 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025



The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
InfiAlign: A Scalable and Sample-Efficient Framework for Aligning LLMs to Enhance Reasoning Capabilities
Aug 07, 2025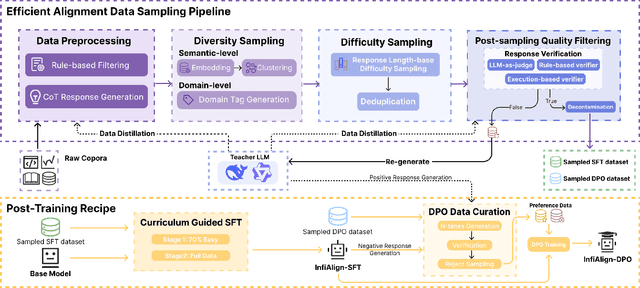
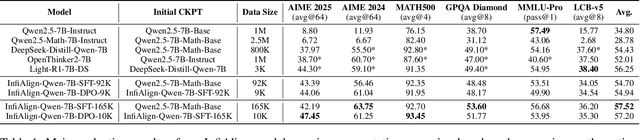
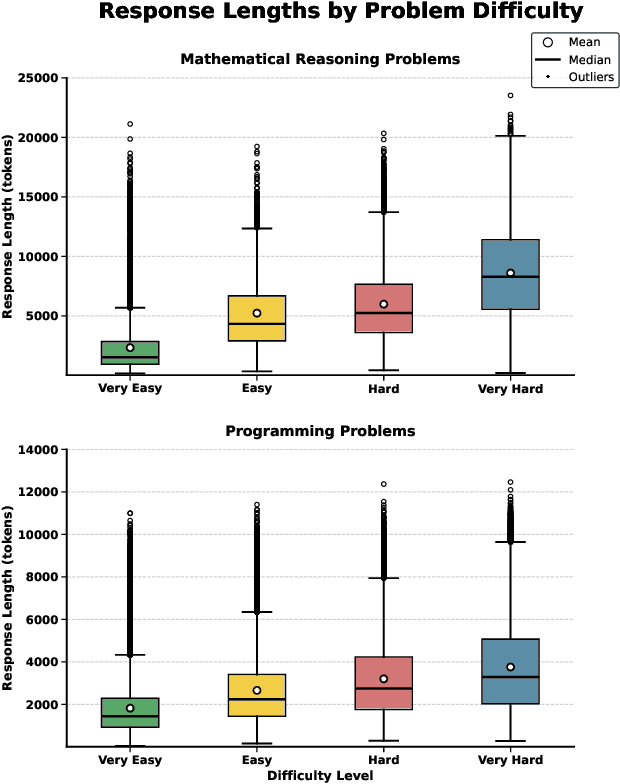
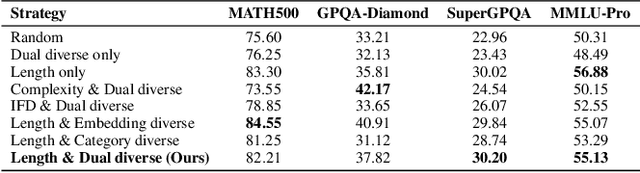
Large language models (LLMs) have exhibited impressive reasoning abilities on a wide range of complex tasks. However, enhancing these capabilities through post-training remains resource intensive, particularly in terms of data and computational cost. Although recent efforts have sought to improve sample efficiency through selective data curation, existing methods often rely on heuristic or task-specific strategies that hinder scalability. In this work, we introduce InfiAlign, a scalable and sample-efficient post-training framework that integrates supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to align LLMs for enhanced reasoning. At the core of InfiAlign is a robust data selection pipeline that automatically curates high-quality alignment data from open-source reasoning datasets using multidimensional quality metrics. This pipeline enables significant performance gains while drastically reducing data requirements and remains extensible to new data sources. When applied to the Qwen2.5-Math-7B-Base model, our SFT model achieves performance on par with DeepSeek-R1-Distill-Qwen-7B, while using only approximately 12% of the training data, and demonstrates strong generalization across diverse reasoning tasks. Additional improvements are obtained through the application of DPO, with particularly notable gains in mathematical reasoning tasks. The model achieves an average improvement of 3.89% on AIME 24/25 benchmarks. Our results highlight the effectiveness of combining principled data selection with full-stage post-training, offering a practical solution for aligning large reasoning models in a scalable and data-efficient manner. The model checkpoints are available at https://huggingface.co/InfiX-ai/InfiAlign-Qwen-7B-SFT.
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025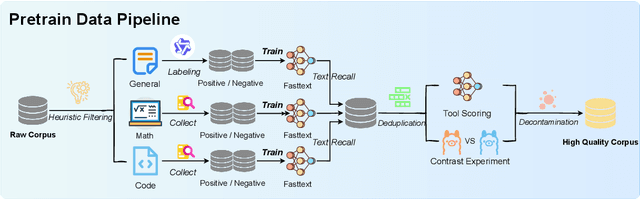

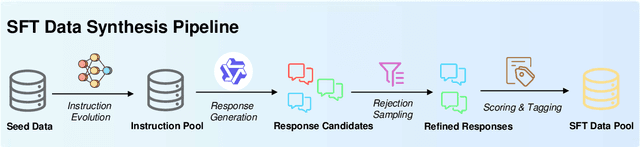

Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.
Divide-and-Conquer: Tree-structured Strategy with Answer Distribution Estimator for Goal-Oriented Visual Dialogue
Feb 09, 2025Goal-oriented visual dialogue involves multi-round interaction between artificial agents, which has been of remarkable attention due to its wide applications. Given a visual scene, this task occurs when a Questioner asks an action-oriented question and an Answerer responds with the intent of letting the Questioner know the correct action to take. The quality of questions affects the accuracy and efficiency of the target search progress. However, existing methods lack a clear strategy to guide the generation of questions, resulting in the randomness in the search process and inconvergent results. We propose a Tree-Structured Strategy with Answer Distribution Estimator (TSADE) which guides the question generation by excluding half of the current candidate objects in each round. The above process is implemented by maximizing a binary reward inspired by the ``divide-and-conquer'' paradigm. We further design a candidate-minimization reward which encourages the model to narrow down the scope of candidate objects toward the end of the dialogue. We experimentally demonstrate that our method can enable the agents to achieve high task-oriented accuracy with fewer repeating questions and rounds compared to traditional ergodic question generation approaches. Qualitative results further show that TSADE facilitates agents to generate higher-quality questions.
Adversarial Driving Behavior Generation Incorporating Human Risk Cognition for Autonomous Vehicle Evaluation
Oct 14, 2023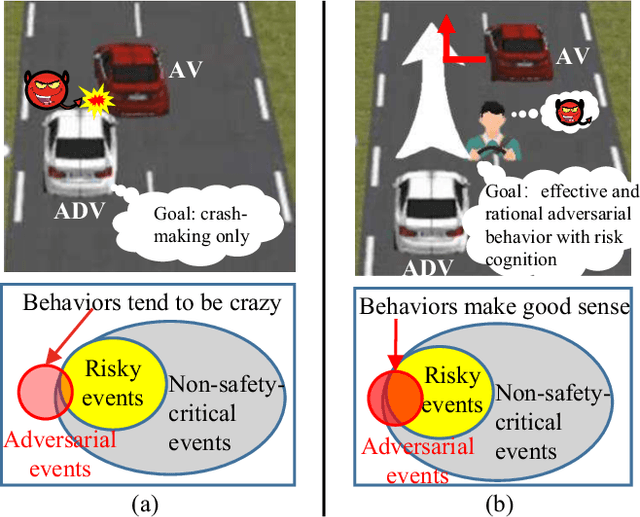

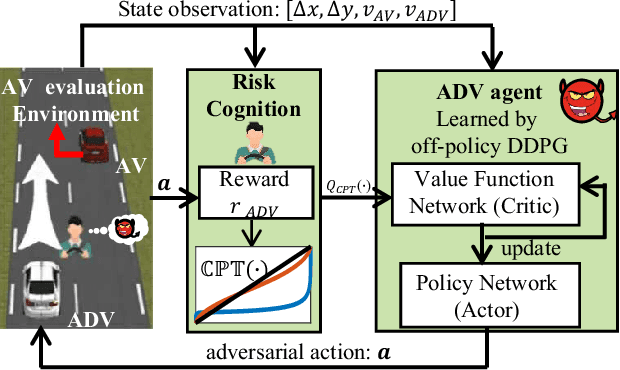
Autonomous vehicle (AV) evaluation has been the subject of increased interest in recent years both in industry and in academia. This paper focuses on the development of a novel framework for generating adversarial driving behavior of background vehicle interfering against the AV to expose effective and rational risky events. Specifically, the adversarial behavior is learned by a reinforcement learning (RL) approach incorporated with the cumulative prospect theory (CPT) which allows representation of human risk cognition. Then, the extended version of deep deterministic policy gradient (DDPG) technique is proposed for training the adversarial policy while ensuring training stability as the CPT action-value function is leveraged. A comparative case study regarding the cut-in scenario is conducted on a high fidelity Hardware-in-the-Loop (HiL) platform and the results demonstrate the adversarial effectiveness to infer the weakness of the tested AV.