 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPose: eXplainable Human Pose Estimation
Mar 19, 2024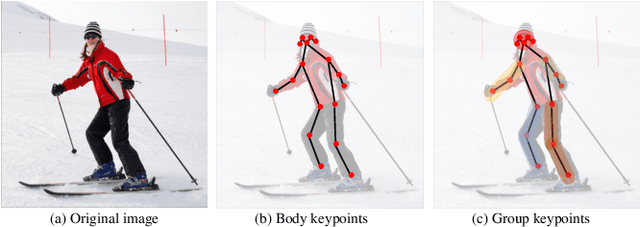
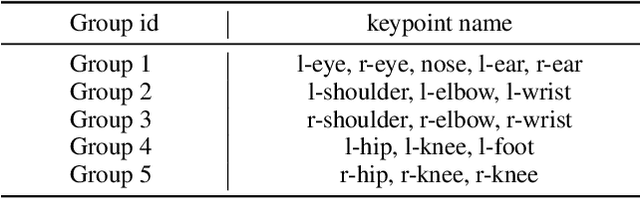
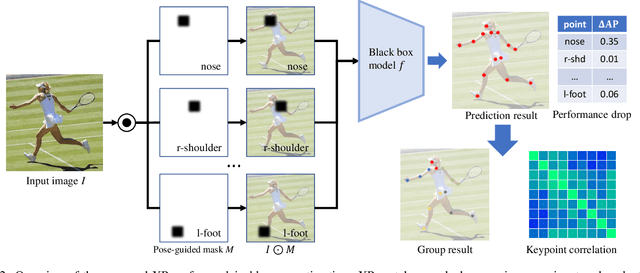
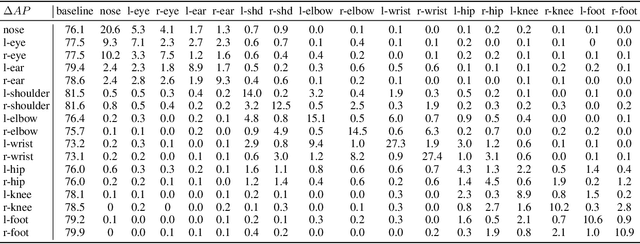
Current approaches in pose estimation primarily concentrate on enhancing model architectures, often overlooking the importance of comprehensively understanding the rationale behind model decisions. In this paper, we propose XPose, a novel framework that incorporates Explainable AI (XAI) principles into pose estimation. This integration aims to elucidate the individual contribution of each keypoint to final prediction, thereby elevating the model's transparency and interpretability. Conventional XAI techniques have predominantly addressed tasks with single-target tasks like classification. Additionally, the application of Shapley value, a common measure in XAI, to pose estimation has been hindered by prohibitive computational demands. To address these challenges, this work introduces an innovative concept called Group Shapley Value (GSV). This approach strategically organizes keypoints into clusters based on their interdependencies. Within these clusters, GSV meticulously calculates Shapley value for keypoints, while for inter-cluster keypoints, it opts for a more holistic group-level valuation. This dual-level computation framework meticulously assesses keypoint contributions to the final outcome, optimizing computational efficiency. Building on the insights into keypoint interactions, we devise a novel data augmentation technique known as Group-based Keypoint Removal (GKR). This method ingeniously removes individual keypoints during training phases, deliberately preserving those with strong mutual connections, thereby refining the model's predictive prowess for non-visible keypoints. The empirical validation of GKR across a spectrum of standard approaches attests to its efficacy. GKR's success demonstrates how using Explainable AI (XAI) can directly enhance pose estimation models.
On Leveraging Large Language Models for Enhancing Entity Resolution
Jan 07, 2024



Entity resolution, the task of identifying and consolidating records that pertain to the same real-world entity, plays a pivotal role in various sectors such as e-commerce, healthcare, and law enforcement. The emergence of Large Language Models (LLMs) like GPT-4 has introduced a new dimension to this task, leveraging their advanced linguistic capabilities. This paper explores the potential of LLMs in the entity resolution process, shedding light on both their advantages and the computational complexities associated with large-scale matching. We introduce strategies for the efficient utilization of LLMs, including the selection of an optimal set of matching questions, namely MQsSP, which is proved to be a NP-hard problem. Our approach optimally chooses the most effective matching questions while keep consumption limited to your budget . Additionally, we propose a method to adjust the distribution of possible partitions after receiving responses from LLMs, with the goal of reducing the uncertainty of entity resolution. We evaluate the effectiveness of our approach using entropy as a metric, and our experimental results demonstrate the efficiency and effectiveness of our proposed methods, offering promising prospects for real-world applications.
HMSG: Heterogeneous Graph Neural Network based on Metapath Subgraph Learning
Sep 07, 2021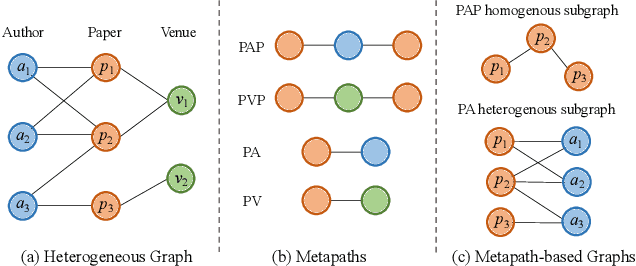

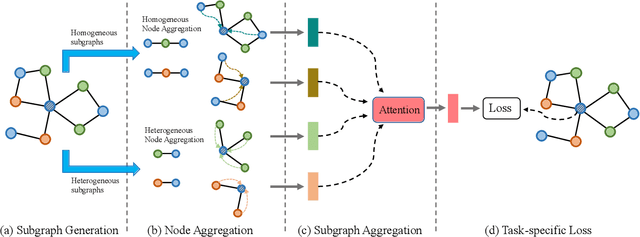
Many real-world data can be represented as heterogeneous graphs with different types of nodes and connections. Heterogeneous graph neural network model aims to embed nodes or subgraphs into low-dimensional vector space for various downstream tasks such as node classification, link prediction, etc. Although several models were proposed recently, they either only aggregate information from the same type of neighbors, or just indiscriminately treat homogeneous and heterogeneous neighbors in the same way. Based on these observations, we propose a new heterogeneous graph neural network model named HMSG to comprehensively capture structural, semantic and attribute information from both homogeneous and heterogeneous neighbors. Specifically, we first decompose the heterogeneous graph into multiple metapath-based homogeneous and heterogeneous subgraphs, and each subgraph associates specific semantic and structural information. Then message aggregation methods are applied to each subgraph independently, so that information can be learned in a more targeted and efficient manner. Through a type-specific attribute transformation, node attributes can also be transferred among different types of nodes. Finally, we fuse information from subgraphs together to get the complete representation. Extensive experiments on several datasets for node classification, node clustering and link prediction tasks show that HMSG achieves the best performance in all evaluation metrics than state-of-the-art baselines.