 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA-Bench: Do Vision-Language Models Really Understand Visualized Text as Well as Pure Text?
Feb 04, 2026Vision-Language Models (VLMs) have achieved impressive performance in cross-modal understanding across textual and visual inputs, yet existing benchmarks predominantly focus on pure-text queries. In real-world scenarios, language also frequently appears as visualized text embedded in images, raising the question of whether current VLMs handle such input requests comparably. We introduce VISTA-Bench, a systematic benchmark from multimodal perception, reasoning, to unimodal understanding domains. It evaluates visualized text understanding by contrasting pure-text and visualized-text questions under controlled rendering conditions. Extensive evaluation of over 20 representative VLMs reveals a pronounced modality gap: models that perform well on pure-text queries often degrade substantially when equivalent semantic content is presented as visualized text. This gap is further amplified by increased perceptual difficulty, highlighting sensitivity to rendering variations despite unchanged semantics. Overall, VISTA-Bench provides a principled evaluation framework to diagnose this limitation and to guide progress toward more unified language representations across tokenized text and pixels. The source dataset is available at https://github.com/QingAnLiu/VISTA-Bench.
Divide-and-Conquer: Tree-structured Strategy with Answer Distribution Estimator for Goal-Oriented Visual Dialogue
Feb 09, 2025Goal-oriented visual dialogue involves multi-round interaction between artificial agents, which has been of remarkable attention due to its wide applications. Given a visual scene, this task occurs when a Questioner asks an action-oriented question and an Answerer responds with the intent of letting the Questioner know the correct action to take. The quality of questions affects the accuracy and efficiency of the target search progress. However, existing methods lack a clear strategy to guide the generation of questions, resulting in the randomness in the search process and inconvergent results. We propose a Tree-Structured Strategy with Answer Distribution Estimator (TSADE) which guides the question generation by excluding half of the current candidate objects in each round. The above process is implemented by maximizing a binary reward inspired by the ``divide-and-conquer'' paradigm. We further design a candidate-minimization reward which encourages the model to narrow down the scope of candidate objects toward the end of the dialogue. We experimentally demonstrate that our method can enable the agents to achieve high task-oriented accuracy with fewer repeating questions and rounds compared to traditional ergodic question generation approaches. Qualitative results further show that TSADE facilitates agents to generate higher-quality questions.
Open-Set Knowledge-Based Visual Question Answering with Inference Paths
Oct 12, 2023



Given an image and an associated textual question, the purpose of Knowledge-Based Visual Question Answering (KB-VQA) is to provide a correct answer to the question with the aid of external knowledge bases. Prior KB-VQA models are usually formulated as a retriever-classifier framework, where a pre-trained retriever extracts textual or visual information from knowledge graphs and then makes a prediction among the candidates. Despite promising progress, there are two drawbacks with existing models. Firstly, modeling question-answering as multi-class classification limits the answer space to a preset corpus and lacks the ability of flexible reasoning. Secondly, the classifier merely consider "what is the answer" without "how to get the answer", which cannot ground the answer to explicit reasoning paths. In this paper, we confront the challenge of \emph{explainable open-set} KB-VQA, where the system is required to answer questions with entities at wild and retain an explainable reasoning path. To resolve the aforementioned issues, we propose a new retriever-ranker paradigm of KB-VQA, Graph pATH rankER (GATHER for brevity). Specifically, it contains graph constructing, pruning, and path-level ranking, which not only retrieves accurate answers but also provides inference paths that explain the reasoning process. To comprehensively evaluate our model, we reformulate the benchmark dataset OK-VQA with manually corrected entity-level annotations and release it as ConceptVQA. Extensive experiments on real-world questions demonstrate that our framework is not only able to perform open-set question answering across the whole knowledge base but provide explicit reasoning path.
Stable Attribute Group Editing for Reliable Few-shot Image Generation
Feb 01, 2023



Few-shot image generation aims to generate data of an unseen category based on only a few samples. Apart from basic content generation, a bunch of downstream applications hopefully benefit from this task, such as low-data detection and few-shot classification. To achieve this goal, the generated images should guarantee category retention for classification beyond the visual quality and diversity. In our preliminary work, we present an ``editing-based'' framework Attribute Group Editing (AGE) for reliable few-shot image generation, which largely improves the generation performance. Nevertheless, AGE's performance on downstream classification is not as satisfactory as expected. This paper investigates the class inconsistency problem and proposes Stable Attribute Group Editing (SAGE) for more stable class-relevant image generation. SAGE takes use of all given few-shot images and estimates a class center embedding based on the category-relevant attribute dictionary. Meanwhile, according to the projection weights on the category-relevant attribute dictionary, we can select category-irrelevant attributes from the similar seen categories. Consequently, SAGE injects the whole distribution of the novel class into StyleGAN's latent space, thus largely remains the category retention and stability of the generated images. Going one step further, we find that class inconsistency is a common problem in GAN-generated images for downstream classification. Even though the generated images look photo-realistic and requires no category-relevant editing, they are usually of limited help for downstream classification. We systematically discuss this issue from both the generative model and classification model perspectives, and propose to boost the downstream classification performance of SAGE by enhancing the pixel and frequency components.
Automatic Relation-aware Graph Network Proliferation
May 31, 2022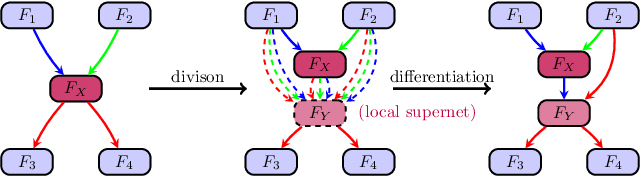

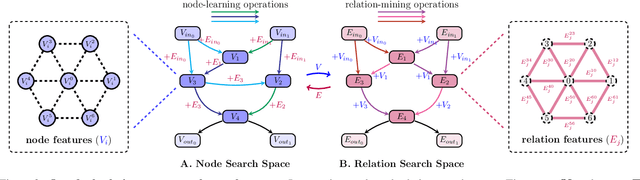
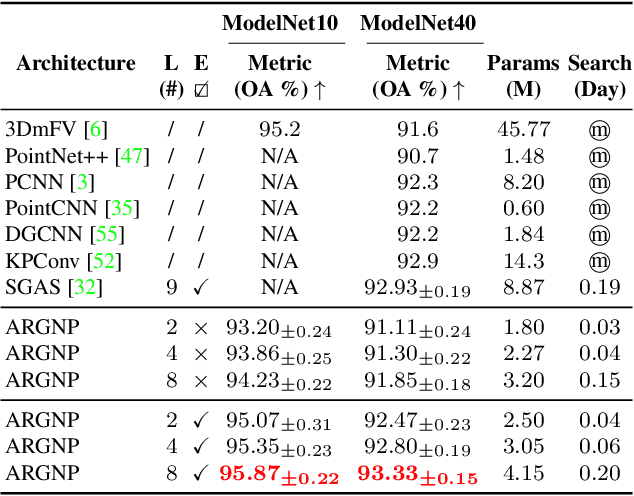
Graph neural architecture search has sparked much attention as Graph Neural Networks (GNNs) have shown powerful reasoning capability in many relational tasks. However, the currently used graph search space overemphasizes learning node features and neglects mining hierarchical relational information. Moreover, due to diverse mechanisms in the message passing, the graph search space is much larger than that of CNNs. This hinders the straightforward application of classical search strategies for exploring complicated graph search space. We propose Automatic Relation-aware Graph Network Proliferation (ARGNP) for efficiently searching GNNs with a relation-guided message passing mechanism. Specifically, we first devise a novel dual relation-aware graph search space that comprises both node and relation learning operations. These operations can extract hierarchical node/relational information and provide anisotropic guidance for message passing on a graph. Second, analogous to cell proliferation, we design a network proliferation search paradigm to progressively determine the GNN architectures by iteratively performing network division and differentiation. The experiments on six datasets for four graph learning tasks demonstrate that GNNs produced by our method are superior to the current state-of-the-art hand-crafted and search-based GNNs. Codes are available at https://github.com/phython96/ARGNP.
Attribute Group Editing for Reliable Few-shot Image Generation
Mar 16, 2022
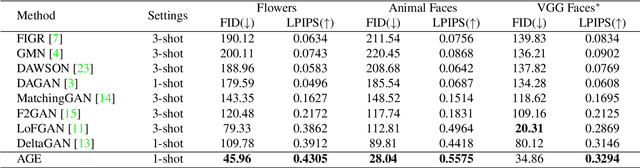
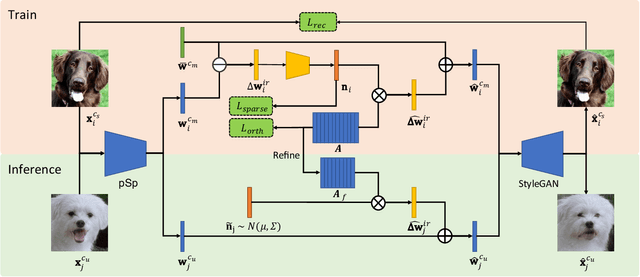
Few-shot image generation is a challenging task even using the state-of-the-art Generative Adversarial Networks (GANs). Due to the unstable GAN training process and the limited training data, the generated images are often of low quality and low diversity. In this work, we propose a new editing-based method, i.e., Attribute Group Editing (AGE), for few-shot image generation. The basic assumption is that any image is a collection of attributes and the editing direction for a specific attribute is shared across all categories. AGE examines the internal representation learned in GANs and identifies semantically meaningful directions. Specifically, the class embedding, i.e., the mean vector of the latent codes from a specific category, is used to represent the category-relevant attributes, and the category-irrelevant attributes are learned globally by Sparse Dictionary Learning on the difference between the sample embedding and the class embedding. Given a GAN well trained on seen categories, diverse images of unseen categories can be synthesized through editing category-irrelevant attributes while keeping category-relevant attributes unchanged. Without re-training the GAN, AGE is capable of not only producing more realistic and diverse images for downstream visual applications with limited data but achieving controllable image editing with interpretable category-irrelevant directions.
General Greedy De-bias Learning
Dec 21, 2021
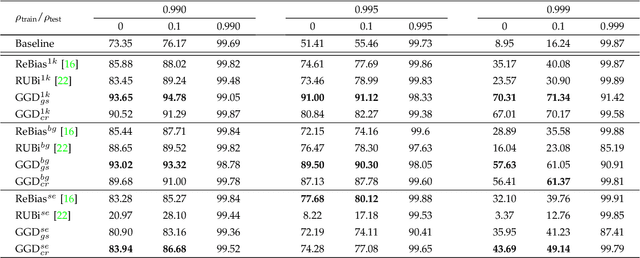
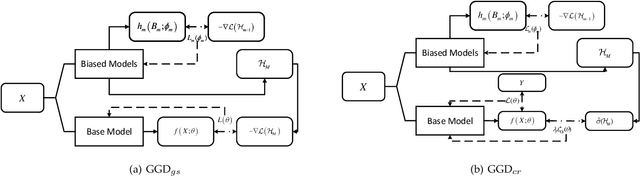
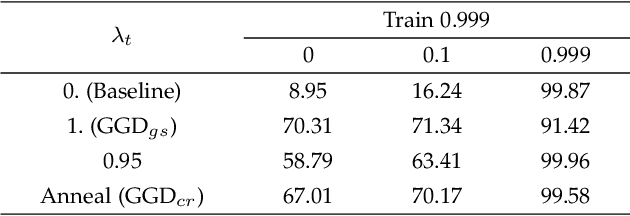
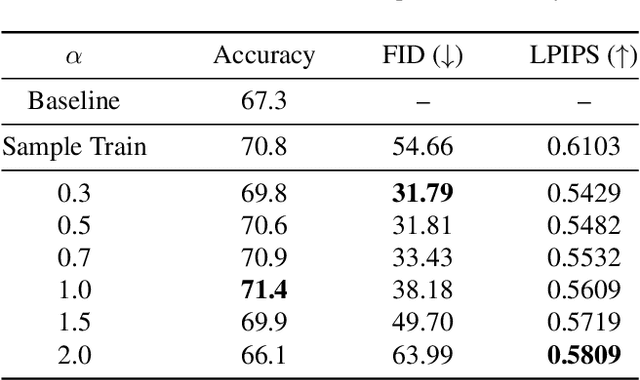
Neural networks often make predictions relying on the spurious correlations from the datasets rather than the intrinsic properties of the task of interest, facing sharp degradation on out-of-distribution (OOD) test data. Existing de-bias learning frameworks try to capture specific dataset bias by bias annotations, they fail to handle complicated OOD scenarios. Others implicitly identify the dataset bias by the special design on the low capability biased model or the loss, but they degrade when the training and testing data are from the same distribution. In this paper, we propose a General Greedy De-bias learning framework (GGD), which greedily trains the biased models and the base model like gradient descent in functional space. It encourages the base model to focus on examples that are hard to solve with biased models, thus remaining robust against spurious correlations in the test stage. GGD largely improves models' OOD generalization ability on various tasks, but sometimes over-estimates the bias level and degrades on the in-distribution test. We further re-analyze the ensemble process of GGD and introduce the Curriculum Regularization into GGD inspired by curriculum learning, which achieves a good trade-off between in-distribution and out-of-distribution performance. Extensive experiments on image classification, adversarial question answering, and visual question answering demonstrate the effectiveness of our method. GGD can learn a more robust base model under the settings of both task-specific biased models with prior knowledge and self-ensemble biased model without prior knowledge.
Edge-featured Graph Neural Architecture Search
Sep 03, 2021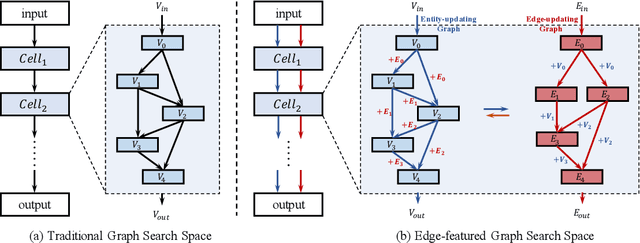

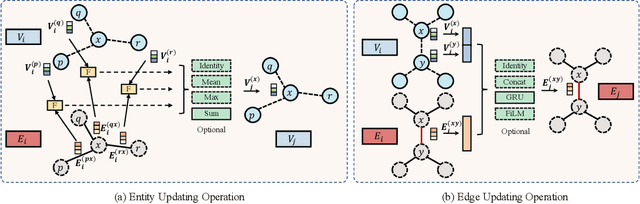
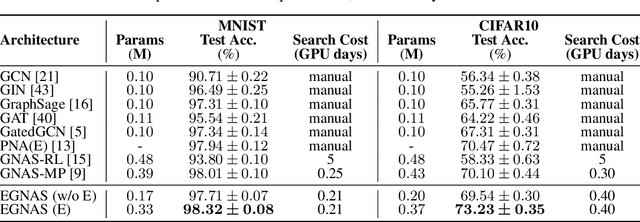
Graph neural networks (GNNs) have been successfully applied to learning representation on graphs in many relational tasks. Recently, researchers study neural architecture search (NAS) to reduce the dependence of human expertise and explore better GNN architectures, but they over-emphasize entity features and ignore latent relation information concealed in the edges. To solve this problem, we incorporate edge features into graph search space and propose Edge-featured Graph Neural Architecture Search to find the optimal GNN architecture. Specifically, we design rich entity and edge updating operations to learn high-order representations, which convey more generic message passing mechanisms. Moreover, the architecture topology in our search space allows to explore complex feature dependence of both entities and edges, which can be efficiently optimized by differentiable search strategy. Experiments at three graph tasks on six datasets show EGNAS can search better GNNs with higher performance than current state-of-the-art human-designed and searched-based GNNs.
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 23, 2021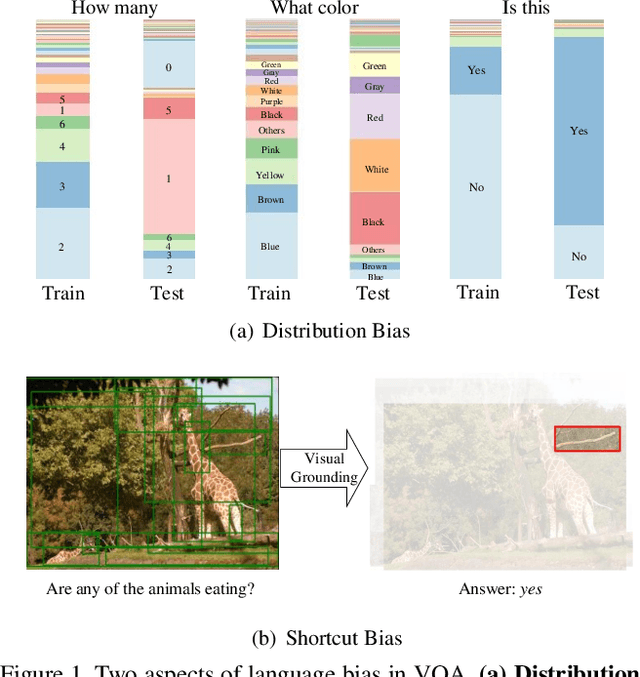
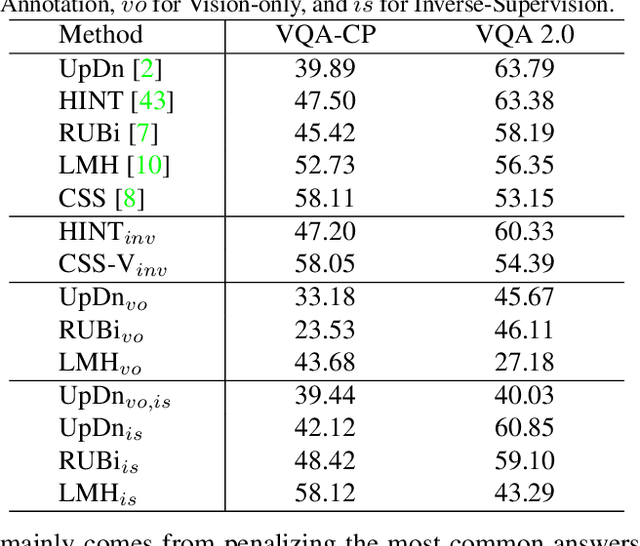
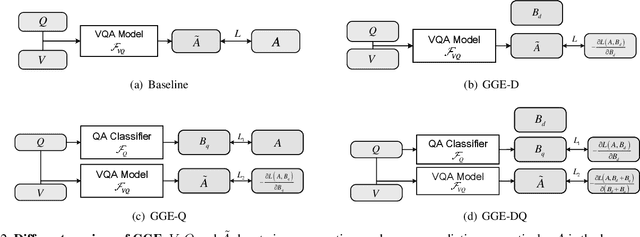
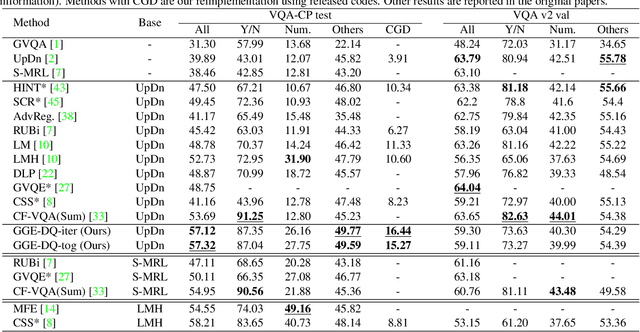
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.