 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Simple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022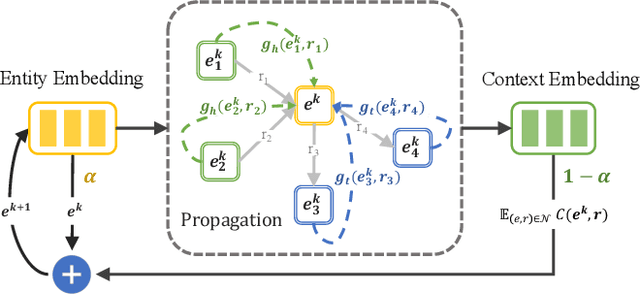

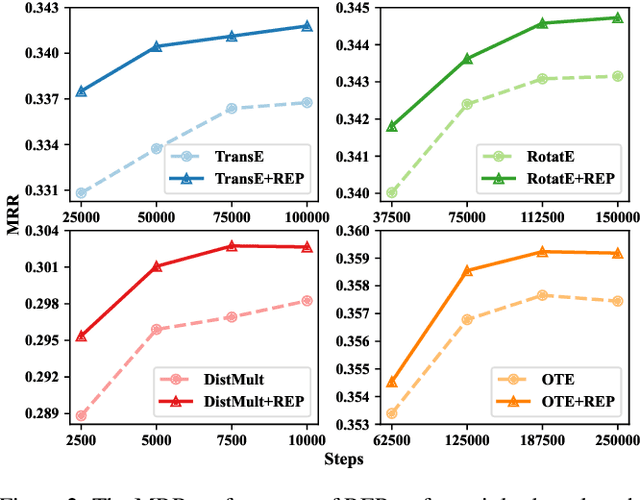
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.
NOTE: Solution for KDD-CUP 2021 WikiKG90M-LSC
Jul 05, 2021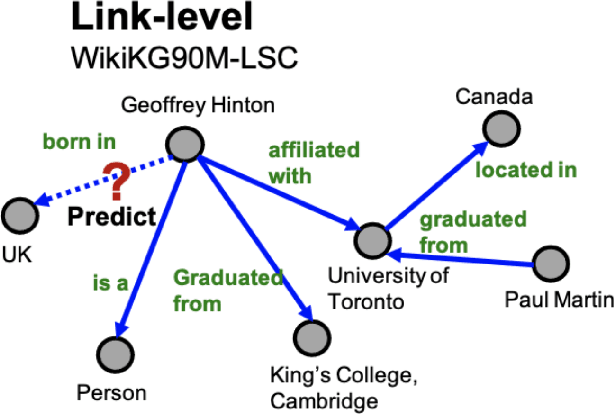

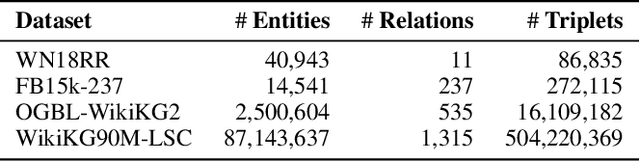
WikiKG90M in KDD Cup 2021 is a large encyclopedic knowledge graph, which could benefit various downstream applications such as question answering and recommender systems. Participants are invited to complete the knowledge graph by predicting missing triplets. Recent representation learning methods have achieved great success on standard datasets like FB15k-237. Thus, we train the advanced algorithms in different domains to learn the triplets, including OTE, QuatE, RotatE and TransE. Significantly, we modified OTE into NOTE (short for Norm-OTE) for better performance. Besides, we use both the DeepWalk and the post-smoothing technique to capture the graph structure for supplementation. In addition to the representations, we also use various statistical probabilities among the head entities, the relations and the tail entities for the final prediction. Experimental results show that the ensemble of state-of-the-art representation learning methods could draw on each others strengths. And we develop feature engineering from validation candidates for further improvements. Please note that we apply the same strategy on the test set for final inference. And these features may not be practical in the real world when considering ranking against all the entities.