 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHICL: Hashtag-Driven In-Context Learning for Social Media Natural Language Understanding
Aug 19, 2023
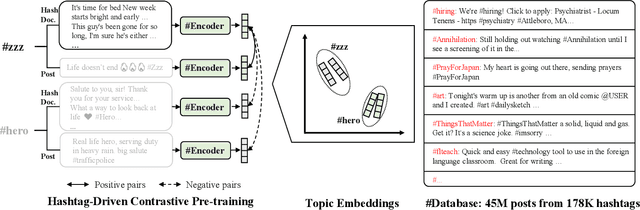
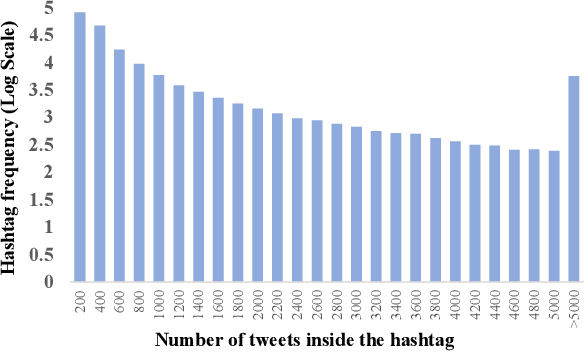
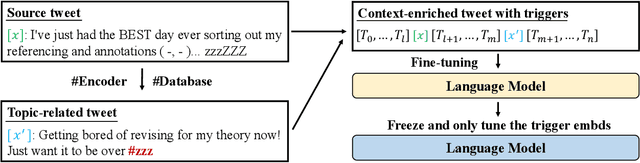
Natural language understanding (NLU) is integral to various social media applications. However, existing NLU models rely heavily on context for semantic learning, resulting in compromised performance when faced with short and noisy social media content. To address this issue, we leverage in-context learning (ICL), wherein language models learn to make inferences by conditioning on a handful of demonstrations to enrich the context and propose a novel hashtag-driven in-context learning (HICL) framework. Concretely, we pre-train a model #Encoder, which employs #hashtags (user-annotated topic labels) to drive BERT-based pre-training through contrastive learning. Our objective here is to enable #Encoder to gain the ability to incorporate topic-related semantic information, which allows it to retrieve topic-related posts to enrich contexts and enhance social media NLU with noisy contexts. To further integrate the retrieved context with the source text, we employ a gradient-based method to identify trigger terms useful in fusing information from both sources. For empirical studies, we collected 45M tweets to set up an in-context NLU benchmark, and the experimental results on seven downstream tasks show that HICL substantially advances the previous state-of-the-art results. Furthermore, we conducted extensive analyzes and found that: (1) combining source input with a top-retrieved post from #Encoder is more effective than using semantically similar posts; (2) trigger words can largely benefit in merging context from the source and retrieved posts.
Simple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022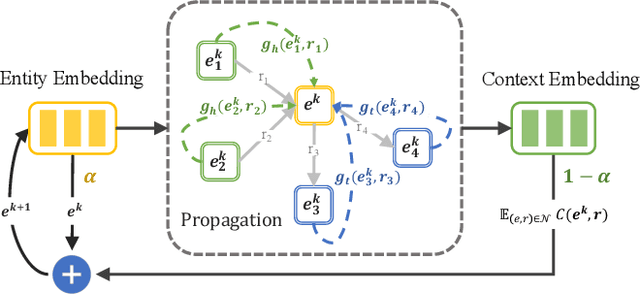

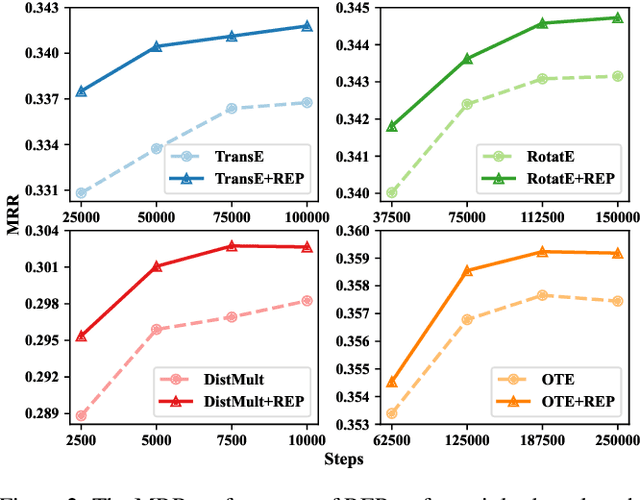
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.
NOTE: Solution for KDD-CUP 2021 WikiKG90M-LSC
Jul 05, 2021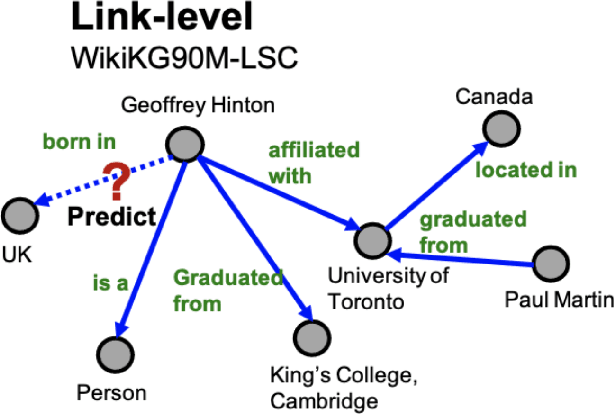

WikiKG90M in KDD Cup 2021 is a large encyclopedic knowledge graph, which could benefit various downstream applications such as question answering and recommender systems. Participants are invited to complete the knowledge graph by predicting missing triplets. Recent representation learning methods have achieved great success on standard datasets like FB15k-237. Thus, we train the advanced algorithms in different domains to learn the triplets, including OTE, QuatE, RotatE and TransE. Significantly, we modified OTE into NOTE (short for Norm-OTE) for better performance. Besides, we use both the DeepWalk and the post-smoothing technique to capture the graph structure for supplementation. In addition to the representations, we also use various statistical probabilities among the head entities, the relations and the tail entities for the final prediction. Experimental results show that the ensemble of state-of-the-art representation learning methods could draw on each others strengths. And we develop feature engineering from validation candidates for further improvements. Please note that we apply the same strategy on the test set for final inference. And these features may not be practical in the real world when considering ranking against all the entities.