 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIMM: Brain Inspired Masked Modeling for Video Representation Learning
May 21, 2024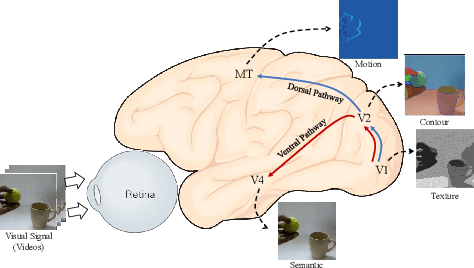

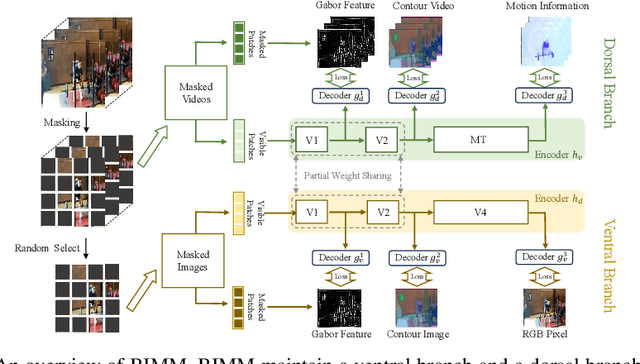
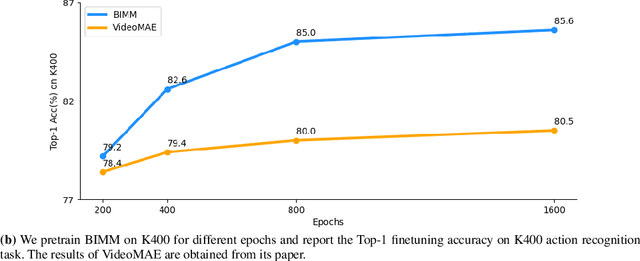
The visual pathway of human brain includes two sub-pathways, ie, the ventral pathway and the dorsal pathway, which focus on object identification and dynamic information modeling, respectively. Both pathways comprise multi-layer structures, with each layer responsible for processing different aspects of visual information. Inspired by visual information processing mechanism of the human brain, we propose the Brain Inspired Masked Modeling (BIMM) framework, aiming to learn comprehensive representations from videos. Specifically, our approach consists of ventral and dorsal branches, which learn image and video representations, respectively. Both branches employ the Vision Transformer (ViT) as their backbone and are trained using masked modeling method. To achieve the goals of different visual cortices in the brain, we segment the encoder of each branch into three intermediate blocks and reconstruct progressive prediction targets with light weight decoders. Furthermore, drawing inspiration from the information-sharing mechanism in the visual pathways, we propose a partial parameter sharing strategy between the branches during training. Extensive experiments demonstrate that BIMM achieves superior performance compared to the state-of-the-art methods.
Collaboratively Self-supervised Video Representation Learning for Action Recognition
Jan 15, 2024Considering the close connection between action recognition and human pose estimation, we design a Collaboratively Self-supervised Video Representation (CSVR) learning framework specific to action recognition by jointly considering generative pose prediction and discriminative context matching as pretext tasks. Specifically, our CSVR consists of three branches: a generative pose prediction branch, a discriminative context matching branch, and a video generating branch. Among them, the first one encodes dynamic motion feature by utilizing Conditional-GAN to predict the human poses of future frames, and the second branch extracts static context features by pulling the representations of clips and compressed key frames from the same video together while pushing apart the pairs from different videos. The third branch is designed to recover the current video frames and predict the future ones, for the purpose of collaboratively improving dynamic motion features and static context features. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the UCF101 and HMDB51 datasets.