Adaptation under Noisy Environments
Mar 19, 2024



In this paper, we address unsupervised domain adaptation under noisy environments, which is more challenging and practical than traditional domain adaptation. In this scenario, the model is prone to overfitting noisy labels, resulting in a more pronounced domain shift and a notable decline in the overall model performance. Previous methods employed prototype methods for domain adaptation on robust feature spaces. However, these approaches struggle to effectively classify classes with similar features under noisy environments. To address this issue, we propose a new method to detect and correct confusing class pair. We first divide classes into easy and hard classes based on the small loss criterion. We then leverage the top-2 predictions for each sample after aligning the source and target domain to find the confusing pair in the hard classes. We apply label correction to the noisy samples within the confusing pair. With the proposed label correction method, we can train our model with more accurate labels. Extensive experiments confirm the effectiveness of our method and demonstrate its favorable performance compared with existing state-of-the-art methods. Our codes are publicly available at https://github.com/Hehxcf/CPC/.
Orthogonal Temporal Interpolation for Zero-Shot Video Recognition
Aug 14, 2023Zero-shot video recognition (ZSVR) is a task that aims to recognize video categories that have not been seen during the model training process. Recently, vision-language models (VLMs) pre-trained on large-scale image-text pairs have demonstrated impressive transferability for ZSVR. To make VLMs applicable to the video domain, existing methods often use an additional temporal learning module after the image-level encoder to learn the temporal relationships among video frames. Unfortunately, for video from unseen categories, we observe an abnormal phenomenon where the model that uses spatial-temporal feature performs much worse than the model that removes temporal learning module and uses only spatial feature. We conjecture that improper temporal modeling on video disrupts the spatial feature of the video. To verify our hypothesis, we propose Feature Factorization to retain the orthogonal temporal feature of the video and use interpolation to construct refined spatial-temporal feature. The model using appropriately refined spatial-temporal feature performs better than the one using only spatial feature, which verifies the effectiveness of the orthogonal temporal feature for the ZSVR task. Therefore, an Orthogonal Temporal Interpolation module is designed to learn a better refined spatial-temporal video feature during training. Additionally, a Matching Loss is introduced to improve the quality of the orthogonal temporal feature. We propose a model called OTI for ZSVR by employing orthogonal temporal interpolation and the matching loss based on VLMs. The ZSVR accuracies on popular video datasets (i.e., Kinetics-600, UCF101 and HMDB51) show that OTI outperforms the previous state-of-the-art method by a clear margin.
Fast Batch Nuclear-norm Maximization and Minimization for Robust Domain Adaptation
Aug 04, 2021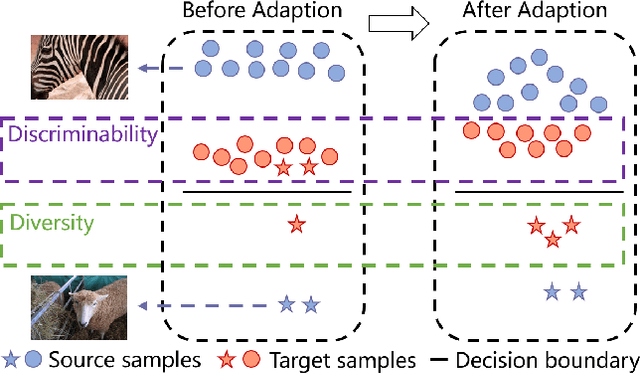
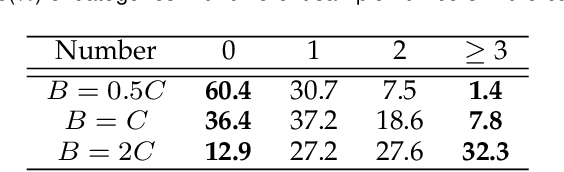
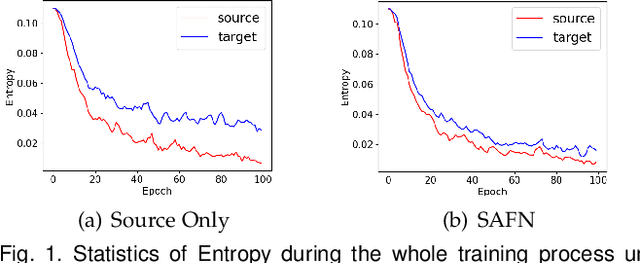
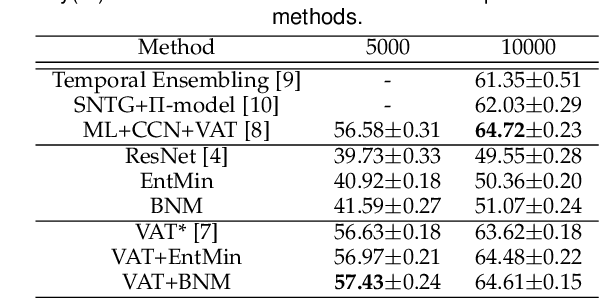
Due to the domain discrepancy in visual domain adaptation, the performance of source model degrades when bumping into the high data density near decision boundary in target domain. A common solution is to minimize the Shannon Entropy to push the decision boundary away from the high density area. However, entropy minimization also leads to severe reduction of prediction diversity, and unfortunately brings harm to the domain adaptation. In this paper, we investigate the prediction discriminability and diversity by studying the structure of the classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. The nuclear-norm is an upperbound of the former, and a convex approximation of the latter. Accordingly, we propose Batch Nuclear-norm Maximization and Minimization, which performs nuclear-norm maximization on the target output matrix to enhance the target prediction ability, and nuclear-norm minimization on the source batch output matrix to increase applicability of the source domain knowledge. We further approximate the nuclear-norm by L_{1,2}-norm, and design multi-batch optimization for stable solution on large number of categories. The fast approximation method achieves O(n^2) computational complexity and better convergence property. Experiments show that our method could boost the adaptation accuracy and robustness under three typical domain adaptation scenarios. The code is available at https://github.com/cuishuhao/BNM.
Learning Invariant Representation with Consistency and Diversity for Semi-supervised Source Hypothesis Transfer
Jul 20, 2021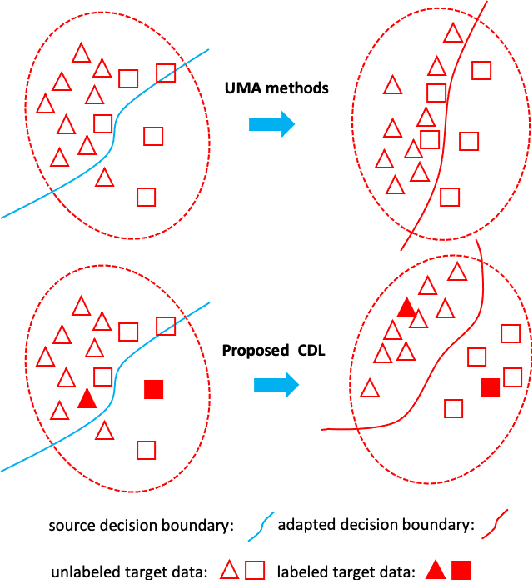

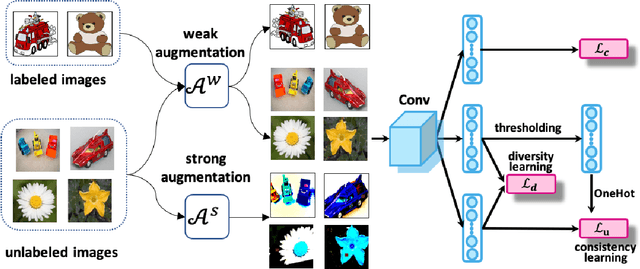
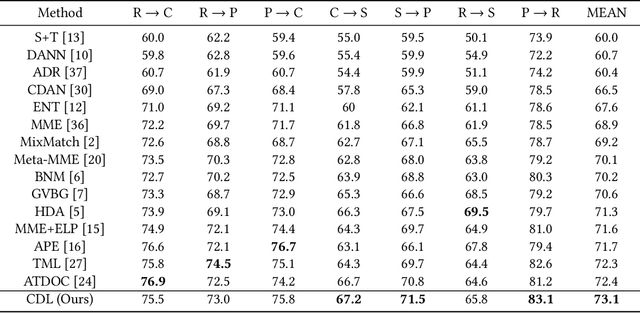
Semi-supervised domain adaptation (SSDA) aims to solve tasks in target domain by utilizing transferable information learned from the available source domain and a few labeled target data. However, source data is not always accessible in practical scenarios, which restricts the application of SSDA in real world circumstances. In this paper, we propose a novel task named Semi-supervised Source Hypothesis Transfer (SSHT), which performs domain adaptation based on source trained model, to generalize well in target domain with a few supervisions. In SSHT, we are facing two challenges: (1) The insufficient labeled target data may result in target features near the decision boundary, with the increased risk of mis-classification; (2) The data are usually imbalanced in source domain, so the model trained with these data is biased. The biased model is prone to categorize samples of minority categories into majority ones, resulting in low prediction diversity. To tackle the above issues, we propose Consistency and Diversity Learning (CDL), a simple but effective framework for SSHT by facilitating prediction consistency between two randomly augmented unlabeled data and maintaining the prediction diversity when adapting model to target domain. Encouraging consistency regularization brings difficulty to memorize the few labeled target data and thus enhances the generalization ability of the learned model. We further integrate Batch Nuclear-norm Maximization into our method to enhance the discriminability and diversity. Experimental results show that our method outperforms existing SSDA methods and unsupervised model adaptation methods on DomainNet, Office-Home and Office-31 datasets. The code is available at https://github.com/Wang-xd1899/SSHT.
Gradually Vanishing Bridge for Adversarial Domain Adaptation
Mar 30, 2020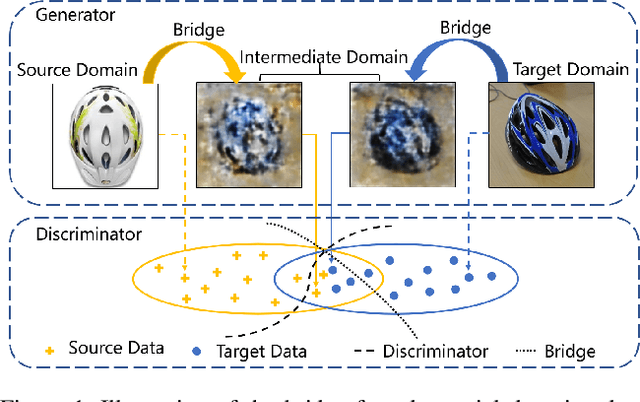
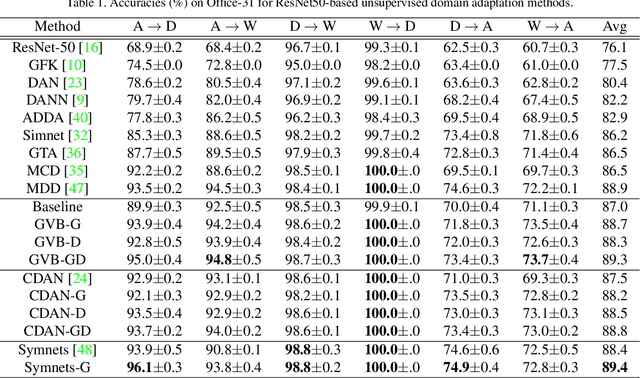
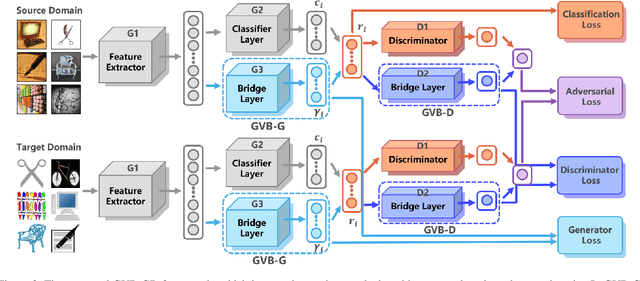
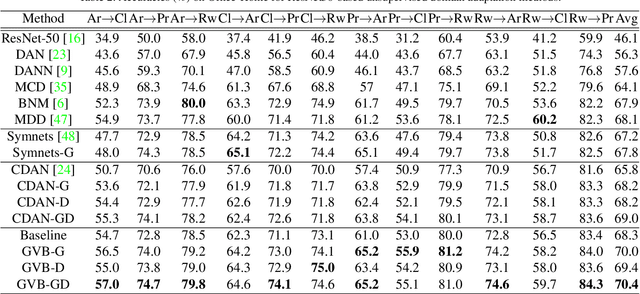
In unsupervised domain adaptation, rich domain-specific characteristics bring great challenge to learn domain-invariant representations. However, domain discrepancy is considered to be directly minimized in existing solutions, which is difficult to achieve in practice. Some methods alleviate the difficulty by explicitly modeling domain-invariant and domain-specific parts in the representations, but the adverse influence of the explicit construction lies in the residual domain-specific characteristics in the constructed domain-invariant representations. In this paper, we equip adversarial domain adaptation with Gradually Vanishing Bridge (GVB) mechanism on both generator and discriminator. On the generator, GVB could not only reduce the overall transfer difficulty, but also reduce the influence of the residual domain-specific characteristics in domain-invariant representations. On the discriminator, GVB contributes to enhance the discriminating ability, and balance the adversarial training process. Experiments on three challenging datasets show that our GVB methods outperform strong competitors, and cooperate well with other adversarial methods. The code is available at https://github.com/cuishuhao/GVB.
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations
Mar 27, 2020
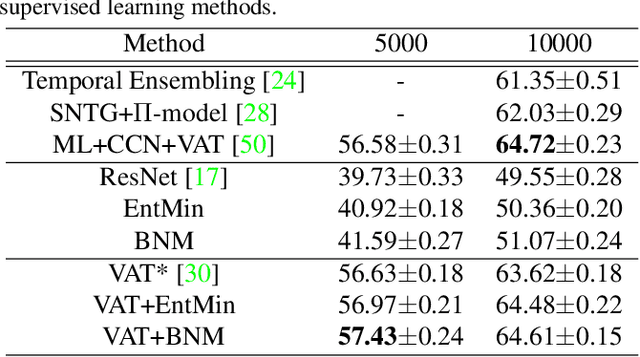
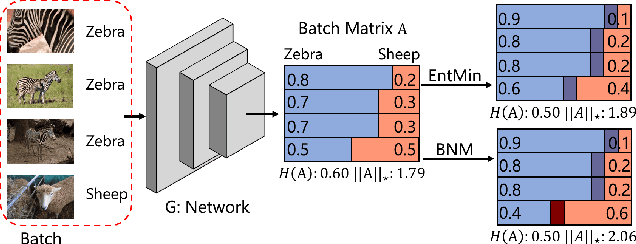
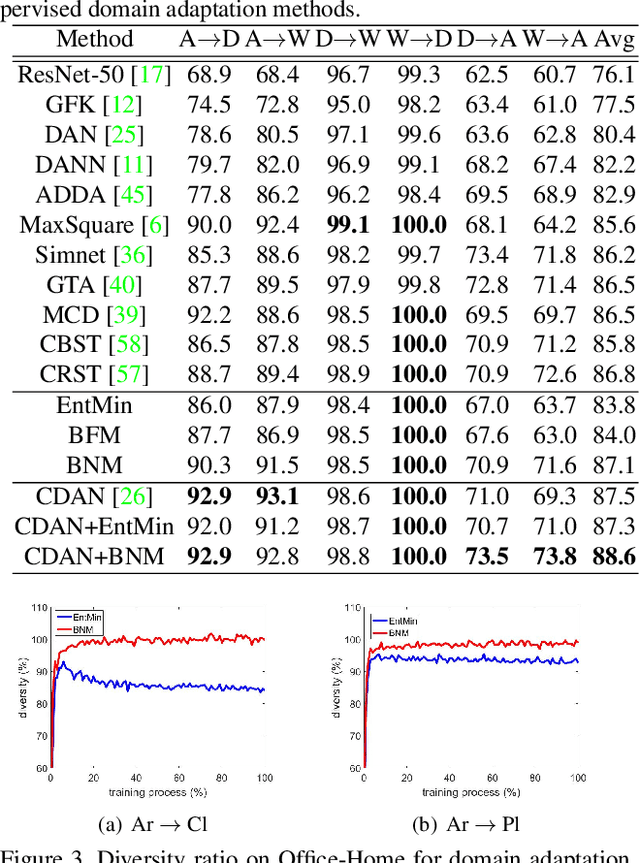
The learning of the deep networks largely relies on the data with human-annotated labels. In some label insufficient situations, the performance degrades on the decision boundary with high data density. A common solution is to directly minimize the Shannon Entropy, but the side effect caused by entropy minimization, i.e., reduction of the prediction diversity, is mostly ignored. To address this issue, we reinvestigate the structure of classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. Besides, the nuclear-norm is an upperbound of the Frobenius-norm, and a convex approximation of the matrix rank. Accordingly, to improve both discriminability and diversity, we propose Batch Nuclear-norm Maximization (BNM) on the output matrix. BNM could boost the learning under typical label insufficient learning scenarios, such as semi-supervised learning, domain adaptation and open domain recognition. On these tasks, extensive experimental results show that BNM outperforms competitors and works well with existing well-known methods. The code is available at https://github.com/cuishuhao/BNM.
Unsupervised Open Domain Recognition by Semantic Discrepancy Minimization
Apr 18, 2019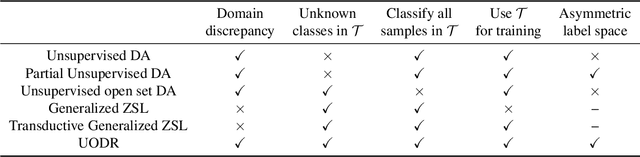
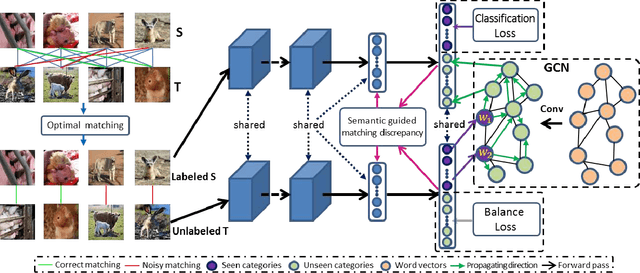

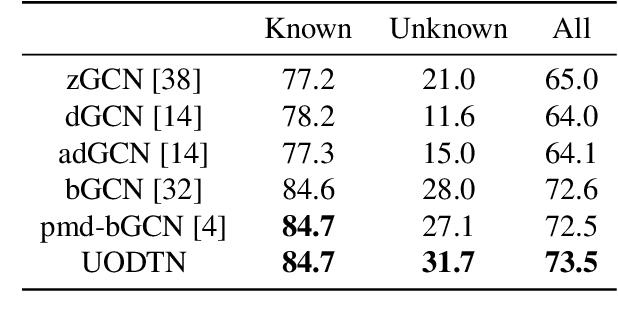
We address the unsupervised open domain recognition (UODR) problem, where categories in labeled source domain S is only a subset of those in unlabeled target domain T. The task is to correctly classify all samples in T including known and unknown categories. UODR is challenging due to the domain discrepancy, which becomes even harder to bridge when a large number of unknown categories exist in T. Moreover, the classification rules propagated by graph CNN (GCN) may be distracted by unknown categories and lack generalization capability. To measure the domain discrepancy for asymmetric label space between S and T, we propose Semantic-Guided Matching Discrepancy (SGMD), which first employs instance matching between S and T, and then the discrepancy is measured by a weighted feature distance between matched instances. We further design a limited balance constraint to achieve a more balanced classification output on known and unknown categories. We develop Unsupervised Open Domain Transfer Network (UODTN), which learns both the backbone classification network and GCN jointly by reducing the SGMD, enforcing the limited balance constraint and minimizing the classification loss on S. UODTN better preserves the semantic structure and enforces the consistency between the learned domain invariant visual features and the semantic embeddings. Experimental results show superiority of our method on recognizing images of both known and unknown categories.