 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMO: Frustratingly Easy Progressive Training of Extendable MoE
May 14, 2026Sparse Mixture-of-Experts (MoE) models offer a powerful way to scale model size without increasing compute, as per-token FLOPs depend only on k active experts rather than the total pool of E experts. Yet, this asymmetry creates an MoE efficiency paradox in practice: adding more experts balloons memory and communication costs, making actual training inefficient. We argue that this bottleneck arises in part because current MoE training allocates too many experts from the beginning, even though early-stage data may not fully utilize such capacity. Motivated by this, we propose EMO, a simple progressive training framework that treats MoE capacity as expandable memory and grows the expert pool over the course of training. EMO explicitly models sparsity in scaling law to derive stage-wise compute-optimal token budgets for progressive expansion. Empirical results show that EMO matches the performance of a fixed-expert setup in large-scale experiments while improving wall-clock efficiency. It offers a surprisingly simple yet effective path to scalable MoE training, preserving the benefits of large expert pools while reducing both training time and GPU cost.
Asymmetric Idiosyncrasies in Multimodal Models
Feb 26, 2026In this work, we study idiosyncrasies in the caption models and their downstream impact on text-to-image models. We design a systematic analysis: given either a generated caption or the corresponding image, we train neural networks to predict the originating caption model. Our results show that text classification yields very high accuracy (99.70\%), indicating that captioning models embed distinctive stylistic signatures. In contrast, these signatures largely disappear in the generated images, with classification accuracy dropping to at most 50\% even for the state-of-the-art Flux model. To better understand this cross-modal discrepancy, we further analyze the data and find that the generated images fail to preserve key variations present in captions, such as differences in the level of detail, emphasis on color and texture, and the distribution of objects within a scene. Overall, our classification-based framework provides a novel methodology for quantifying both the stylistic idiosyncrasies of caption models and the prompt-following ability of text-to-image systems.
UReason: Benchmarking the Reasoning Paradox in Unified Multimodal Models
Feb 09, 2026To elicit capabilities for addressing complex and implicit visual requirements, recent unified multimodal models increasingly adopt chain-of-thought reasoning to guide image generation. However, the actual effect of reasoning on visual synthesis remains unclear. We present UReason, a diagnostic benchmark for reasoning-driven image generation that evaluates whether reasoning can be faithfully executed in pixels. UReason contains 2,000 instances across five task families: Code, Arithmetic, Spatial, Attribute, and Text reasoning. To isolate the role of reasoning traces, we introduce an evaluation framework comparing direct generation, reasoning-guided generation, and de-contextualized generation which conditions only on the refined prompt. Across eight open-source unified models, we observe a consistent Reasoning Paradox: Reasoning traces generally improve performance over direct generation, yet retaining intermediate thoughts as conditioning context often hinders visual synthesis, and conditioning only on the refined prompt yields substantial gains. Our analysis suggests that the bottleneck lies in contextual interference rather than insufficient reasoning capacity. UReason provides a principled testbed for studying reasoning in unified models and motivates future methods that effectively integrate reasoning for visual generation while mitigating interference.
TimeWak: Temporal Chained-Hashing Watermark for Time Series Data
Jun 06, 2025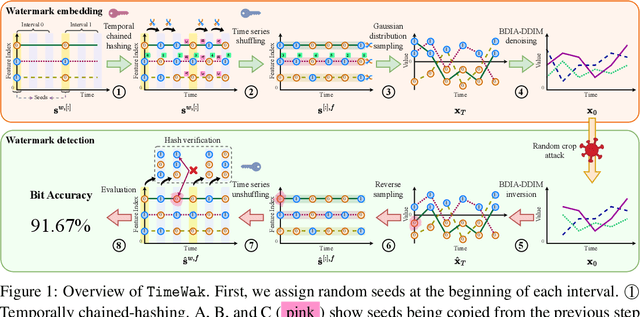
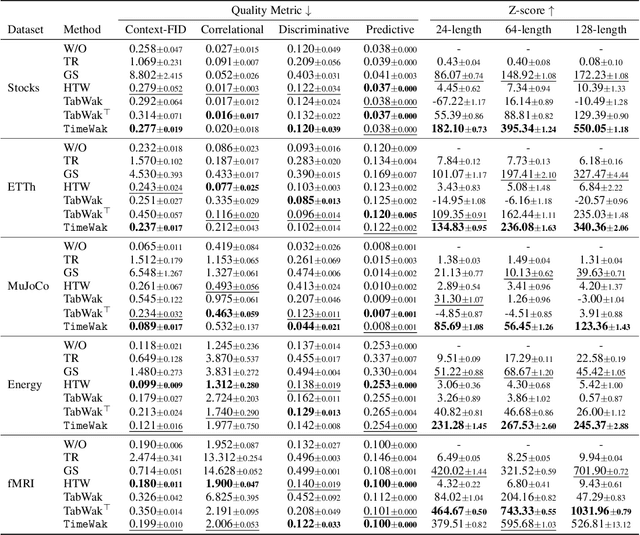
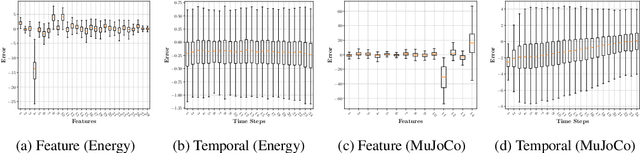
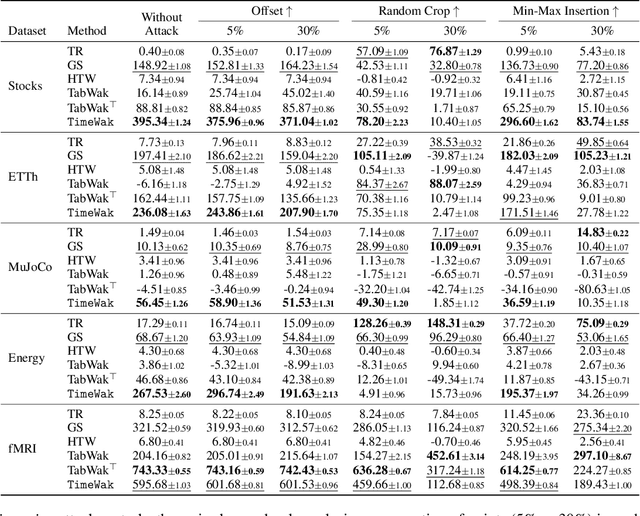
Synthetic time series generated by diffusion models enable sharing privacy-sensitive datasets, such as patients' functional MRI records. Key criteria for synthetic data include high data utility and traceability to verify the data source. Recent watermarking methods embed in homogeneous latent spaces, but state-of-the-art time series generators operate in real space, making latent-based watermarking incompatible. This creates the challenge of watermarking directly in real space while handling feature heterogeneity and temporal dependencies. We propose TimeWak, the first watermarking algorithm for multivariate time series diffusion models. To handle temporal dependence and spatial heterogeneity, TimeWak embeds a temporal chained-hashing watermark directly within the real temporal-feature space. The other unique feature is the $\epsilon$-exact inversion, which addresses the non-uniform reconstruction error distribution across features from inverting the diffusion process to detect watermarks. We derive the error bound of inverting multivariate time series and further maintain high watermark detectability. We extensively evaluate TimeWak on its impact on synthetic data quality, watermark detectability, and robustness under various post-editing attacks, against 5 datasets and baselines of different temporal lengths. Our results show that TimeWak achieves improvements of 61.96% in context-FID score, and 8.44% in correlational scores against the state-of-the-art baseline, while remaining consistently detectable.
GROWN+UP: A Graph Representation Of a Webpage Network Utilizing Pre-training
Aug 03, 2022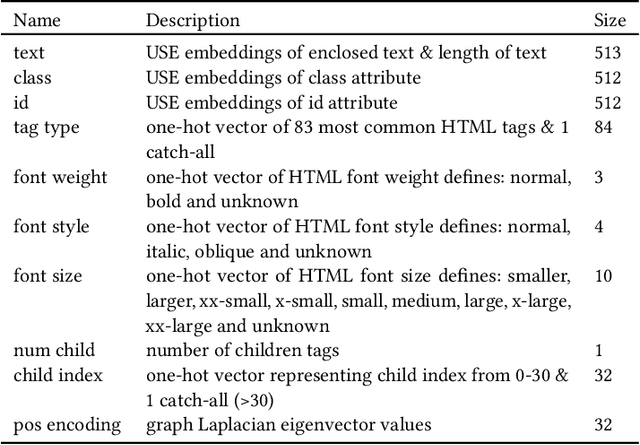
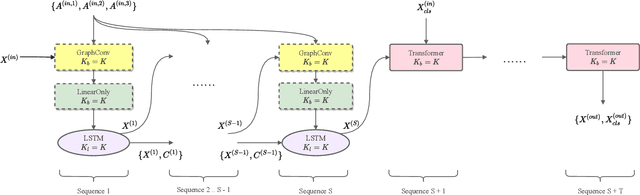
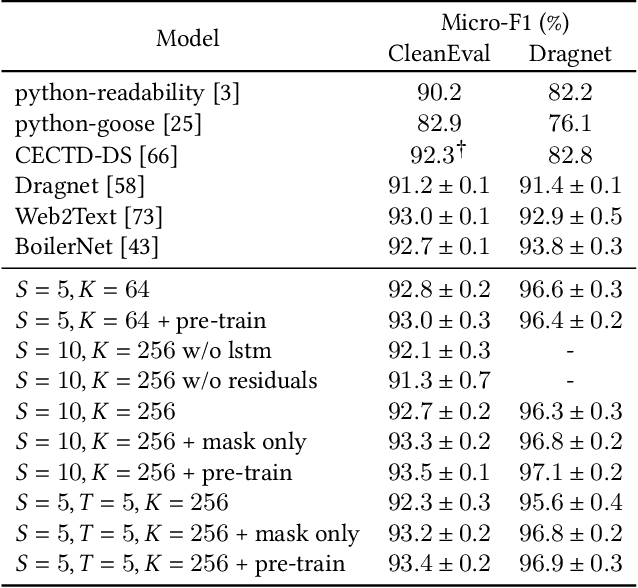
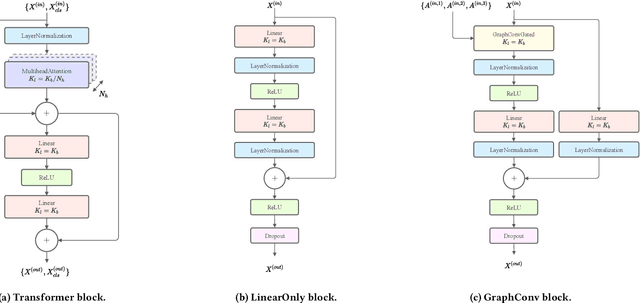
Large pre-trained neural networks are ubiquitous and critical to the success of many downstream tasks in natural language processing and computer vision. However, within the field of web information retrieval, there is a stark contrast in the lack of similarly flexible and powerful pre-trained models that can properly parse webpages. Consequently, we believe that common machine learning tasks like content extraction and information mining from webpages have low-hanging gains that yet remain untapped. We aim to close the gap by introducing an agnostic deep graph neural network feature extractor that can ingest webpage structures, pre-train self-supervised on massive unlabeled data, and fine-tune to arbitrary tasks on webpages effectually. Finally, we show that our pre-trained model achieves state-of-the-art results using multiple datasets on two very different benchmarks: webpage boilerplate removal and genre classification, thus lending support to its potential application in diverse downstream tasks.
Simple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022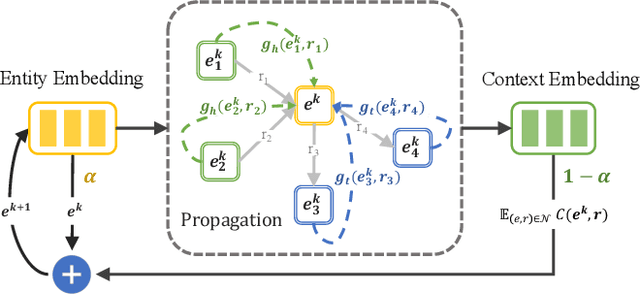

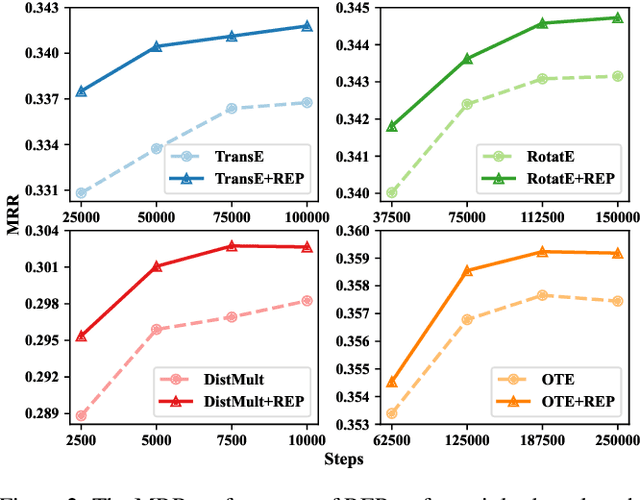
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.
NOTE: Solution for KDD-CUP 2021 WikiKG90M-LSC
Jul 05, 2021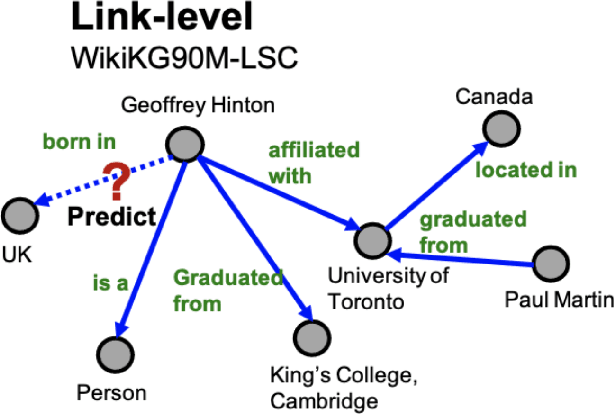

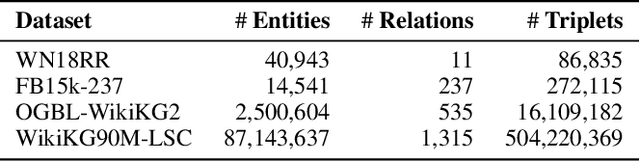
WikiKG90M in KDD Cup 2021 is a large encyclopedic knowledge graph, which could benefit various downstream applications such as question answering and recommender systems. Participants are invited to complete the knowledge graph by predicting missing triplets. Recent representation learning methods have achieved great success on standard datasets like FB15k-237. Thus, we train the advanced algorithms in different domains to learn the triplets, including OTE, QuatE, RotatE and TransE. Significantly, we modified OTE into NOTE (short for Norm-OTE) for better performance. Besides, we use both the DeepWalk and the post-smoothing technique to capture the graph structure for supplementation. In addition to the representations, we also use various statistical probabilities among the head entities, the relations and the tail entities for the final prediction. Experimental results show that the ensemble of state-of-the-art representation learning methods could draw on each others strengths. And we develop feature engineering from validation candidates for further improvements. Please note that we apply the same strategy on the test set for final inference. And these features may not be practical in the real world when considering ranking against all the entities.
An Adversarial Transfer Network for Knowledge Representation Learning
Apr 30, 2021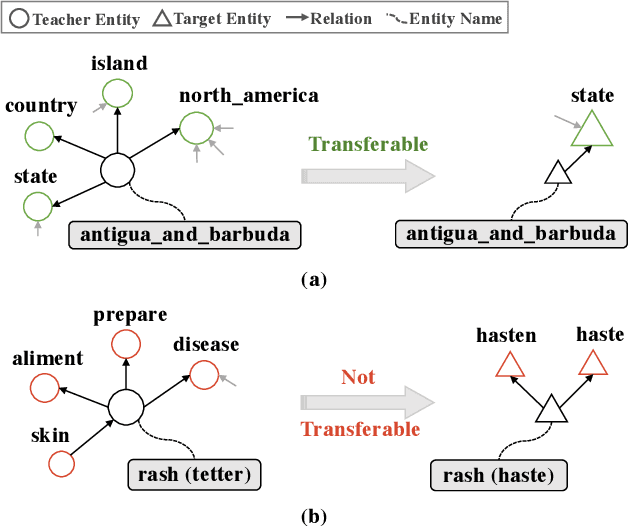
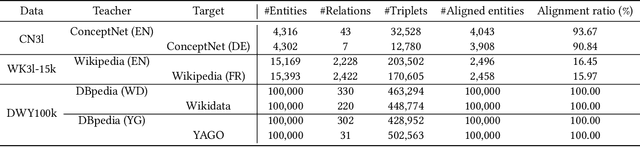
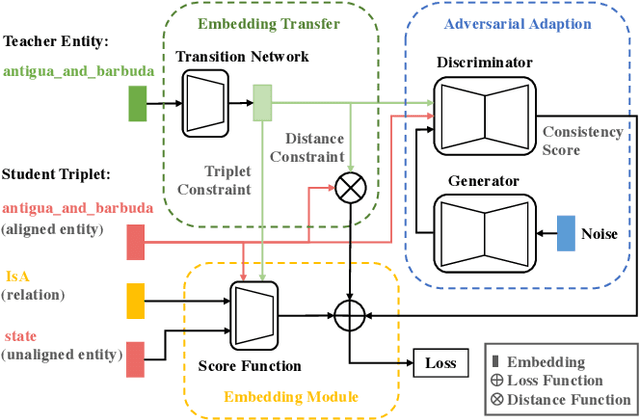

Knowledge representation learning has received a lot of attention in the past few years. The success of existing methods heavily relies on the quality of knowledge graphs. The entities with few triplets tend to be learned with less expressive power. Fortunately, there are many knowledge graphs constructed from various sources, the representations of which could contain much information. We propose an adversarial embedding transfer network ATransN, which transfers knowledge from one or more teacher knowledge graphs to a target one through an aligned entity set without explicit data leakage. Specifically, we add soft constraints on aligned entity pairs and neighbours to the existing knowledge representation learning methods. To handle the problem of possible distribution differences between teacher and target knowledge graphs, we introduce an adversarial adaption module. The discriminator of this module evaluates the degree of consistency between the embeddings of an aligned entity pair. The consistency score is then used as the weights of soft constraints. It is not necessary to acquire the relations and triplets in teacher knowledge graphs because we only utilize the entity representations. Knowledge graph completion results show that ATransN achieves better performance against baselines without transfer on three datasets, CN3l, WK3l, and DWY100k. The ablation study demonstrates that ATransN can bring steady and consistent improvement in different settings. The extension of combining other knowledge graph embedding algorithms and the extension with three teacher graphs display the promising generalization of the adversarial transfer network.