 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAT-HMR: Real-Time Multi-Person 3D Mesh Estimation via Scale-Adaptive Tokens
Nov 29, 2024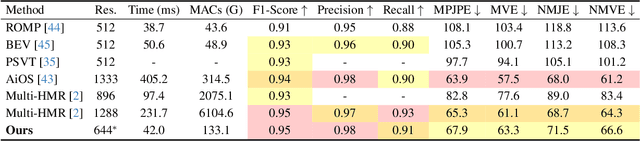
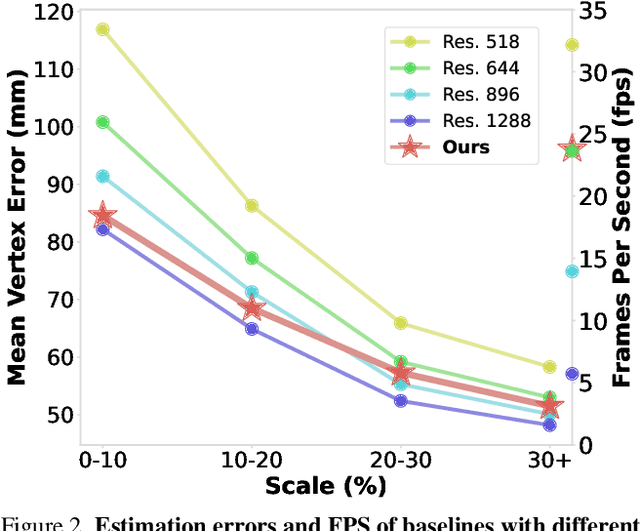
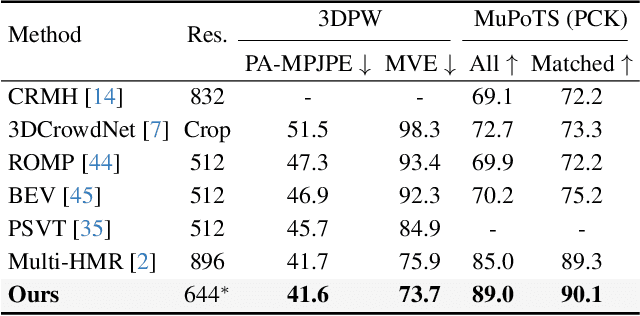
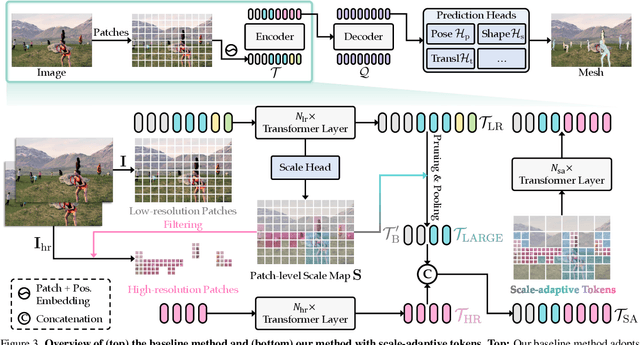
We propose a one-stage framework for real-time multi-person 3D human mesh estimation from a single RGB image. While current one-stage methods, which follow a DETR-style pipeline, achieve state-of-the-art (SOTA) performance with high-resolution inputs, we observe that this particularly benefits the estimation of individuals in smaller scales of the image (e.g., those far from the camera), but at the cost of significantly increased computation overhead. To address this, we introduce scale-adaptive tokens that are dynamically adjusted based on the relative scale of each individual in the image within the DETR framework. Specifically, individuals in smaller scales are processed at higher resolutions, larger ones at lower resolutions, and background regions are further distilled. These scale-adaptive tokens more efficiently encode the image features, facilitating subsequent decoding to regress the human mesh, while allowing the model to allocate computational resources more effectively and focus on more challenging cases. Experiments show that our method preserves the accuracy benefits of high-resolution processing while substantially reducing computational cost, achieving real-time inference with performance comparable to SOTA methods.
Dissecting Multiplication in Transformers: Insights into LLMs
Jul 22, 2024Transformer-based large language models have achieved remarkable performance across various natural language processing tasks. However, they often struggle with seemingly easy tasks like arithmetic despite their vast capabilities. This stark disparity raise human's concerns about their safe and ethical use, hinder their widespread adoption.In this paper, we focus on a typical arithmetic task, integer multiplication, to explore and explain the imperfection of transformers in this domain. We provide comprehensive analysis of a vanilla transformer trained to perform n-digit integer multiplication. Our observations indicate that the model decomposes multiplication task into multiple parallel subtasks, sequentially optimizing each subtask for each digit to complete the final multiplication. Based on observation and analysis, we infer the reasons of transformers deficiencies in multiplication tasks lies in their difficulty in calculating successive carryovers and caching intermediate results, and confirmed this inference through experiments. Guided by these findings, we propose improvements to enhance transformers performance on multiplication tasks. These enhancements are validated through rigorous testing and mathematical modeling, not only enhance transformer's interpretability, but also improve its performance, e.g., we achieve over 99.9% accuracy on 5-digit integer multiplication with a tiny transformer, outperform LLMs GPT-4. Our method contributes to the broader fields of model understanding and interpretability, paving the way for analyzing more complex tasks and Transformer models. This work underscores the importance of explainable AI, helping to build trust in large language models and promoting their adoption in critical applications.
XPose: eXplainable Human Pose Estimation
Mar 19, 2024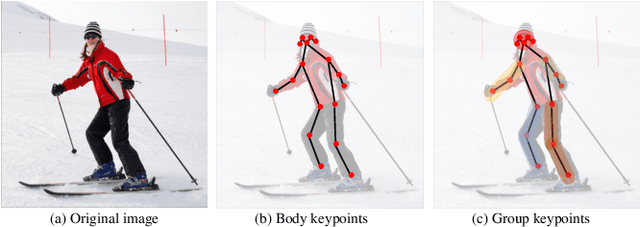
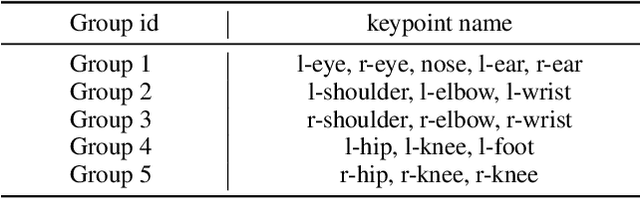
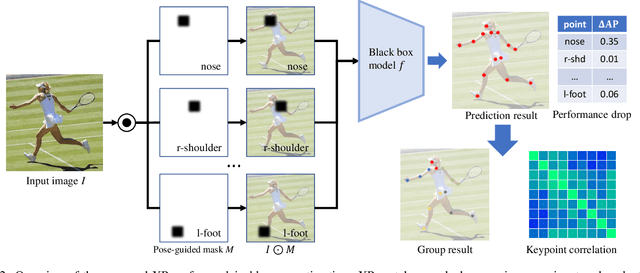
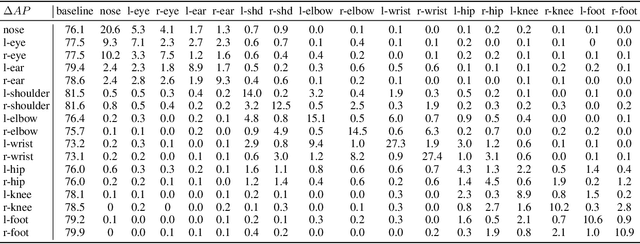
Current approaches in pose estimation primarily concentrate on enhancing model architectures, often overlooking the importance of comprehensively understanding the rationale behind model decisions. In this paper, we propose XPose, a novel framework that incorporates Explainable AI (XAI) principles into pose estimation. This integration aims to elucidate the individual contribution of each keypoint to final prediction, thereby elevating the model's transparency and interpretability. Conventional XAI techniques have predominantly addressed tasks with single-target tasks like classification. Additionally, the application of Shapley value, a common measure in XAI, to pose estimation has been hindered by prohibitive computational demands. To address these challenges, this work introduces an innovative concept called Group Shapley Value (GSV). This approach strategically organizes keypoints into clusters based on their interdependencies. Within these clusters, GSV meticulously calculates Shapley value for keypoints, while for inter-cluster keypoints, it opts for a more holistic group-level valuation. This dual-level computation framework meticulously assesses keypoint contributions to the final outcome, optimizing computational efficiency. Building on the insights into keypoint interactions, we devise a novel data augmentation technique known as Group-based Keypoint Removal (GKR). This method ingeniously removes individual keypoints during training phases, deliberately preserving those with strong mutual connections, thereby refining the model's predictive prowess for non-visible keypoints. The empirical validation of GKR across a spectrum of standard approaches attests to its efficacy. GKR's success demonstrates how using Explainable AI (XAI) can directly enhance pose estimation models.
General Greedy De-bias Learning
Dec 21, 2021
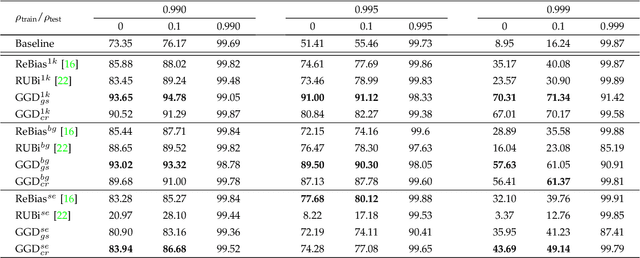
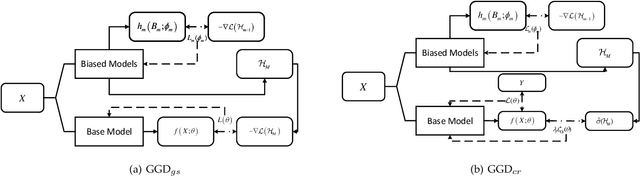
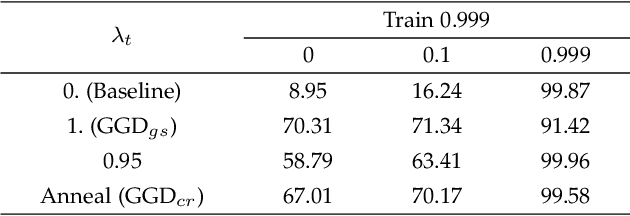
Neural networks often make predictions relying on the spurious correlations from the datasets rather than the intrinsic properties of the task of interest, facing sharp degradation on out-of-distribution (OOD) test data. Existing de-bias learning frameworks try to capture specific dataset bias by bias annotations, they fail to handle complicated OOD scenarios. Others implicitly identify the dataset bias by the special design on the low capability biased model or the loss, but they degrade when the training and testing data are from the same distribution. In this paper, we propose a General Greedy De-bias learning framework (GGD), which greedily trains the biased models and the base model like gradient descent in functional space. It encourages the base model to focus on examples that are hard to solve with biased models, thus remaining robust against spurious correlations in the test stage. GGD largely improves models' OOD generalization ability on various tasks, but sometimes over-estimates the bias level and degrades on the in-distribution test. We further re-analyze the ensemble process of GGD and introduce the Curriculum Regularization into GGD inspired by curriculum learning, which achieves a good trade-off between in-distribution and out-of-distribution performance. Extensive experiments on image classification, adversarial question answering, and visual question answering demonstrate the effectiveness of our method. GGD can learn a more robust base model under the settings of both task-specific biased models with prior knowledge and self-ensemble biased model without prior knowledge.
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Nov 23, 2021
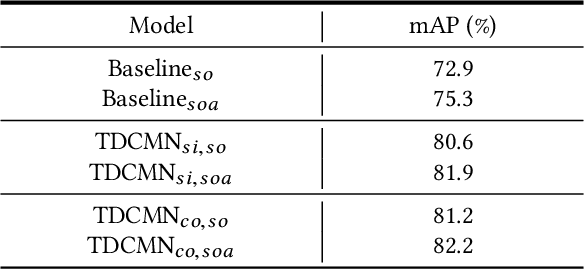
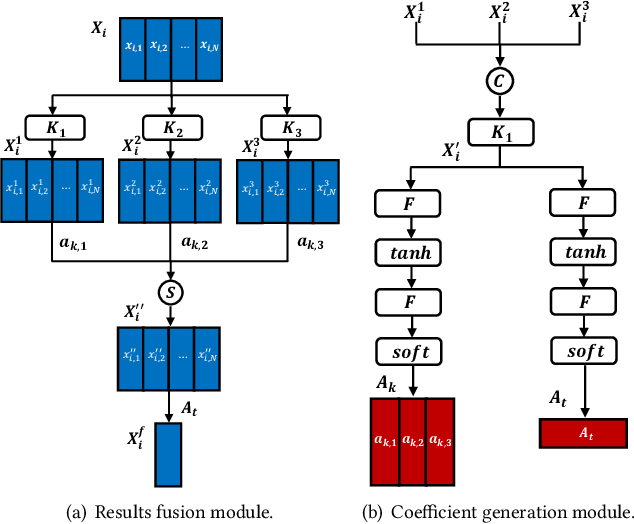
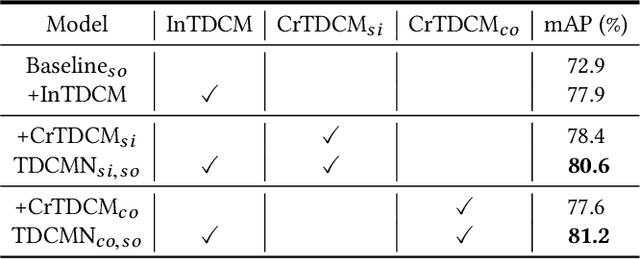
Event analysis in untrimmed videos has attracted increasing attention due to the application of cutting-edge techniques such as CNN. As a well studied property for CNN-based models, the receptive field is a measurement for measuring the spatial range covered by a single feature response, which is crucial in improving the image categorization accuracy. In video domain, video event semantics are actually described by complex interaction among different concepts, while their behaviors vary drastically from one video to another, leading to the difficulty in concept-based analytics for accurate event categorization. To model the concept behavior, we study temporal concept receptive field of concept-based event representation, which encodes the temporal occurrence pattern of different mid-level concepts. Accordingly, we introduce temporal dynamic convolution (TDC) to give stronger flexibility to concept-based event analytics. TDC can adjust the temporal concept receptive field size dynamically according to different inputs. Notably, a set of coefficients are learned to fuse the results of multiple convolutions with different kernel widths that provide various temporal concept receptive field sizes. Different coefficients can generate appropriate and accurate temporal concept receptive field size according to input videos and highlight crucial concepts. Based on TDC, we propose the temporal dynamic concept modeling network (TDCMN) to learn an accurate and complete concept representation for efficient untrimmed video analysis. Experiment results on FCVID and ActivityNet show that TDCMN demonstrates adaptive event recognition ability conditioned on different inputs, and improve the event recognition performance of Concept-based methods by a large margin. Code is available at https://github.com/qzhb/TDCMN.
Self-Regulated Learning for Egocentric Video Activity Anticipation
Nov 23, 2021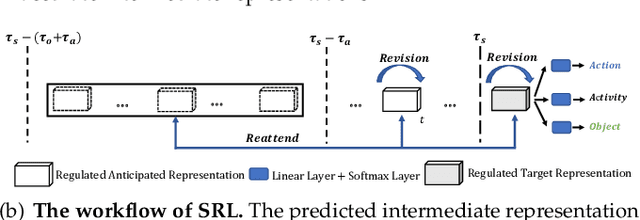
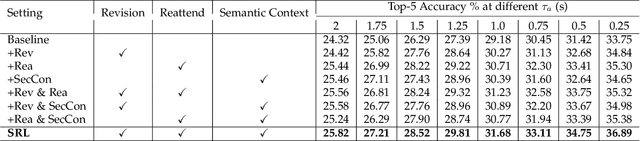
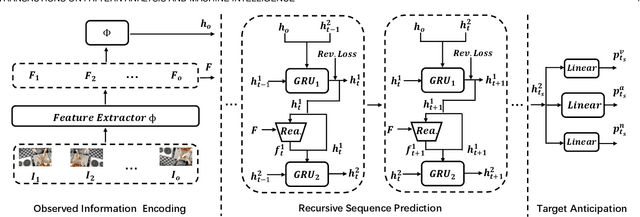
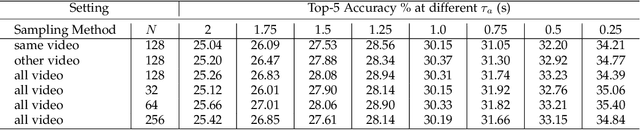
Future activity anticipation is a challenging problem in egocentric vision. As a standard future activity anticipation paradigm, recursive sequence prediction suffers from the accumulation of errors. To address this problem, we propose a simple and effective Self-Regulated Learning framework, which aims to regulate the intermediate representation consecutively to produce representation that (a) emphasizes the novel information in the frame of the current time-stamp in contrast to previously observed content, and (b) reflects its correlation with previously observed frames. The former is achieved by minimizing a contrastive loss, and the latter can be achieved by a dynamic reweighing mechanism to attend to informative frames in the observed content with a similarity comparison between feature of the current frame and observed frames. The learned final video representation can be further enhanced by multi-task learning which performs joint feature learning on the target activity labels and the automatically detected action and object class tokens. SRL sharply outperforms existing state-of-the-art in most cases on two egocentric video datasets and two third-person video datasets. Its effectiveness is also verified by the experimental fact that the action and object concepts that support the activity semantics can be accurately identified.
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 23, 2021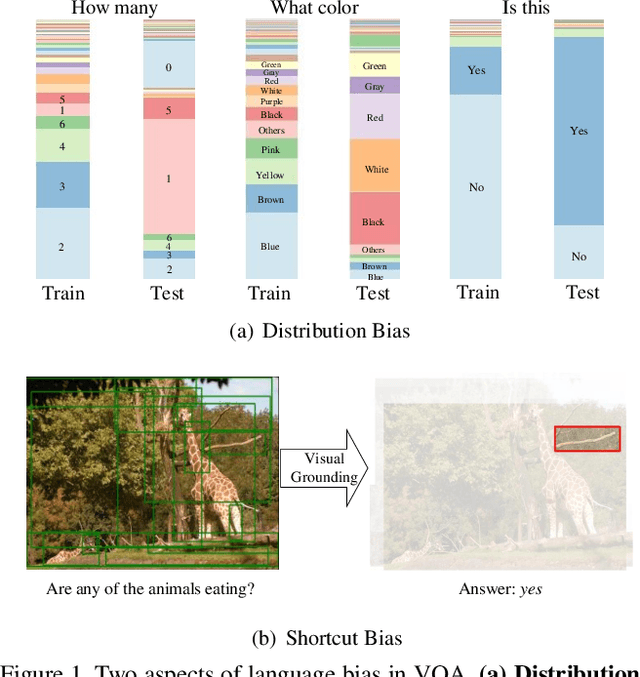
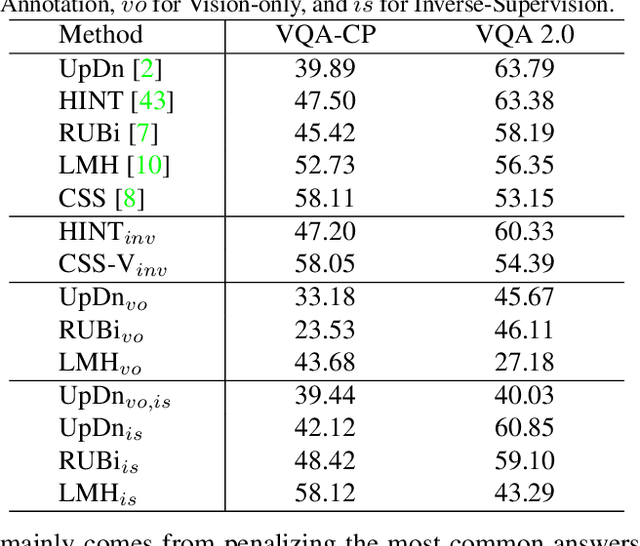
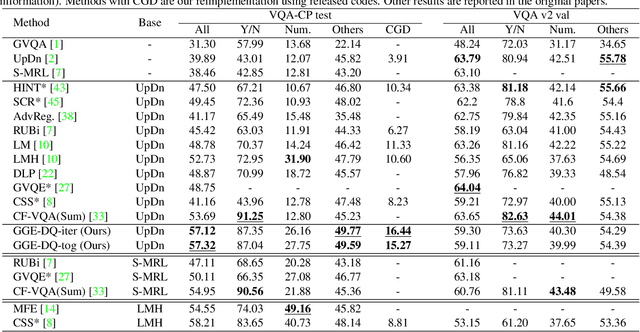
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.
Label Decoupling Framework for Salient Object Detection
Aug 25, 2020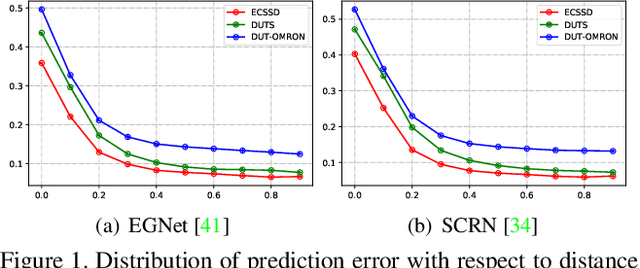
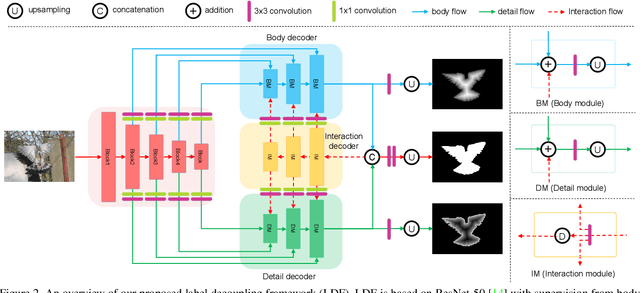
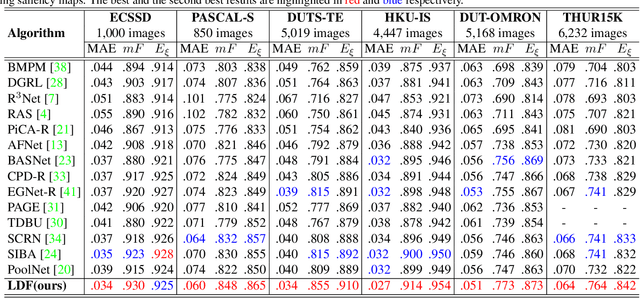

To get more accurate saliency maps, recent methods mainly focus on aggregating multi-level features from fully convolutional network (FCN) and introducing edge information as auxiliary supervision. Though remarkable progress has been achieved, we observe that the closer the pixel is to the edge, the more difficult it is to be predicted, because edge pixels have a very imbalance distribution. To address this problem, we propose a label decoupling framework (LDF) which consists of a label decoupling (LD) procedure and a feature interaction network (FIN). LD explicitly decomposes the original saliency map into body map and detail map, where body map concentrates on center areas of objects and detail map focuses on regions around edges. Detail map works better because it involves much more pixels than traditional edge supervision. Different from saliency map, body map discards edge pixels and only pays attention to center areas. This successfully avoids the distraction from edge pixels during training. Therefore, we employ two branches in FIN to deal with body map and detail map respectively. Feature interaction (FI) is designed to fuse the two complementary branches to predict the saliency map, which is then used to refine the two branches again. This iterative refinement is helpful for learning better representations and more precise saliency maps. Comprehensive experiments on six benchmark datasets demonstrate that LDF outperforms state-of-the-art approaches on different evaluation metrics.
Correlating Edge, Pose with Parsing
May 04, 2020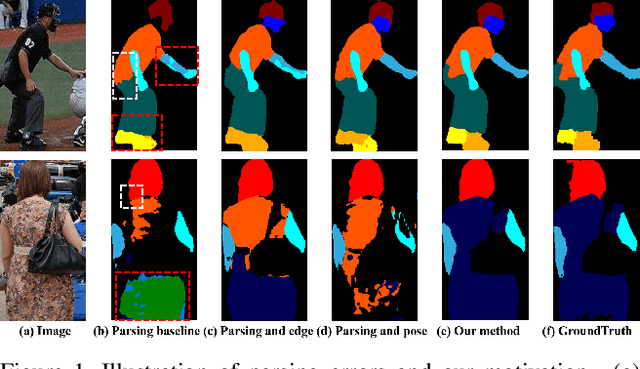
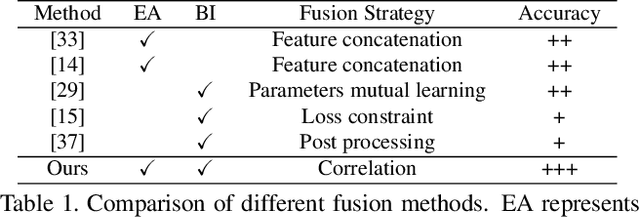
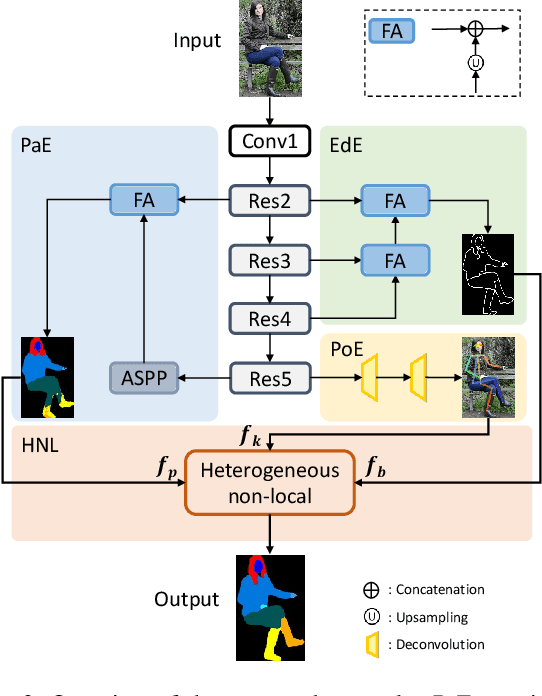
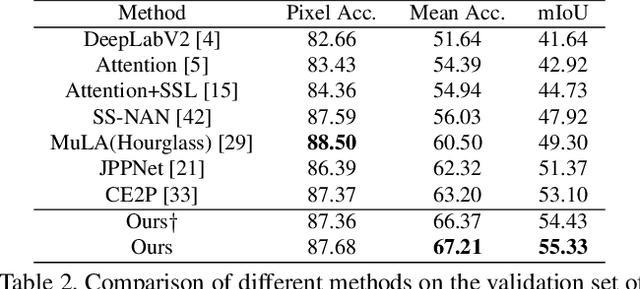
According to existing studies, human body edge and pose are two beneficial factors to human parsing. The effectiveness of each of the high-level features (edge and pose) is confirmed through the concatenation of their features with the parsing features. Driven by the insights, this paper studies how human semantic boundaries and keypoint locations can jointly improve human parsing. Compared with the existing practice of feature concatenation, we find that uncovering the correlation among the three factors is a superior way of leveraging the pivotal contextual cues provided by edges and poses. To capture such correlations, we propose a Correlation Parsing Machine (CorrPM) employing a heterogeneous non-local block to discover the spatial affinity among feature maps from the edge, pose and parsing. The proposed CorrPM allows us to report new state-of-the-art accuracy on three human parsing datasets. Importantly, comparative studies confirm the advantages of feature correlation over the concatenation.
Gradually Vanishing Bridge for Adversarial Domain Adaptation
Mar 30, 2020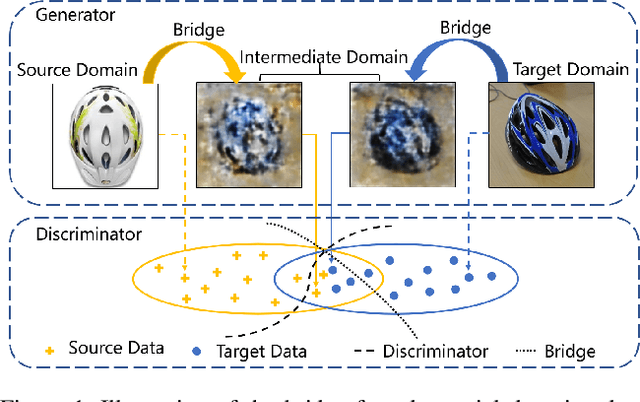
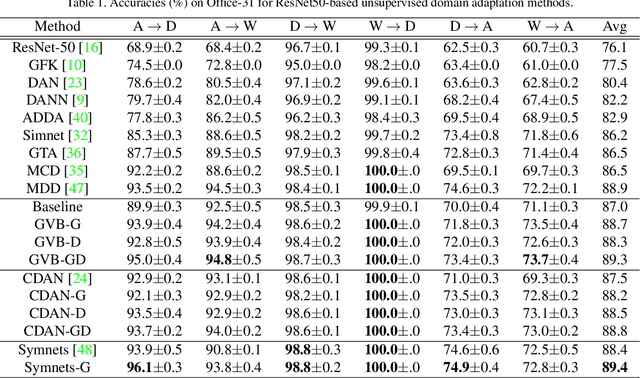
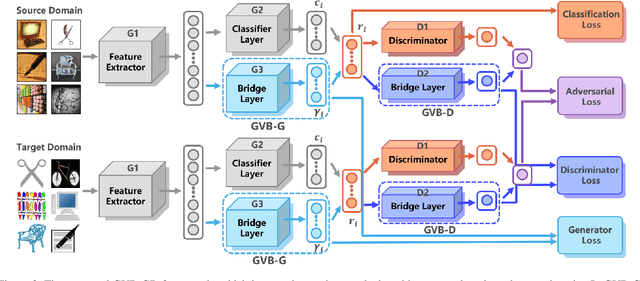
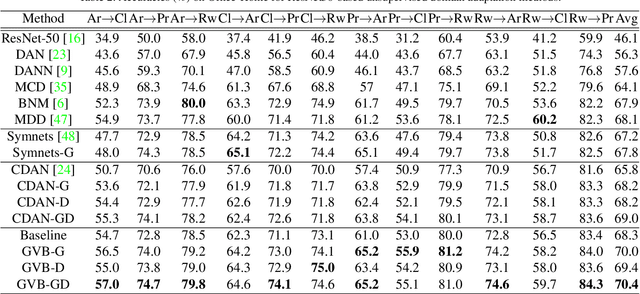
In unsupervised domain adaptation, rich domain-specific characteristics bring great challenge to learn domain-invariant representations. However, domain discrepancy is considered to be directly minimized in existing solutions, which is difficult to achieve in practice. Some methods alleviate the difficulty by explicitly modeling domain-invariant and domain-specific parts in the representations, but the adverse influence of the explicit construction lies in the residual domain-specific characteristics in the constructed domain-invariant representations. In this paper, we equip adversarial domain adaptation with Gradually Vanishing Bridge (GVB) mechanism on both generator and discriminator. On the generator, GVB could not only reduce the overall transfer difficulty, but also reduce the influence of the residual domain-specific characteristics in domain-invariant representations. On the discriminator, GVB contributes to enhance the discriminating ability, and balance the adversarial training process. Experiments on three challenging datasets show that our GVB methods outperform strong competitors, and cooperate well with other adversarial methods. The code is available at https://github.com/cuishuhao/GVB.