 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.
R^2AG: Incorporating Retrieval Information into Retrieval Augmented Generation
Jun 19, 2024
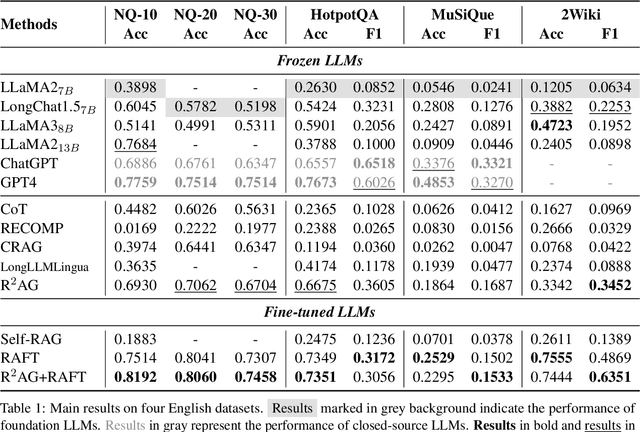

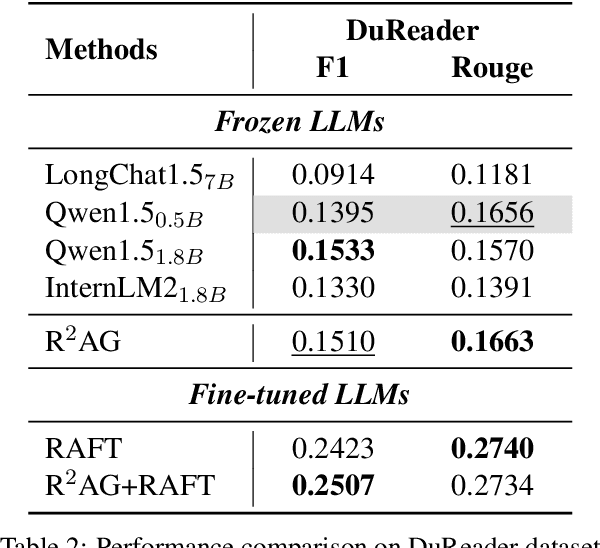
Retrieval augmented generation (RAG) has been applied in many scenarios to augment large language models (LLMs) with external documents provided by retrievers. However, a semantic gap exists between LLMs and retrievers due to differences in their training objectives and architectures. This misalignment forces LLMs to passively accept the documents provided by the retrievers, leading to incomprehension in the generation process, where the LLMs are burdened with the task of distinguishing these documents using their inherent knowledge. This paper proposes R$^2$AG, a novel enhanced RAG framework to fill this gap by incorporating Retrieval information into Retrieval Augmented Generation. Specifically, R$^2$AG utilizes the nuanced features from the retrievers and employs a R$^2$-Former to capture retrieval information. Then, a retrieval-aware prompting strategy is designed to integrate retrieval information into LLMs' generation. Notably, R$^2$AG suits low-source scenarios where LLMs and retrievers are frozen. Extensive experiments across five datasets validate the effectiveness, robustness, and efficiency of R$^2$AG. Our analysis reveals that retrieval information serves as an anchor to aid LLMs in the generation process, thereby filling the semantic gap.
On Leveraging Large Language Models for Enhancing Entity Resolution
Jan 07, 2024



Entity resolution, the task of identifying and consolidating records that pertain to the same real-world entity, plays a pivotal role in various sectors such as e-commerce, healthcare, and law enforcement. The emergence of Large Language Models (LLMs) like GPT-4 has introduced a new dimension to this task, leveraging their advanced linguistic capabilities. This paper explores the potential of LLMs in the entity resolution process, shedding light on both their advantages and the computational complexities associated with large-scale matching. We introduce strategies for the efficient utilization of LLMs, including the selection of an optimal set of matching questions, namely MQsSP, which is proved to be a NP-hard problem. Our approach optimally chooses the most effective matching questions while keep consumption limited to your budget . Additionally, we propose a method to adjust the distribution of possible partitions after receiving responses from LLMs, with the goal of reducing the uncertainty of entity resolution. We evaluate the effectiveness of our approach using entropy as a metric, and our experimental results demonstrate the efficiency and effectiveness of our proposed methods, offering promising prospects for real-world applications.
S$^{2}$-DMs:Skip-Step Diffusion Models
Jan 03, 2024



Diffusion models have emerged as powerful generative tools, rivaling GANs in sample quality and mirroring the likelihood scores of autoregressive models. A subset of these models, exemplified by DDIMs, exhibit an inherent asymmetry: they are trained over $T$ steps but only sample from a subset of $T$ during generation. This selective sampling approach, though optimized for speed, inadvertently misses out on vital information from the unsampled steps, leading to potential compromises in sample quality. To address this issue, we present the S$^{2}$-DMs, which is a new training method by using an innovative $L_{skip}$, meticulously designed to reintegrate the information omitted during the selective sampling phase. The benefits of this approach are manifold: it notably enhances sample quality, is exceptionally simple to implement, requires minimal code modifications, and is flexible enough to be compatible with various sampling algorithms. On the CIFAR10 dataset, models trained using our algorithm showed an improvement of 3.27% to 14.06% over models trained with traditional methods across various sampling algorithms (DDIMs, PNDMs, DEIS) and different numbers of sampling steps (10, 20, ..., 1000). On the CELEBA dataset, the improvement ranged from 8.97% to 27.08%. Access to the code and additional resources is provided in the github.
Single-Cell RNA-seq Synthesis with Latent Diffusion Model
Dec 21, 2023The single-cell RNA sequencing (scRNA-seq) technology enables researchers to study complex biological systems and diseases with high resolution. The central challenge is synthesizing enough scRNA-seq samples; insufficient samples can impede downstream analysis and reproducibility. While various methods have been attempted in past research, the resulting scRNA-seq samples were often of poor quality or limited in terms of useful specific cell subpopulations. To address these issues, we propose a novel method called Single-Cell Latent Diffusion (SCLD) based on the Diffusion Model. This method is capable of synthesizing large-scale, high-quality scRNA-seq samples, including both 'holistic' or targeted specific cellular subpopulations within a unified framework. A pre-guidance mechanism is designed for synthesizing specific cellular subpopulations, while a post-guidance mechanism aims to enhance the quality of scRNA-seq samples. The SCLD can synthesize large-scale and high-quality scRNA-seq samples for various downstream tasks. Our experimental results demonstrate state-of-the-art performance in cell classification and data distribution distances when evaluated on two scRNA-seq benchmarks. Additionally, visualization experiments show the SCLD's capability in synthesizing specific cellular subpopulations.
Topic-DPR: Topic-based Prompts for Dense Passage Retrieval
Oct 10, 2023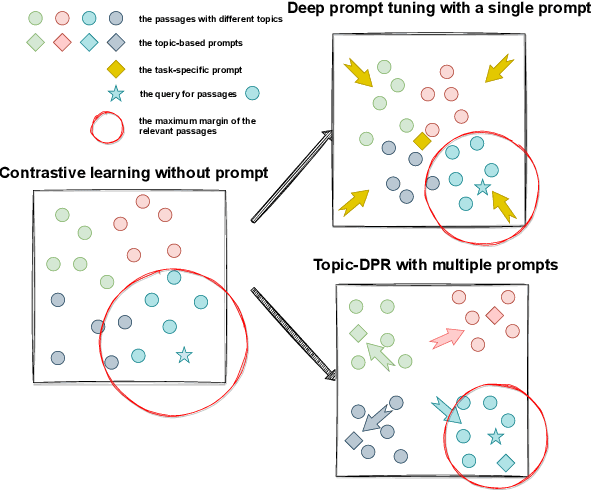
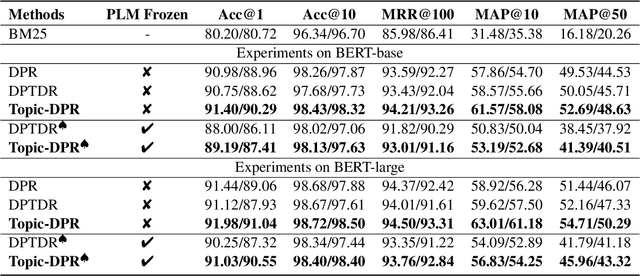
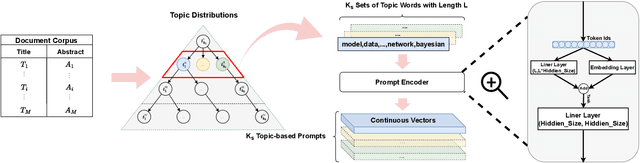
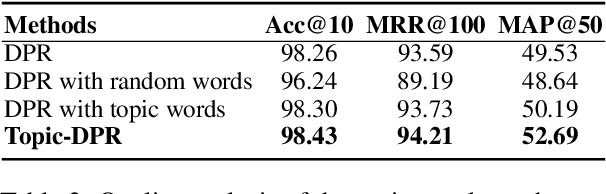
Prompt-based learning's efficacy across numerous natural language processing tasks has led to its integration into dense passage retrieval. Prior research has mainly focused on enhancing the semantic understanding of pre-trained language models by optimizing a single vector as a continuous prompt. This approach, however, leads to a semantic space collapse; identical semantic information seeps into all representations, causing their distributions to converge in a restricted region. This hinders differentiation between relevant and irrelevant passages during dense retrieval. To tackle this issue, we present Topic-DPR, a dense passage retrieval model that uses topic-based prompts. Unlike the single prompt method, multiple topic-based prompts are established over a probabilistic simplex and optimized simultaneously through contrastive learning. This encourages representations to align with their topic distributions, improving space uniformity. Furthermore, we introduce a novel positive and negative sampling strategy, leveraging semi-structured data to boost dense retrieval efficiency. Experimental results from two datasets affirm that our method surpasses previous state-of-the-art retrieval techniques.
Identical and Fraternal Twins: Fine-Grained Semantic Contrastive Learning of Sentence Representations
Jul 20, 2023



The enhancement of unsupervised learning of sentence representations has been significantly achieved by the utility of contrastive learning. This approach clusters the augmented positive instance with the anchor instance to create a desired embedding space. However, relying solely on the contrastive objective can result in sub-optimal outcomes due to its inability to differentiate subtle semantic variations between positive pairs. Specifically, common data augmentation techniques frequently introduce semantic distortion, leading to a semantic margin between the positive pair. While the InfoNCE loss function overlooks the semantic margin and prioritizes similarity maximization between positive pairs during training, leading to the insensitive semantic comprehension ability of the trained model. In this paper, we introduce a novel Identical and Fraternal Twins of Contrastive Learning (named IFTCL) framework, capable of simultaneously adapting to various positive pairs generated by different augmentation techniques. We propose a \textit{Twins Loss} to preserve the innate margin during training and promote the potential of data enhancement in order to overcome the sub-optimal issue. We also present proof-of-concept experiments combined with the contrastive objective to prove the validity of the proposed Twins Loss. Furthermore, we propose a hippocampus queue mechanism to restore and reuse the negative instances without additional calculation, which further enhances the efficiency and performance of the IFCL. We verify the IFCL framework on nine semantic textual similarity tasks with both English and Chinese datasets, and the experimental results show that IFCL outperforms state-of-the-art methods.
An Adversarial Transfer Network for Knowledge Representation Learning
Apr 30, 2021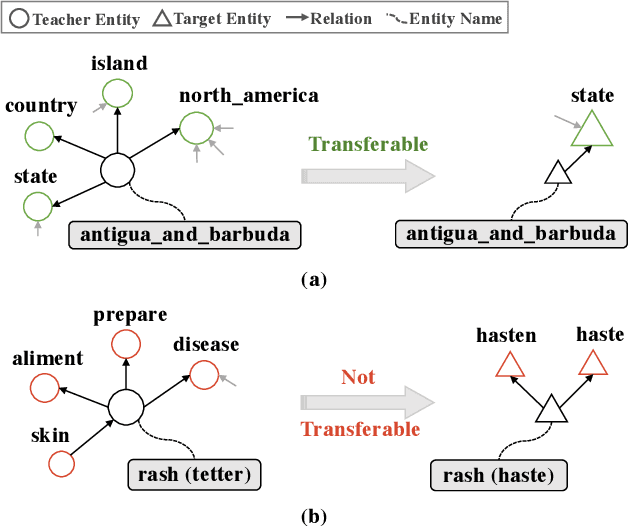
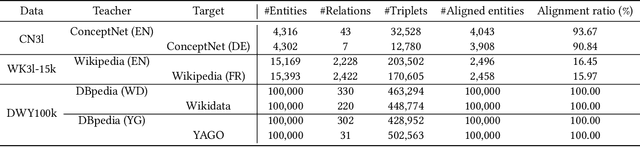
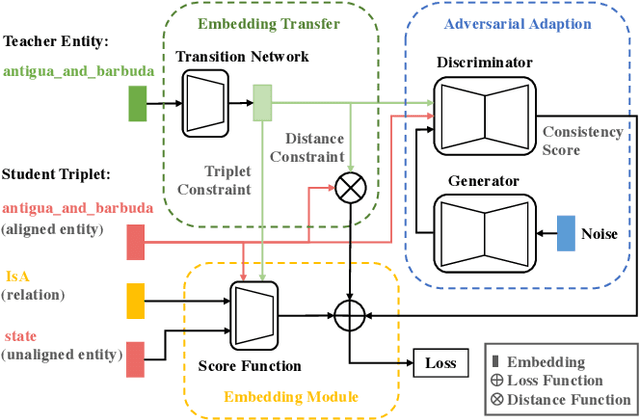

Knowledge representation learning has received a lot of attention in the past few years. The success of existing methods heavily relies on the quality of knowledge graphs. The entities with few triplets tend to be learned with less expressive power. Fortunately, there are many knowledge graphs constructed from various sources, the representations of which could contain much information. We propose an adversarial embedding transfer network ATransN, which transfers knowledge from one or more teacher knowledge graphs to a target one through an aligned entity set without explicit data leakage. Specifically, we add soft constraints on aligned entity pairs and neighbours to the existing knowledge representation learning methods. To handle the problem of possible distribution differences between teacher and target knowledge graphs, we introduce an adversarial adaption module. The discriminator of this module evaluates the degree of consistency between the embeddings of an aligned entity pair. The consistency score is then used as the weights of soft constraints. It is not necessary to acquire the relations and triplets in teacher knowledge graphs because we only utilize the entity representations. Knowledge graph completion results show that ATransN achieves better performance against baselines without transfer on three datasets, CN3l, WK3l, and DWY100k. The ablation study demonstrates that ATransN can bring steady and consistent improvement in different settings. The extension of combining other knowledge graph embedding algorithms and the extension with three teacher graphs display the promising generalization of the adversarial transfer network.
Incorporating GAN for Negative Sampling in Knowledge Representation Learning
Sep 23, 2018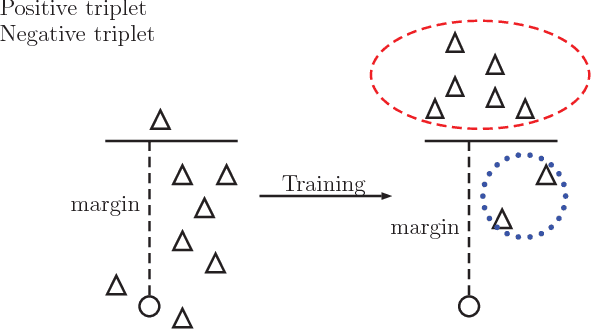
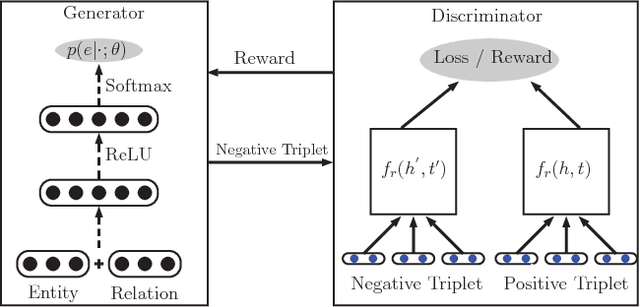
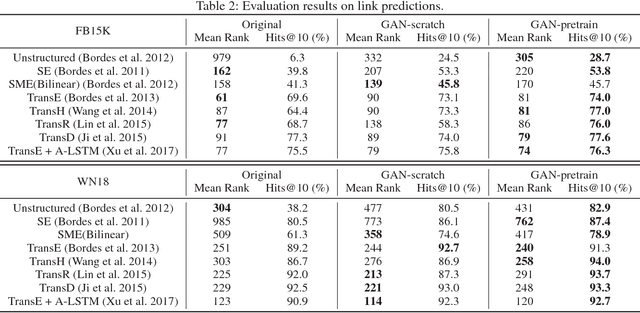
Knowledge representation learning aims at modeling knowledge graph by encoding entities and relations into a low dimensional space. Most of the traditional works for knowledge embedding need negative sampling to minimize a margin-based ranking loss. However, those works construct negative samples through a random mode, by which the samples are often too trivial to fit the model efficiently. In this paper, we propose a novel knowledge representation learning framework based on Generative Adversarial Networks (GAN). In this GAN-based framework, we take advantage of a generator to obtain high-quality negative samples. Meanwhile, the discriminator in GAN learns the embeddings of the entities and relations in knowledge graph. Thus, we can incorporate the proposed GAN-based framework into various traditional models to improve the ability of knowledge representation learning. Experimental results show that our proposed GAN-based framework outperforms baselines on triplets classification and link prediction tasks.
Personalizing a Dialogue System with Transfer Reinforcement Learning
May 26, 2017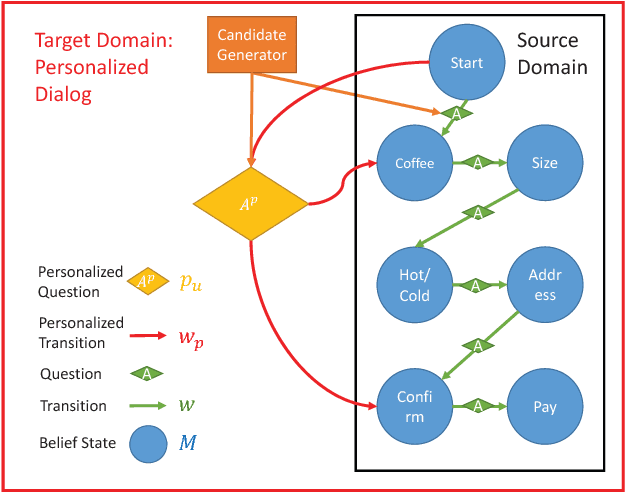


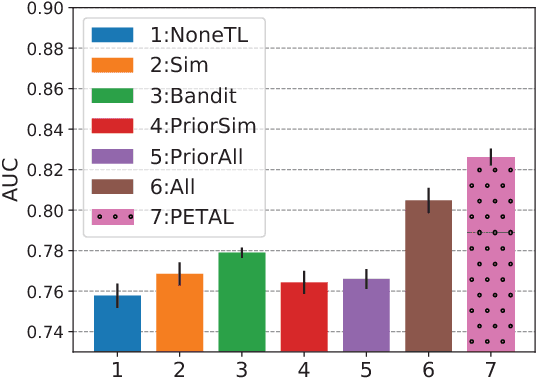
It is difficult to train a personalized task-oriented dialogue system because the data collected from each individual is often insufficient. Personalized dialogue systems trained on a small dataset can overfit and make it difficult to adapt to different user needs. One way to solve this problem is to consider a collection of multiple users' data as a source domain and an individual user's data as a target domain, and to perform a transfer learning from the source to the target domain. By following this idea, we propose "PETAL"(PErsonalized Task-oriented diALogue), a transfer-learning framework based on POMDP to learn a personalized dialogue system. The system first learns common dialogue knowledge from the source domain and then adapts this knowledge to the target user. This framework can avoid the negative transfer problem by considering differences between source and target users. The policy in the personalized POMDP can learn to choose different actions appropriately for different users. Experimental results on a real-world coffee-shopping data and simulation data show that our personalized dialogue system can choose different optimal actions for different users, and thus effectively improve the dialogue quality under the personalized setting.