 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiAlign: A Scalable and Sample-Efficient Framework for Aligning LLMs to Enhance Reasoning Capabilities
Aug 07, 2025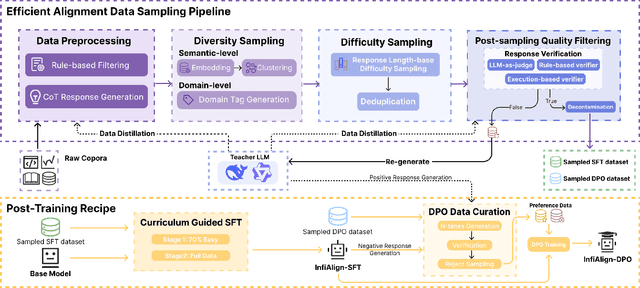
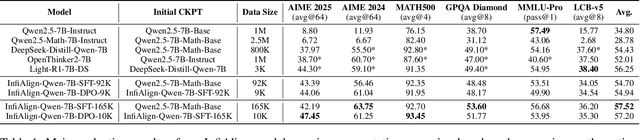
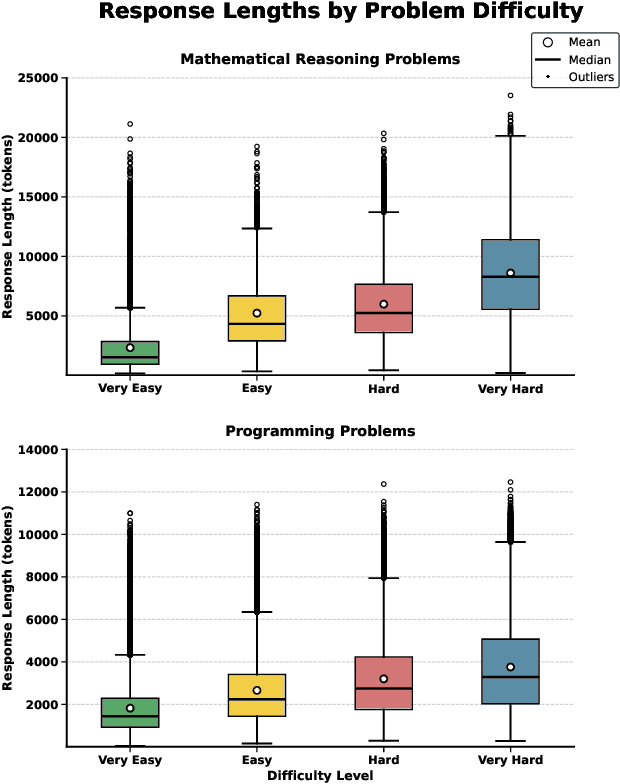
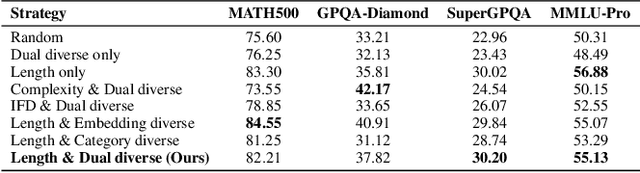
Large language models (LLMs) have exhibited impressive reasoning abilities on a wide range of complex tasks. However, enhancing these capabilities through post-training remains resource intensive, particularly in terms of data and computational cost. Although recent efforts have sought to improve sample efficiency through selective data curation, existing methods often rely on heuristic or task-specific strategies that hinder scalability. In this work, we introduce InfiAlign, a scalable and sample-efficient post-training framework that integrates supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to align LLMs for enhanced reasoning. At the core of InfiAlign is a robust data selection pipeline that automatically curates high-quality alignment data from open-source reasoning datasets using multidimensional quality metrics. This pipeline enables significant performance gains while drastically reducing data requirements and remains extensible to new data sources. When applied to the Qwen2.5-Math-7B-Base model, our SFT model achieves performance on par with DeepSeek-R1-Distill-Qwen-7B, while using only approximately 12% of the training data, and demonstrates strong generalization across diverse reasoning tasks. Additional improvements are obtained through the application of DPO, with particularly notable gains in mathematical reasoning tasks. The model achieves an average improvement of 3.89% on AIME 24/25 benchmarks. Our results highlight the effectiveness of combining principled data selection with full-stage post-training, offering a practical solution for aligning large reasoning models in a scalable and data-efficient manner. The model checkpoints are available at https://huggingface.co/InfiX-ai/InfiAlign-Qwen-7B-SFT.
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025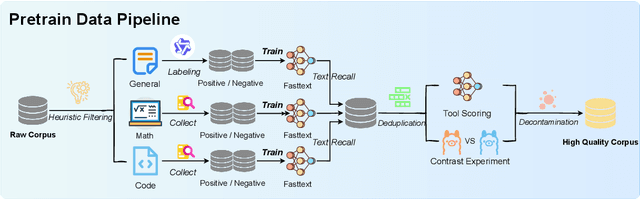

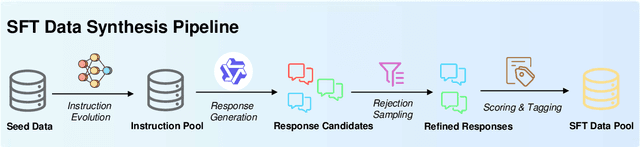

Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.
Generalized Knowledge Distillation via Relationship Matching
May 04, 2022

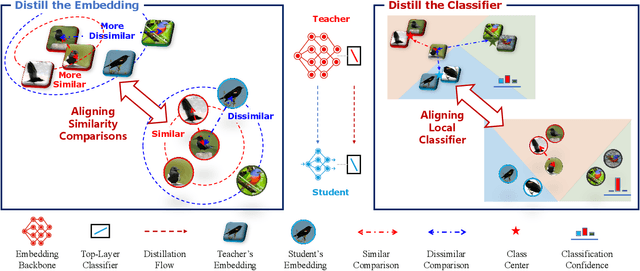
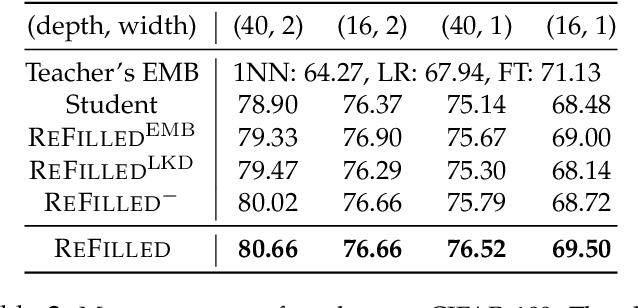
The knowledge of a well-trained deep neural network (a.k.a. the "teacher") is valuable for learning similar tasks. Knowledge distillation extracts knowledge from the teacher and integrates it with the target model (a.k.a. the "student"), which expands the student's knowledge and improves its learning efficacy. Instead of enforcing the teacher to work on the same task as the student, we borrow the knowledge from a teacher trained from a general label space -- in this "Generalized Knowledge Distillation (GKD)", the classes of the teacher and the student may be the same, completely different, or partially overlapped. We claim that the comparison ability between instances acts as an essential factor threading knowledge across tasks, and propose the RElationship FacIlitated Local cLassifiEr Distillation (REFILLED) approach, which decouples the GKD flow of the embedding and the top-layer classifier. In particular, different from reconciling the instance-label confidence between models, REFILLED requires the teacher to reweight the hard tuples pushed forward by the student and then matches the similarity comparison levels between instances. An embedding-induced classifier based on the teacher model supervises the student's classification confidence and adaptively emphasizes the most related supervision from the teacher. REFILLED demonstrates strong discriminative ability when the classes of the teacher vary from the same to a fully non-overlapped set w.r.t. the student. It also achieves state-of-the-art performance on standard knowledge distillation, one-step incremental learning, and few-shot learning tasks.
Faculty Distillation with Optimal Transport
Apr 25, 2022

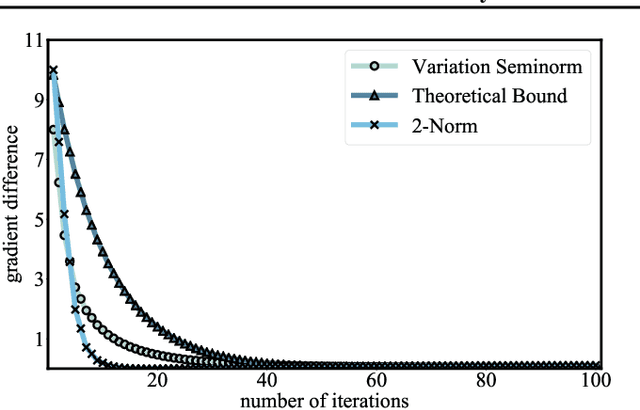

Knowledge distillation (KD) has shown its effectiveness in improving a student classifier given a suitable teacher. The outpouring of diverse and plentiful pre-trained models may provide abundant teacher resources for KD. However, these models are often trained on different tasks from the student, which requires the student to precisely select the most contributive teacher and enable KD across different label spaces. These restrictions disclose the insufficiency of standard KD and motivate us to study a new paradigm called faculty distillation. Given a group of teachers (faculty), a student needs to select the most relevant teacher and perform generalized knowledge reuse. To this end, we propose to link teacher's task and student's task by optimal transport. Based on the semantic relationship between their label spaces, we can bridge the support gap between output distributions by minimizing Sinkhorn distances. The transportation cost also acts as a measurement of teachers' adaptability so that we can rank the teachers efficiently according to their relatedness. Experiments under various settings demonstrate the succinctness and versatility of our method.
Few-Shot Action Recognition with Compromised Metric via Optimal Transport
Apr 08, 2021



Although vital to computer vision systems, few-shot action recognition is still not mature despite the wide research of few-shot image classification. Popular few-shot learning algorithms extract a transferable embedding from seen classes and reuse it on unseen classes by constructing a metric-based classifier. One main obstacle to applying these algorithms in action recognition is the complex structure of videos. Some existing solutions sample frames from a video and aggregate their embeddings to form a video-level representation, neglecting important temporal relations. Others perform an explicit sequence matching between two videos and define their distance as matching cost, imposing too strong restrictions on sequence ordering. In this paper, we propose Compromised Metric via Optimal Transport (CMOT) to combine the advantages of these two solutions. CMOT simultaneously considers semantic and temporal information in videos under Optimal Transport framework, and is discriminative for both content-sensitive and ordering-sensitive tasks. In detail, given two videos, we sample segments from them and cast the calculation of their distance as an optimal transport problem between two segment sequences. To preserve the inherent temporal ordering information, we additionally amend the ground cost matrix by penalizing it with the positional distance between a pair of segments. Empirical results on benchmark datasets demonstrate the superiority of CMOT.
Support-Target Protocol for Meta-Learning
Apr 08, 2021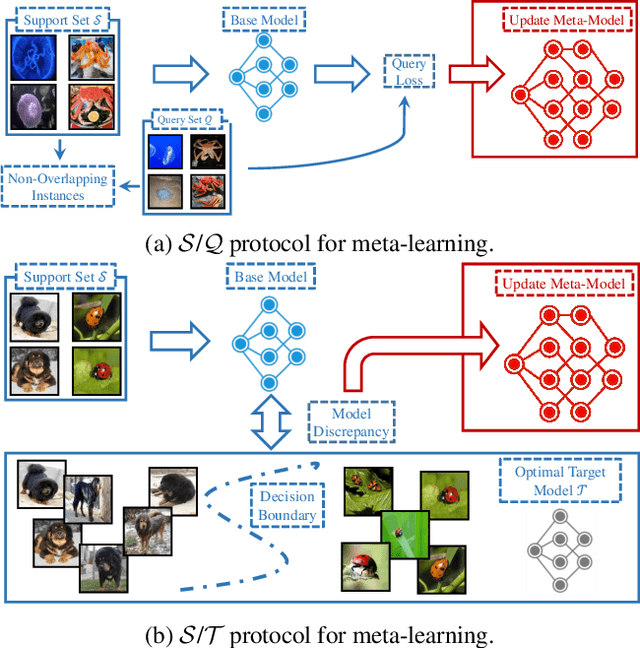

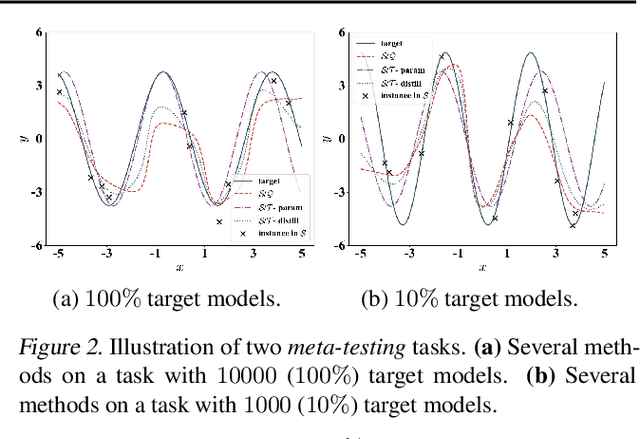
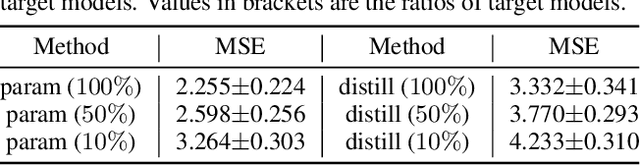
The support/query (S/Q) training protocol is widely used in meta-learning. S/Q protocol trains a task-specific model on S and then evaluates it on Q to optimize the meta-model using query loss, which depends on size and quality of Q. In this paper, we study a new S/T protocol for meta-learning. Assuming that we have access to the theoretically optimal model T for a task, we can directly match the task-specific model trained on S to T. S/T protocol offers a more accurate evaluation since it does not rely on possibly biased and noisy query instances. There are two challenges in putting S/T protocol into practice. Firstly, we have to determine how to match the task-specific model to T. To this end, we minimize the discrepancy between them on a fictitious dataset generated by adversarial learning, and distill the prediction ability of T to the task-specific model. Secondly, we usually do not have ready-made optimal models. As an alternative, we construct surrogate target models by fine-tuning on local tasks the globally pre-trained meta-model, maintaining both efficiency and veracity.