 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatureBench: Benchmarking Agentic Coding for Complex Feature Development
Feb 11, 2026Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.
CLI-Gym: Scalable CLI Task Generation via Agentic Environment Inversion
Feb 11, 2026Agentic coding requires agents to effectively interact with runtime environments, e.g., command line interfaces (CLI), so as to complete tasks like resolving dependency issues, fixing system problems, etc. But it remains underexplored how such environment-intensive tasks can be obtained at scale to enhance agents' capabilities. To address this, based on an analogy between the Dockerfile and the agentic task, we propose to employ agents to simulate and explore environment histories, guided by execution feedback. By tracing histories of a healthy environment, its state can be inverted to an earlier one with runtime failures, from which a task can be derived by packing the buggy state and the corresponding error messages. With our method, named CLI-Gym, a total of 1,655 environment-intensive tasks are derived, being the largest collection of its kind. Moreover, with curated successful trajectories, our fine-tuned model, named LiberCoder, achieves substantial absolute improvements of +21.1% (to 46.1%) on Terminal-Bench, outperforming various strong baselines. To our knowledge, this is the first public pipeline for scalable derivation of environment-intensive tasks.
Collaboratively Self-supervised Video Representation Learning for Action Recognition
Jan 15, 2024Considering the close connection between action recognition and human pose estimation, we design a Collaboratively Self-supervised Video Representation (CSVR) learning framework specific to action recognition by jointly considering generative pose prediction and discriminative context matching as pretext tasks. Specifically, our CSVR consists of three branches: a generative pose prediction branch, a discriminative context matching branch, and a video generating branch. Among them, the first one encodes dynamic motion feature by utilizing Conditional-GAN to predict the human poses of future frames, and the second branch extracts static context features by pulling the representations of clips and compressed key frames from the same video together while pushing apart the pairs from different videos. The third branch is designed to recover the current video frames and predict the future ones, for the purpose of collaboratively improving dynamic motion features and static context features. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the UCF101 and HMDB51 datasets.
Hierarchical Compositional Representations for Few-shot Action Recognition
Aug 19, 2022
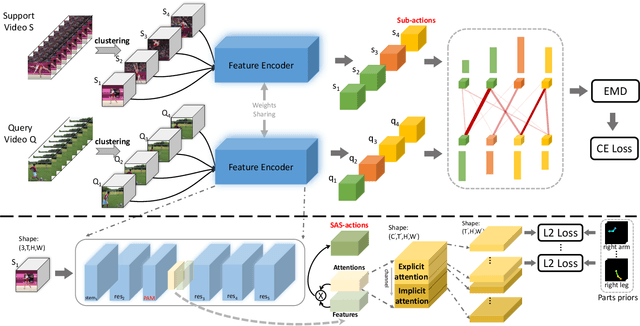
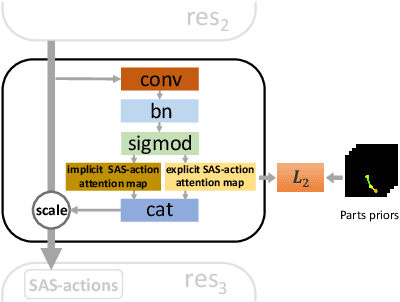
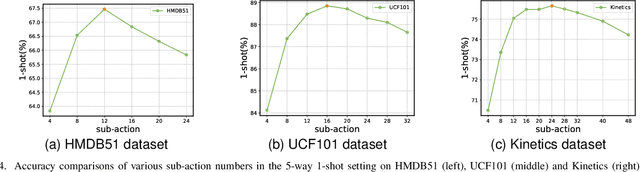
Recently action recognition has received more and more attention for its comprehensive and practical applications in intelligent surveillance and human-computer interaction. However, few-shot action recognition has not been well explored and remains challenging because of data scarcity. In this paper, we propose a novel hierarchical compositional representations (HCR) learning approach for few-shot action recognition. Specifically, we divide a complicated action into several sub-actions by carefully designed hierarchical clustering and further decompose the sub-actions into more fine-grained spatially attentional sub-actions (SAS-actions). Although there exist large differences between base classes and novel classes, they can share similar patterns in sub-actions or SAS-actions. Furthermore, we adopt the Earth Mover's Distance in the transportation problem to measure the similarity between video samples in terms of sub-action representations. It computes the optimal matching flows between sub-actions as distance metric, which is favorable for comparing fine-grained patterns. Extensive experiments show our method achieves the state-of-the-art results on HMDB51, UCF101 and Kinetics datasets.
Attribute Group Editing for Reliable Few-shot Image Generation
Mar 16, 2022
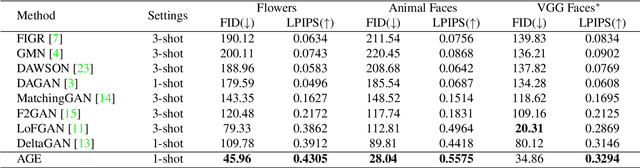
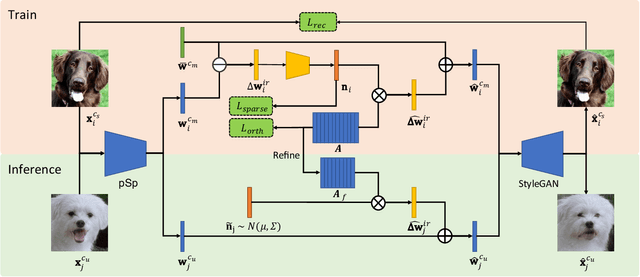
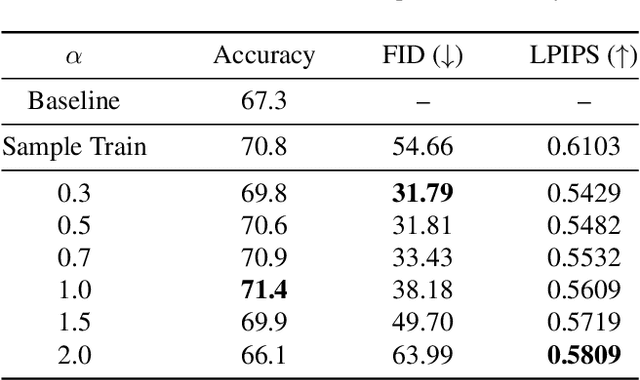
Few-shot image generation is a challenging task even using the state-of-the-art Generative Adversarial Networks (GANs). Due to the unstable GAN training process and the limited training data, the generated images are often of low quality and low diversity. In this work, we propose a new editing-based method, i.e., Attribute Group Editing (AGE), for few-shot image generation. The basic assumption is that any image is a collection of attributes and the editing direction for a specific attribute is shared across all categories. AGE examines the internal representation learned in GANs and identifies semantically meaningful directions. Specifically, the class embedding, i.e., the mean vector of the latent codes from a specific category, is used to represent the category-relevant attributes, and the category-irrelevant attributes are learned globally by Sparse Dictionary Learning on the difference between the sample embedding and the class embedding. Given a GAN well trained on seen categories, diverse images of unseen categories can be synthesized through editing category-irrelevant attributes while keeping category-relevant attributes unchanged. Without re-training the GAN, AGE is capable of not only producing more realistic and diverse images for downstream visual applications with limited data but achieving controllable image editing with interpretable category-irrelevant directions.
Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks
Apr 17, 2018
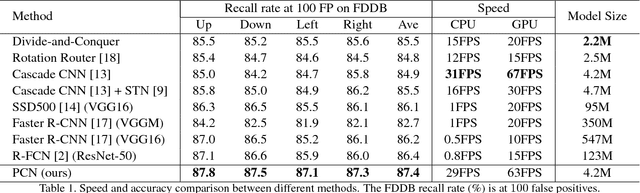
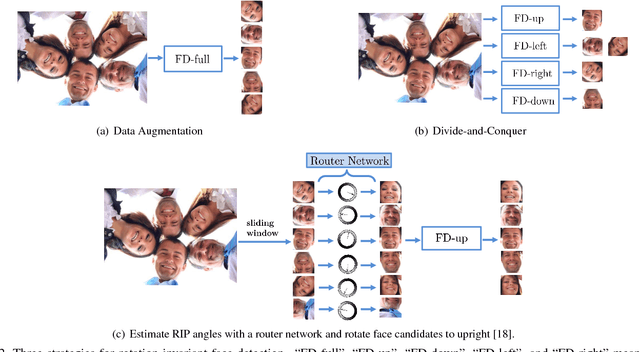
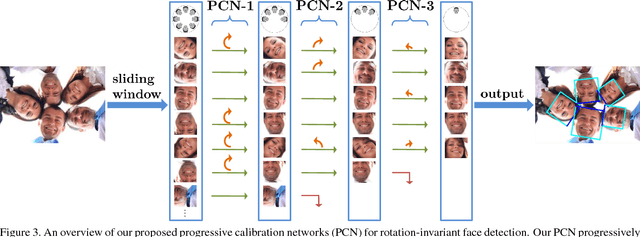
Rotation-invariant face detection, i.e. detecting faces with arbitrary rotation-in-plane (RIP) angles, is widely required in unconstrained applications but still remains as a challenging task, due to the large variations of face appearances. Most existing methods compromise with speed or accuracy to handle the large RIP variations. To address this problem more efficiently, we propose Progressive Calibration Networks (PCN) to perform rotation-invariant face detection in a coarse-to-fine manner. PCN consists of three stages, each of which not only distinguishes the faces from non-faces, but also calibrates the RIP orientation of each face candidate to upright progressively. By dividing the calibration process into several progressive steps and only predicting coarse orientations in early stages, PCN can achieve precise and fast calibration. By performing binary classification of face vs. non-face with gradually decreasing RIP ranges, PCN can accurately detect faces with full $360^{\circ}$ RIP angles. Such designs lead to a real-time rotation-invariant face detector. The experiments on multi-oriented FDDB and a challenging subset of WIDER FACE containing rotated faces in the wild show that our PCN achieves quite promising performance.
Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness
Sep 23, 2016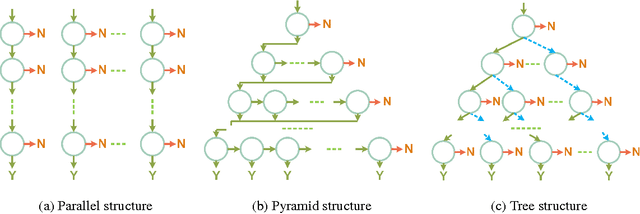


Multi-view face detection in open environment is a challenging task due to diverse variations of face appearances and shapes. Most multi-view face detectors depend on multiple models and organize them in parallel, pyramid or tree structure, which compromise between the accuracy and time-cost. Aiming at a more favorable multi-view face detector, we propose a novel funnel-structured cascade (FuSt) detection framework. In a coarse-to-fine flavor, our FuSt consists of, from top to bottom, 1) multiple view-specific fast LAB cascade for extremely quick face proposal, 2) multiple coarse MLP cascade for further candidate window verification, and 3) a unified fine MLP cascade with shape-indexed features for accurate face detection. Compared with other structures, on the one hand, the proposed one uses multiple computationally efficient distributed classifiers to propose a small number of candidate windows but with a high recall of multi-view faces. On the other hand, by using a unified MLP cascade to examine proposals of all views in a centralized style, it provides a favorable solution for multi-view face detection with high accuracy and low time-cost. Besides, the FuSt detector is alignment-aware and performs a coarse facial part prediction which is beneficial for subsequent face alignment. Extensive experiments on two challenging datasets, FDDB and AFW, demonstrate the effectiveness of our FuSt detector in both accuracy and speed.