 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022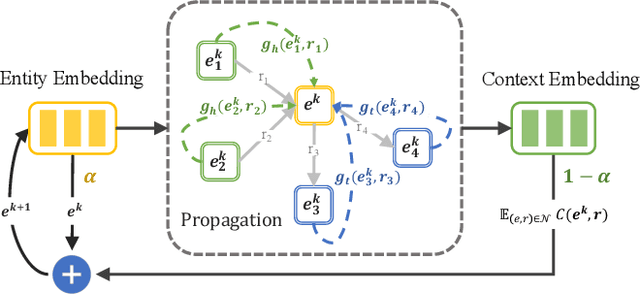

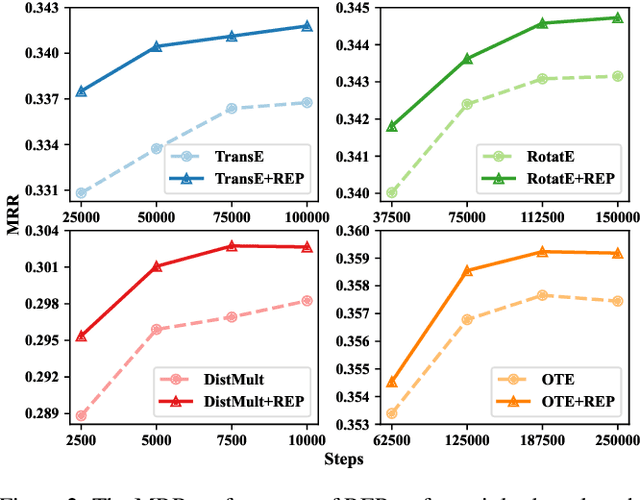
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.
Graph4Rec: A Universal Toolkit with Graph Neural Networks for Recommender Systems
Dec 08, 2021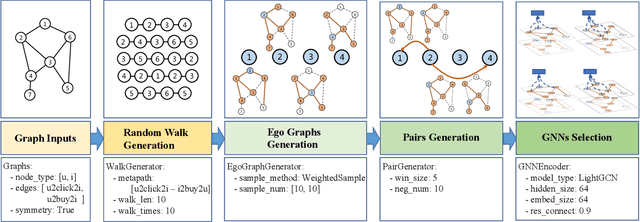

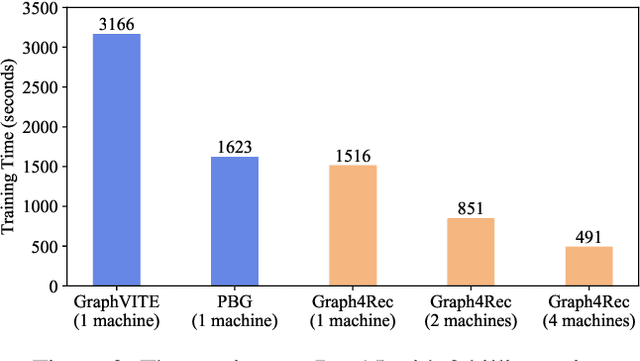

In recent years, owing to the outstanding performance in graph representation learning, graph neural network (GNN) techniques have gained considerable interests in many real-world scenarios, such as recommender systems and social networks. In recommender systems, the main challenge is to learn the effective user/item representations from their interactions. However, many recent publications using GNNs for recommender systems cannot be directly compared, due to their difference on datasets and evaluation metrics. Furthermore, many of them only provide a demo to conduct experiments on small datasets, which is far away to be applied in real-world recommender systems. To address this problem, we introduce Graph4Rec, a universal toolkit that unifies the paradigm to train GNN models into the following parts: graphs input, random walk generation, ego graphs generation, pairs generation and GNNs selection. From this training pipeline, one can easily establish his own GNN model with a few configurations. Besides, we develop a large-scale graph engine and a parameter server to support distributed GNN training. We conduct a systematic and comprehensive experiment to compare the performance of different GNN models on several scenarios in different scale. Extensive experiments are demonstrated to identify the key components of GNNs. We also try to figure out how the sparse and dense parameters affect the performance of GNNs. Finally, we investigate methods including negative sampling, ego graph construction order, and warm start strategy to find a more effective and efficient GNNs practice on recommender systems. Our toolkit is based on PGL https://github.com/PaddlePaddle/PGL and the code is opened source in https://github.com/PaddlePaddle/PGL/tree/main/apps/Graph4Rec.
NOTE: Solution for KDD-CUP 2021 WikiKG90M-LSC
Jul 05, 2021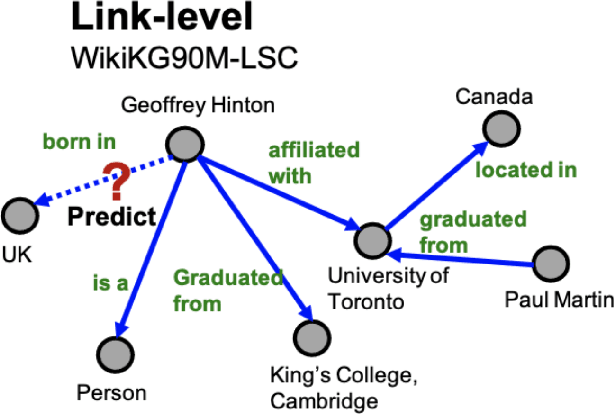

WikiKG90M in KDD Cup 2021 is a large encyclopedic knowledge graph, which could benefit various downstream applications such as question answering and recommender systems. Participants are invited to complete the knowledge graph by predicting missing triplets. Recent representation learning methods have achieved great success on standard datasets like FB15k-237. Thus, we train the advanced algorithms in different domains to learn the triplets, including OTE, QuatE, RotatE and TransE. Significantly, we modified OTE into NOTE (short for Norm-OTE) for better performance. Besides, we use both the DeepWalk and the post-smoothing technique to capture the graph structure for supplementation. In addition to the representations, we also use various statistical probabilities among the head entities, the relations and the tail entities for the final prediction. Experimental results show that the ensemble of state-of-the-art representation learning methods could draw on each others strengths. And we develop feature engineering from validation candidates for further improvements. Please note that we apply the same strategy on the test set for final inference. And these features may not be practical in the real world when considering ranking against all the entities.
LiteGEM: Lite Geometry Enhanced Molecular Representation Learning for Quantum Property Prediction
Jun 28, 2021

In this report, we (SuperHelix team) present our solution to KDD Cup 2021-PCQM4M-LSC, a large-scale quantum chemistry dataset on predicting HOMO-LUMO gap of molecules. Our solution, Lite Geometry Enhanced Molecular representation learning (LiteGEM) achieves a mean absolute error (MAE) of 0.1204 on the test set with the help of deep graph neural networks and various self-supervised learning tasks. The code of the framework can be found in https://github.com/PaddlePaddle/PaddleHelix/tree/dev/competition/kddcup2021-PCQM4M-LSC/.
ERNIE-Tiny : A Progressive Distillation Framework for Pretrained Transformer Compression
Jun 04, 2021
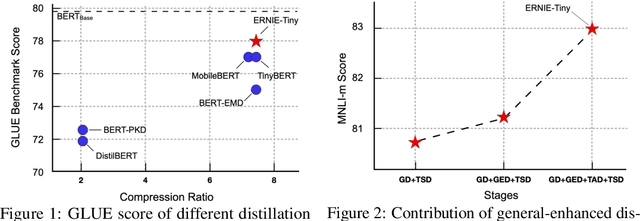
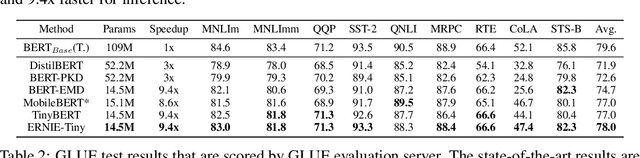
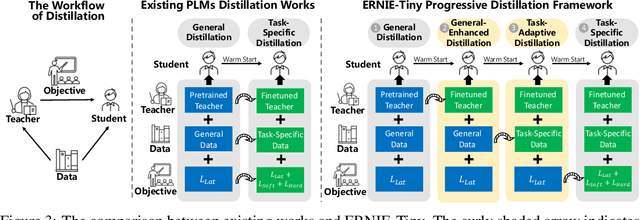
Pretrained language models (PLMs) such as BERT adopt a training paradigm which first pretrain the model in general data and then finetune the model on task-specific data, and have recently achieved great success. However, PLMs are notorious for their enormous parameters and hard to be deployed on real-life applications. Knowledge distillation has been prevailing to address this problem by transferring knowledge from a large teacher to a much smaller student over a set of data. We argue that the selection of thee three key components, namely teacher, training data, and learning objective, is crucial to the effectiveness of distillation. We, therefore, propose a four-stage progressive distillation framework ERNIE-Tiny to compress PLM, which varies the three components gradually from general level to task-specific level. Specifically, the first stage, General Distillation, performs distillation with guidance from pretrained teacher, gerenal data and latent distillation loss. Then, General-Enhanced Distillation changes teacher model from pretrained teacher to finetuned teacher. After that, Task-Adaptive Distillation shifts training data from general data to task-specific data. In the end, Task-Specific Distillation, adds two additional losses, namely Soft-Label and Hard-Label loss onto the last stage. Empirical results demonstrate the effectiveness of our framework and generalization gain brought by ERNIE-Tiny.In particular, experiments show that a 4-layer ERNIE-Tiny maintains over 98.0%performance of its 12-layer teacher BERT base on GLUE benchmark, surpassing state-of-the-art (SOTA) by 1.0% GLUE score with the same amount of parameters. Moreover, ERNIE-Tiny achieves a new compression SOTA on five Chinese NLP tasks, outperforming BERT base by 0.4% accuracy with 7.5x fewer parameters and9.4x faster inference speed.
kk2018 at SemEval-2020 Task 9: Adversarial Training for Code-Mixing Sentiment Classification
Sep 09, 2020
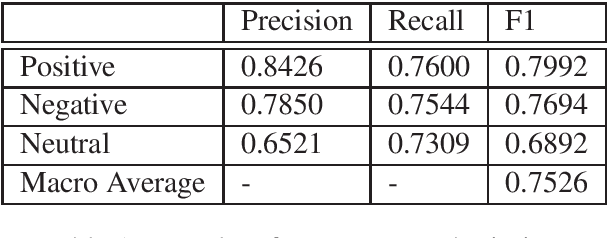
Code switching is a linguistic phenomenon that may occur within a multilingual setting where speakers share more than one language. With the increasing communication between groups with different languages, this phenomenon is more and more popular. However, there are little research and data in this area, especially in code-mixing sentiment classification. In this work, the domain transfer learning from state-of-the-art uni-language model ERNIE is tested on the code-mixing dataset, and surprisingly, a strong baseline is achieved. Furthermore, the adversarial training with a multi-lingual model is used to achieve 1st place of SemEval-2020 Task 9 Hindi-English sentiment classification competition.
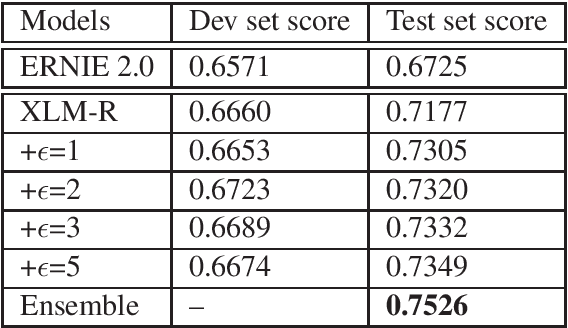
ERNIE at SemEval-2020 Task 10: Learning Word Emphasis Selection by Pre-trained Language Model
Sep 08, 2020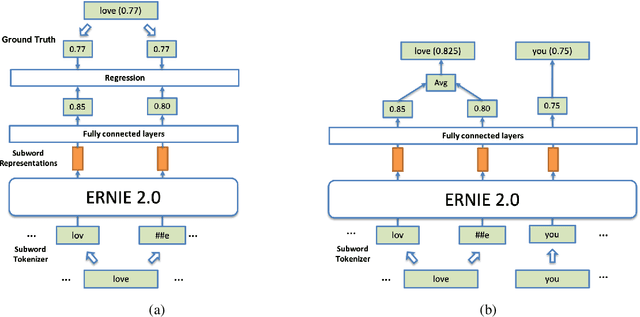

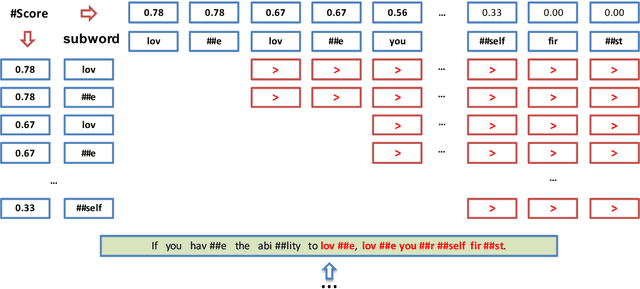

This paper describes the system designed by ERNIE Team which achieved the first place in SemEval-2020 Task 10: Emphasis Selection For Written Text in Visual Media. Given a sentence, we are asked to find out the most important words as the suggestion for automated design. We leverage the unsupervised pre-training model and finetune these models on our task. After our investigation, we found that the following models achieved an excellent performance in this task: ERNIE 2.0, XLM-ROBERTA, ROBERTA and ALBERT. We combine a pointwise regression loss and a pairwise ranking loss which is more close to the final M atchm metric to finetune our models. And we also find that additional feature engineering and data augmentation can help improve the performance. Our best model achieves the highest score of 0.823 and ranks first for all kinds of metrics