 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Style is Worth One Code: Unlocking Code-to-Style Image Generation with Discrete Style Space
Nov 19, 2025Innovative visual stylization is a cornerstone of artistic creation, yet generating novel and consistent visual styles remains a significant challenge. Existing generative approaches typically rely on lengthy textual prompts, reference images, or parameter-efficient fine-tuning to guide style-aware image generation, but often struggle with style consistency, limited creativity, and complex style representations. In this paper, we affirm that a style is worth one numerical code by introducing the novel task, code-to-style image generation, which produces images with novel, consistent visual styles conditioned solely on a numerical style code. To date, this field has only been primarily explored by the industry (e.g., Midjourney), with no open-source research from the academic community. To fill this gap, we propose CoTyle, the first open-source method for this task. Specifically, we first train a discrete style codebook from a collection of images to extract style embeddings. These embeddings serve as conditions for a text-to-image diffusion model (T2I-DM) to generate stylistic images. Subsequently, we train an autoregressive style generator on the discrete style embeddings to model their distribution, allowing the synthesis of novel style embeddings. During inference, a numerical style code is mapped to a unique style embedding by the style generator, and this embedding guides the T2I-DM to generate images in the corresponding style. Unlike existing methods, our method offers unparalleled simplicity and diversity, unlocking a vast space of reproducible styles from minimal input. Extensive experiments validate that CoTyle effectively turns a numerical code into a style controller, demonstrating a style is worth one code.
Tuning-Free Inversion-Enhanced Control for Consistent Image Editing
Dec 22, 2023Consistent editing of real images is a challenging task, as it requires performing non-rigid edits (e.g., changing postures) to the main objects in the input image without changing their identity or attributes. To guarantee consistent attributes, some existing methods fine-tune the entire model or the textual embedding for structural consistency, but they are time-consuming and fail to perform non-rigid edits. Other works are tuning-free, but their performances are weakened by the quality of Denoising Diffusion Implicit Model (DDIM) reconstruction, which often fails in real-world scenarios. In this paper, we present a novel approach called Tuning-free Inversion-enhanced Control (TIC), which directly correlates features from the inversion process with those from the sampling process to mitigate the inconsistency in DDIM reconstruction. Specifically, our method effectively obtains inversion features from the key and value features in the self-attention layers, and enhances the sampling process by these inversion features, thus achieving accurate reconstruction and content-consistent editing. To extend the applicability of our method to general editing scenarios, we also propose a mask-guided attention concatenation strategy that combines contents from both the inversion and the naive DDIM editing processes. Experiments show that the proposed method outperforms previous works in reconstruction and consistent editing, and produces impressive results in various settings.
Fast Batch Nuclear-norm Maximization and Minimization for Robust Domain Adaptation
Aug 04, 2021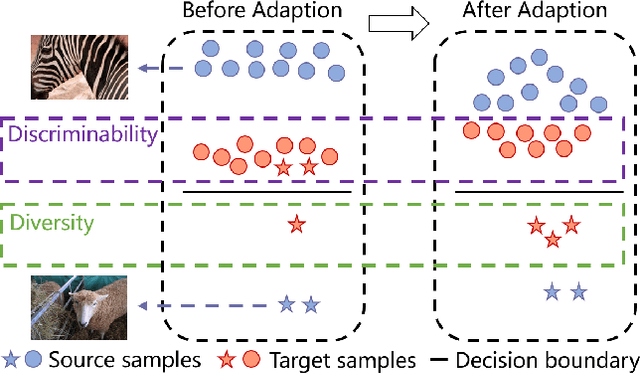
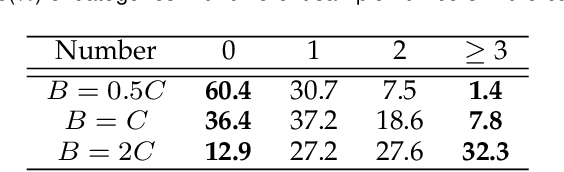
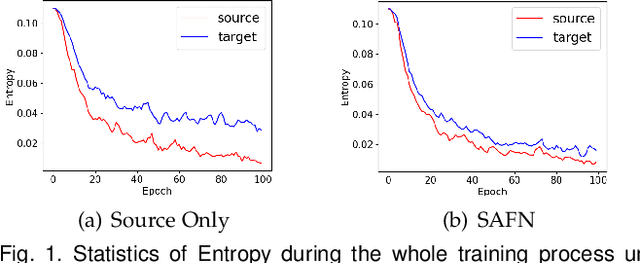
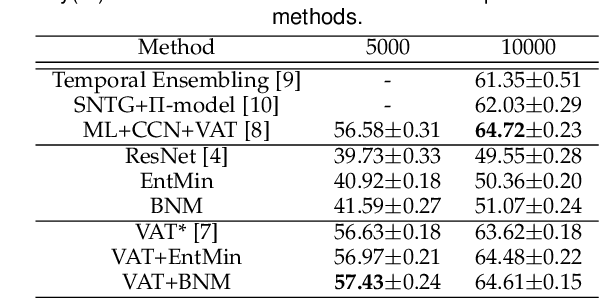
Due to the domain discrepancy in visual domain adaptation, the performance of source model degrades when bumping into the high data density near decision boundary in target domain. A common solution is to minimize the Shannon Entropy to push the decision boundary away from the high density area. However, entropy minimization also leads to severe reduction of prediction diversity, and unfortunately brings harm to the domain adaptation. In this paper, we investigate the prediction discriminability and diversity by studying the structure of the classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. The nuclear-norm is an upperbound of the former, and a convex approximation of the latter. Accordingly, we propose Batch Nuclear-norm Maximization and Minimization, which performs nuclear-norm maximization on the target output matrix to enhance the target prediction ability, and nuclear-norm minimization on the source batch output matrix to increase applicability of the source domain knowledge. We further approximate the nuclear-norm by L_{1,2}-norm, and design multi-batch optimization for stable solution on large number of categories. The fast approximation method achieves O(n^2) computational complexity and better convergence property. Experiments show that our method could boost the adaptation accuracy and robustness under three typical domain adaptation scenarios. The code is available at https://github.com/cuishuhao/BNM.
Learning Invariant Representation with Consistency and Diversity for Semi-supervised Source Hypothesis Transfer
Jul 20, 2021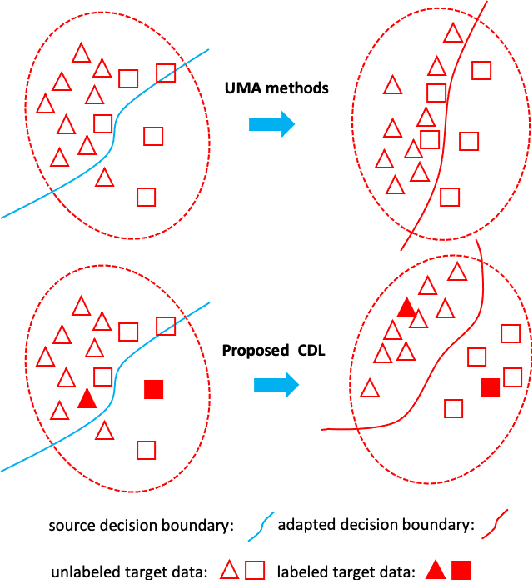

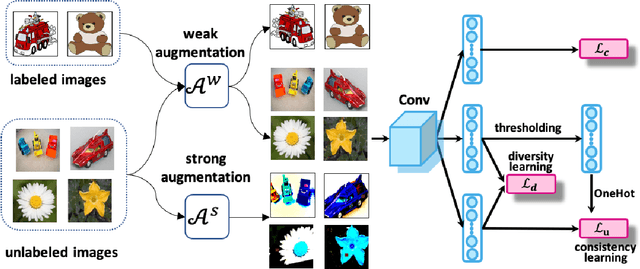
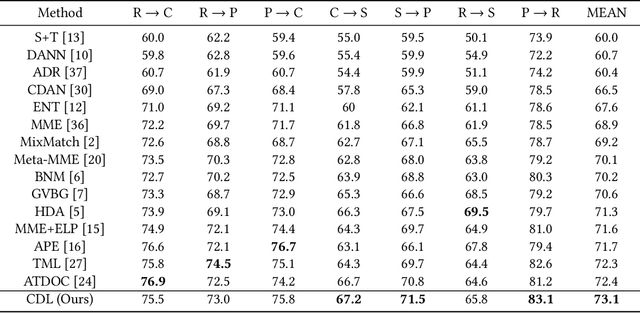
Semi-supervised domain adaptation (SSDA) aims to solve tasks in target domain by utilizing transferable information learned from the available source domain and a few labeled target data. However, source data is not always accessible in practical scenarios, which restricts the application of SSDA in real world circumstances. In this paper, we propose a novel task named Semi-supervised Source Hypothesis Transfer (SSHT), which performs domain adaptation based on source trained model, to generalize well in target domain with a few supervisions. In SSHT, we are facing two challenges: (1) The insufficient labeled target data may result in target features near the decision boundary, with the increased risk of mis-classification; (2) The data are usually imbalanced in source domain, so the model trained with these data is biased. The biased model is prone to categorize samples of minority categories into majority ones, resulting in low prediction diversity. To tackle the above issues, we propose Consistency and Diversity Learning (CDL), a simple but effective framework for SSHT by facilitating prediction consistency between two randomly augmented unlabeled data and maintaining the prediction diversity when adapting model to target domain. Encouraging consistency regularization brings difficulty to memorize the few labeled target data and thus enhances the generalization ability of the learned model. We further integrate Batch Nuclear-norm Maximization into our method to enhance the discriminability and diversity. Experimental results show that our method outperforms existing SSDA methods and unsupervised model adaptation methods on DomainNet, Office-Home and Office-31 datasets. The code is available at https://github.com/Wang-xd1899/SSHT.
Heuristic Domain Adaptation
Nov 30, 2020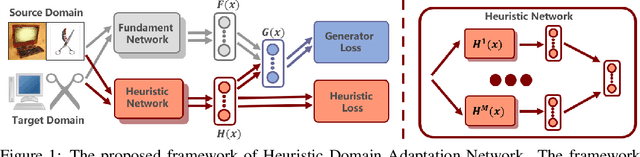
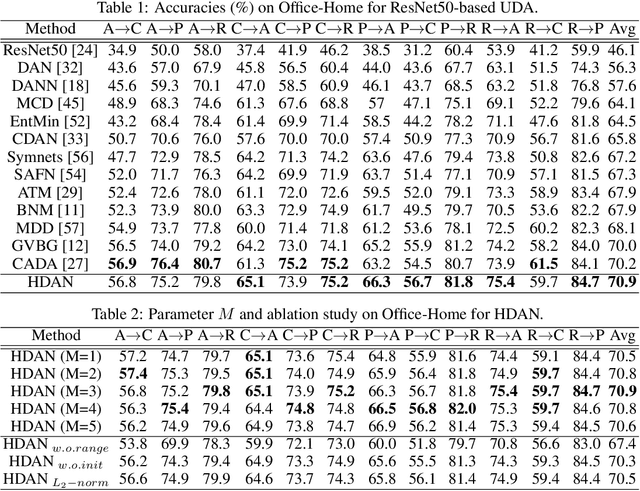
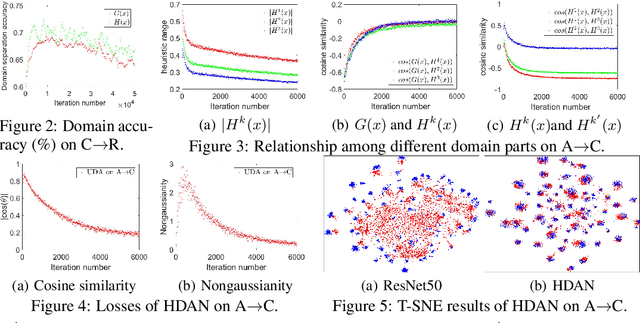
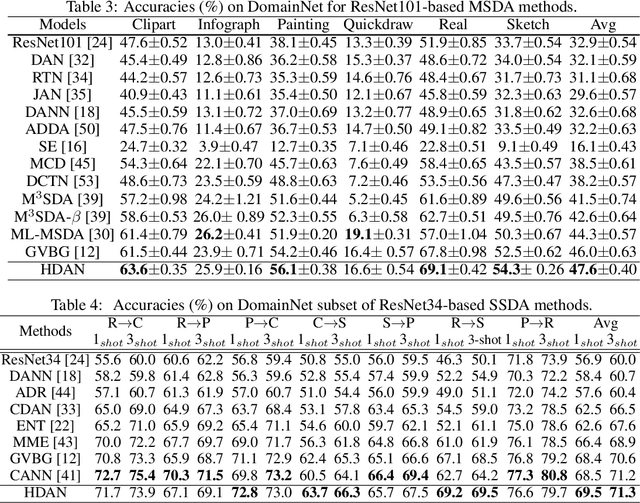
In visual domain adaptation (DA), separating the domain-specific characteristics from the domain-invariant representations is an ill-posed problem. Existing methods apply different kinds of priors or directly minimize the domain discrepancy to address this problem, which lack flexibility in handling real-world situations. Another research pipeline expresses the domain-specific information as a gradual transferring process, which tends to be suboptimal in accurately removing the domain-specific properties. In this paper, we address the modeling of domain-invariant and domain-specific information from the heuristic search perspective. We identify the characteristics in the existing representations that lead to larger domain discrepancy as the heuristic representations. With the guidance of heuristic representations, we formulate a principled framework of Heuristic Domain Adaptation (HDA) with well-founded theoretical guarantees. To perform HDA, the cosine similarity scores and independence measurements between domain-invariant and domain-specific representations are cast into the constraints at the initial and final states during the learning procedure. Similar to the final condition of heuristic search, we further derive a constraint enforcing the final range of heuristic network output to be small. Accordingly, we propose Heuristic Domain Adaptation Network (HDAN), which explicitly learns the domain-invariant and domain-specific representations with the above mentioned constraints. Extensive experiments show that HDAN has exceeded state-of-the-art on unsupervised DA, multi-source DA and semi-supervised DA. The code is available at https://github.com/cuishuhao/HDA.
Gradually Vanishing Bridge for Adversarial Domain Adaptation
Mar 30, 2020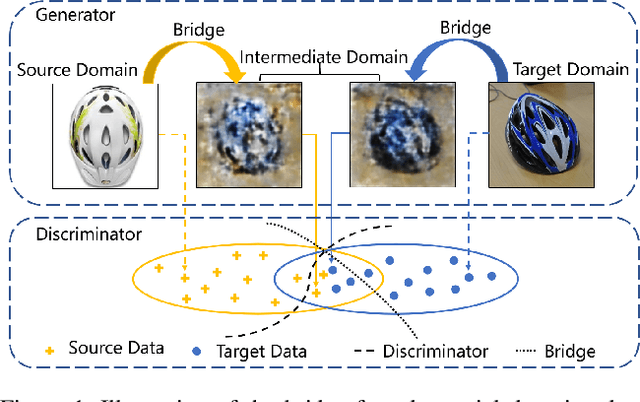
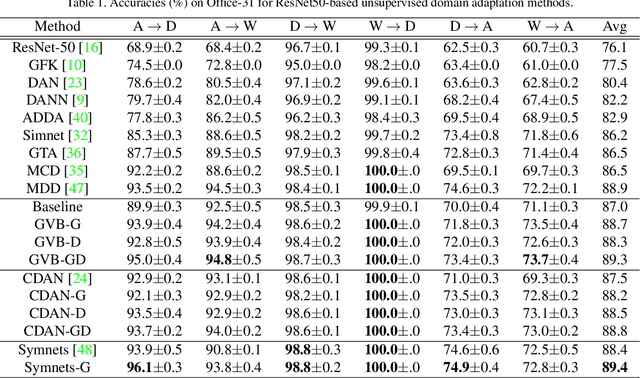
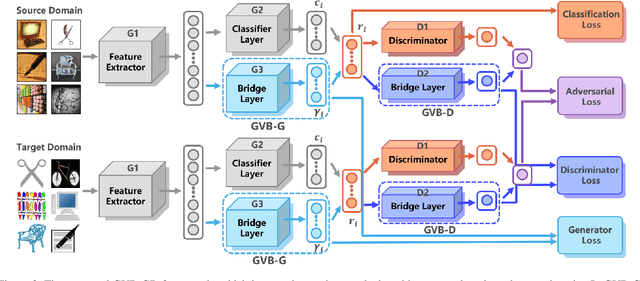
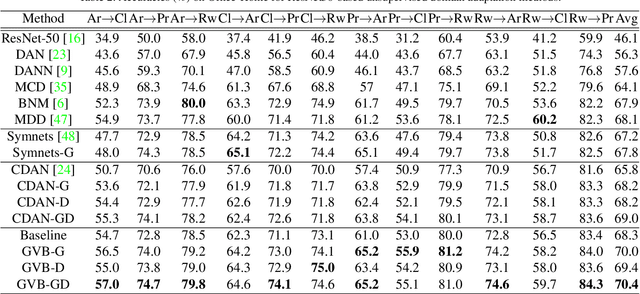
In unsupervised domain adaptation, rich domain-specific characteristics bring great challenge to learn domain-invariant representations. However, domain discrepancy is considered to be directly minimized in existing solutions, which is difficult to achieve in practice. Some methods alleviate the difficulty by explicitly modeling domain-invariant and domain-specific parts in the representations, but the adverse influence of the explicit construction lies in the residual domain-specific characteristics in the constructed domain-invariant representations. In this paper, we equip adversarial domain adaptation with Gradually Vanishing Bridge (GVB) mechanism on both generator and discriminator. On the generator, GVB could not only reduce the overall transfer difficulty, but also reduce the influence of the residual domain-specific characteristics in domain-invariant representations. On the discriminator, GVB contributes to enhance the discriminating ability, and balance the adversarial training process. Experiments on three challenging datasets show that our GVB methods outperform strong competitors, and cooperate well with other adversarial methods. The code is available at https://github.com/cuishuhao/GVB.
Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations
Mar 27, 2020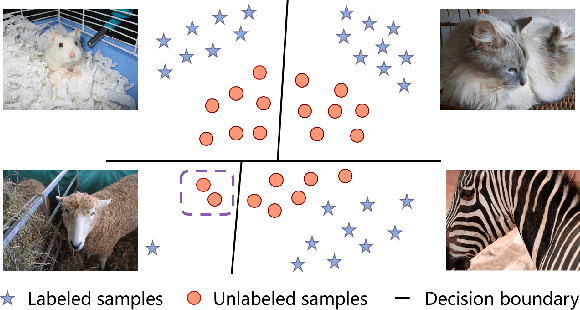
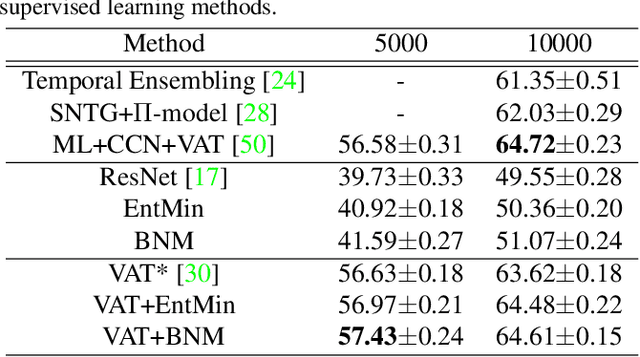
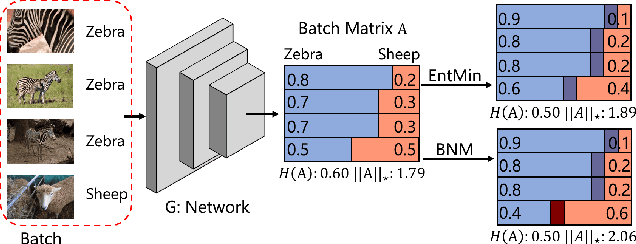
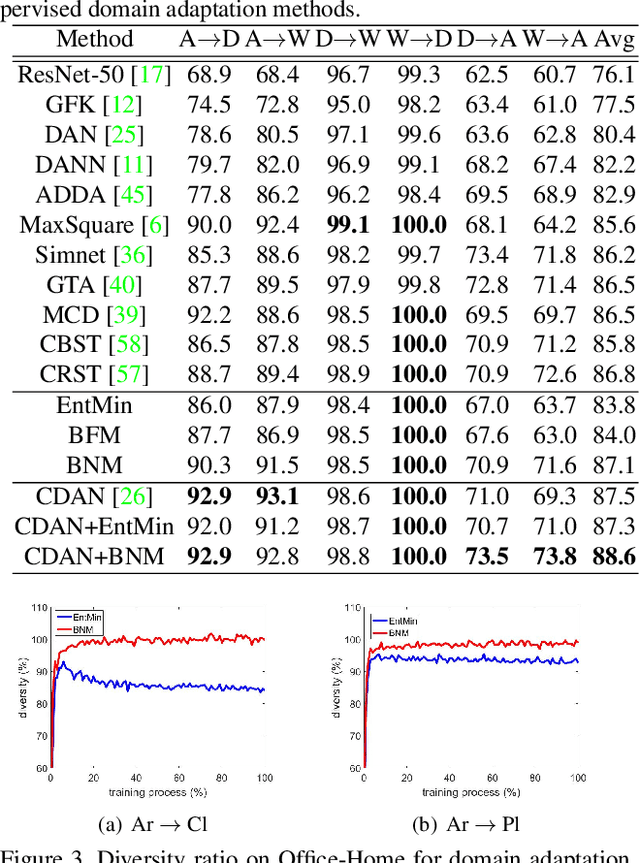
The learning of the deep networks largely relies on the data with human-annotated labels. In some label insufficient situations, the performance degrades on the decision boundary with high data density. A common solution is to directly minimize the Shannon Entropy, but the side effect caused by entropy minimization, i.e., reduction of the prediction diversity, is mostly ignored. To address this issue, we reinvestigate the structure of classification output matrix of a randomly selected data batch. We find by theoretical analysis that the prediction discriminability and diversity could be separately measured by the Frobenius-norm and rank of the batch output matrix. Besides, the nuclear-norm is an upperbound of the Frobenius-norm, and a convex approximation of the matrix rank. Accordingly, to improve both discriminability and diversity, we propose Batch Nuclear-norm Maximization (BNM) on the output matrix. BNM could boost the learning under typical label insufficient learning scenarios, such as semi-supervised learning, domain adaptation and open domain recognition. On these tasks, extensive experimental results show that BNM outperforms competitors and works well with existing well-known methods. The code is available at https://github.com/cuishuhao/BNM.
Unsupervised Open Domain Recognition by Semantic Discrepancy Minimization
Apr 18, 2019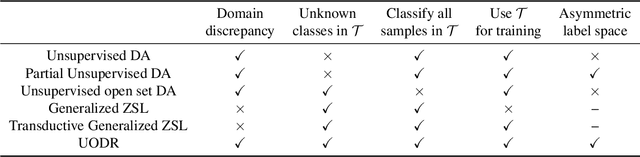
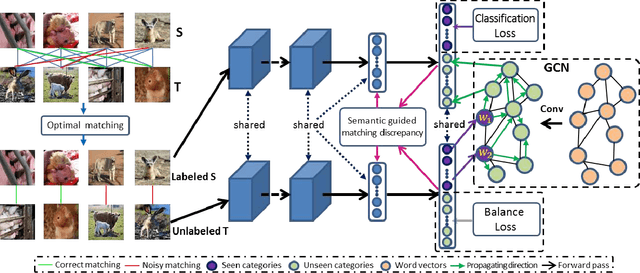

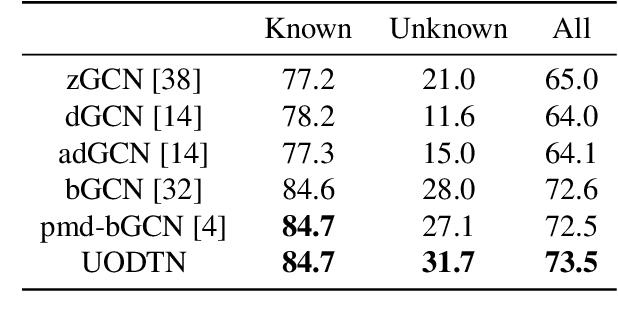
We address the unsupervised open domain recognition (UODR) problem, where categories in labeled source domain S is only a subset of those in unlabeled target domain T. The task is to correctly classify all samples in T including known and unknown categories. UODR is challenging due to the domain discrepancy, which becomes even harder to bridge when a large number of unknown categories exist in T. Moreover, the classification rules propagated by graph CNN (GCN) may be distracted by unknown categories and lack generalization capability. To measure the domain discrepancy for asymmetric label space between S and T, we propose Semantic-Guided Matching Discrepancy (SGMD), which first employs instance matching between S and T, and then the discrepancy is measured by a weighted feature distance between matched instances. We further design a limited balance constraint to achieve a more balanced classification output on known and unknown categories. We develop Unsupervised Open Domain Transfer Network (UODTN), which learns both the backbone classification network and GCN jointly by reducing the SGMD, enforcing the limited balance constraint and minimizing the classification loss on S. UODTN better preserves the semantic structure and enforces the consistency between the learned domain invariant visual features and the semantic embeddings. Experimental results show superiority of our method on recognizing images of both known and unknown categories.