 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More with Less: A Dynamic Dual-Level Down-Sampling Framework for Efficient Policy Optimization
Sep 26, 2025Critic-free methods like GRPO reduce memory demands by estimating advantages from multiple rollouts but tend to converge slowly, as critical learning signals are diluted by an abundance of uninformative samples and tokens. To tackle this challenge, we propose the \textbf{Dynamic Dual-Level Down-Sampling (D$^3$S)} framework that prioritizes the most informative samples and tokens across groups to improve the efficient of policy optimization. D$^3$S operates along two levels: (1) the sample-level, which selects a subset of rollouts to maximize advantage variance ($\text{Var}(A)$). We theoretically proven that this selection is positively correlated with the upper bound of the policy gradient norms, yielding higher policy gradients. (2) the token-level, which prioritizes tokens with a high product of advantage magnitude and policy entropy ($|A_{i,t}|\times H_{i,t}$), focusing updates on tokens where the policy is both uncertain and impactful. Moreover, to prevent overfitting to high-signal data, D$^3$S employs a dynamic down-sampling schedule inspired by curriculum learning. This schedule starts with aggressive down-sampling to accelerate early learning and gradually relaxes to promote robust generalization. Extensive experiments on Qwen2.5 and Llama3.1 demonstrate that integrating D$^3$S into advanced RL algorithms achieves state-of-the-art performance and generalization while requiring \textit{fewer} samples and tokens across diverse reasoning benchmarks. Our code is added in the supplementary materials and will be made publicly available.
WeChat-YATT: A Simple, Scalable and Balanced RLHF Trainer
Aug 11, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent paradigm for training large language models and multimodal systems. Despite notable advances enabled by existing RLHF training frameworks, significant challenges remain in scaling to complex multimodal workflows and adapting to dynamic workloads. In particular, current systems often encounter limitations related to controller scalability when managing large models, as well as inefficiencies in orchestrating intricate RLHF pipelines, especially in scenarios that require dynamic sampling and resource allocation. In this paper, we introduce WeChat-YATT (Yet Another Transformer Trainer in WeChat), a simple, scalable, and balanced RLHF training framework specifically designed to address these challenges. WeChat-YATT features a parallel controller programming model that enables flexible and efficient orchestration of complex RLHF workflows, effectively mitigating the bottlenecks associated with centralized controller architectures and facilitating scalability in large-scale data scenarios. In addition, we propose a dynamic placement schema that adaptively partitions computational resources and schedules workloads, thereby significantly reducing hardware idle time and improving GPU utilization under variable training conditions. We evaluate WeChat-YATT across a range of experimental scenarios, demonstrating that it achieves substantial improvements in throughput compared to state-of-the-art RLHF training frameworks. Furthermore, WeChat-YATT has been successfully deployed to train models supporting WeChat product features for a large-scale user base, underscoring its effectiveness and robustness in real-world applications.
G-Core: A Simple, Scalable and Balanced RLHF Trainer
Jul 30, 2025Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
May 18, 2022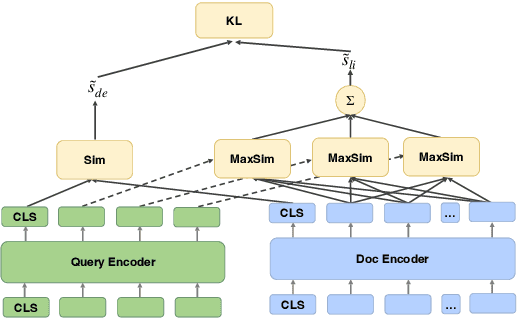

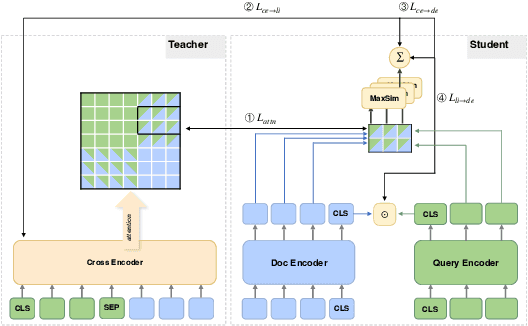
Neural retrievers based on pre-trained language models (PLMs), such as dual-encoders, have achieved promising performance on the task of open-domain question answering (QA). Their effectiveness can further reach new state-of-the-arts by incorporating cross-architecture knowledge distillation. However, most of the existing studies just directly apply conventional distillation methods. They fail to consider the particular situation where the teacher and student have different structures. In this paper, we propose a novel distillation method that significantly advances cross-architecture distillation for dual-encoders. Our method 1) introduces a self on-the-fly distillation method that can effectively distill late interaction (i.e., ColBERT) to vanilla dual-encoder, and 2) incorporates a cascade distillation process to further improve the performance with a cross-encoder teacher. Extensive experiments are conducted to validate that our proposed solution outperforms strong baselines and establish a new state-of-the-art on open-domain QA benchmarks.
ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Applications in Baidu Maps
Apr 06, 2022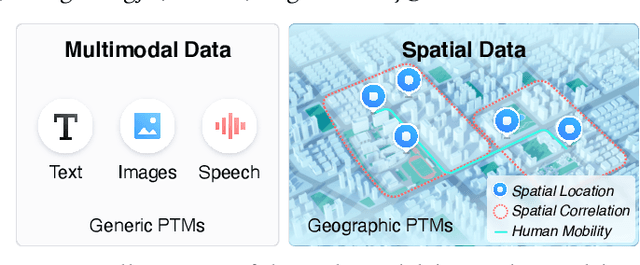

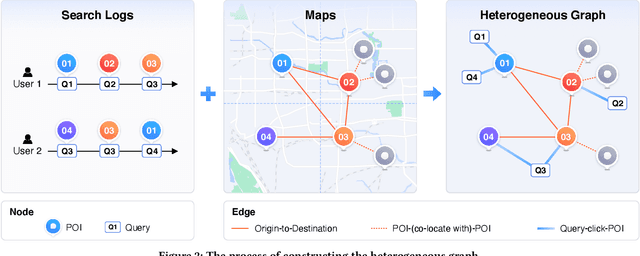
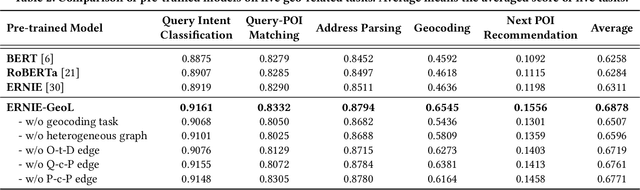
Pre-trained models (PTMs) have become a fundamental backbone for downstream tasks in natural language processing and computer vision. Despite initial gains that were obtained by applying generic PTMs to geo-related tasks at Baidu Maps, a clear performance plateau over time was observed. One of the main reasons for this plateau is the lack of readily available geographic knowledge in generic PTMs. To address this problem, in this paper, we present ERNIE-GeoL, which is a geography-and-language pre-trained model designed and developed for improving the geo-related tasks at Baidu Maps. ERNIE-GeoL is elaborately designed to learn a universal representation of geography-language by pre-training on large-scale data generated from a heterogeneous graph that contains abundant geographic knowledge. Extensive quantitative and qualitative experiments conducted on large-scale real-world datasets demonstrate the superiority and effectiveness of ERNIE-GeoL. ERNIE-GeoL has already been deployed in production at Baidu Maps since April 2021, which significantly benefits the performance of a wide range of downstream tasks. This demonstrates that ERNIE-GeoL can serve as a fundamental backbone for geo-related tasks.
NOTE: Solution for KDD-CUP 2021 WikiKG90M-LSC
Jul 05, 2021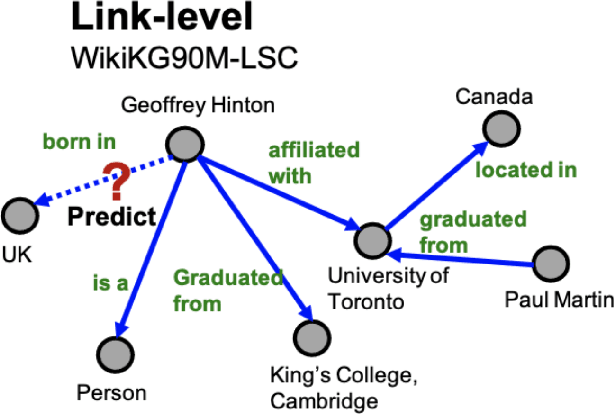

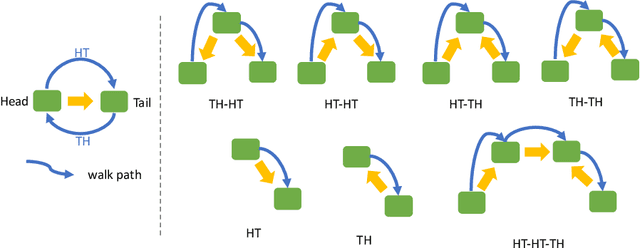
WikiKG90M in KDD Cup 2021 is a large encyclopedic knowledge graph, which could benefit various downstream applications such as question answering and recommender systems. Participants are invited to complete the knowledge graph by predicting missing triplets. Recent representation learning methods have achieved great success on standard datasets like FB15k-237. Thus, we train the advanced algorithms in different domains to learn the triplets, including OTE, QuatE, RotatE and TransE. Significantly, we modified OTE into NOTE (short for Norm-OTE) for better performance. Besides, we use both the DeepWalk and the post-smoothing technique to capture the graph structure for supplementation. In addition to the representations, we also use various statistical probabilities among the head entities, the relations and the tail entities for the final prediction. Experimental results show that the ensemble of state-of-the-art representation learning methods could draw on each others strengths. And we develop feature engineering from validation candidates for further improvements. Please note that we apply the same strategy on the test set for final inference. And these features may not be practical in the real world when considering ranking against all the entities.
Masked Label Prediction: Unified Massage Passing Model for Semi-Supervised Classification
Sep 09, 2020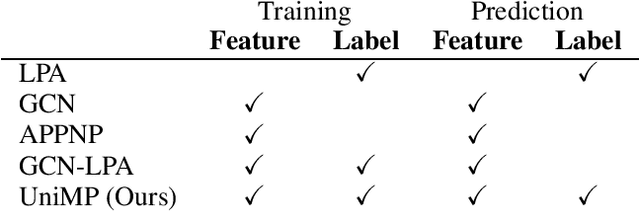

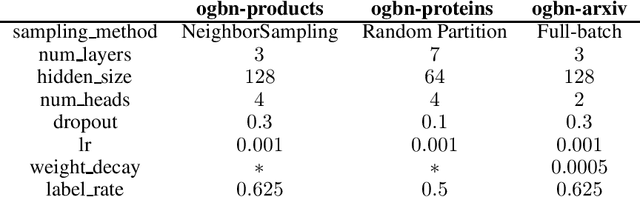
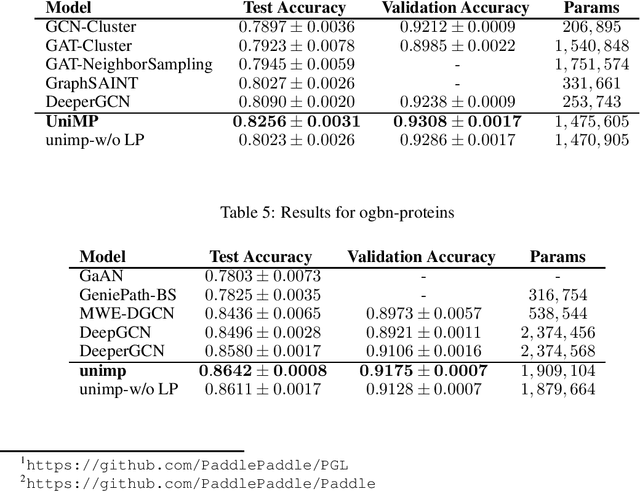
Graph convolutional network (GCN) and label propagation algorithms (LPA) are both message passing algorithms, which have achieved superior performance in semi-supervised classification. But GCN performs feature propagation by a neural network to make predictions, while LPA uses label propagation across graph adjacency matrix to get results. However, there is still no good way to combine these two kinds of algorithms. In this paper, we proposed a new Unified Massage Passaging model (UniMP) that can incorporate feature propagation and label propagation with a shared message passing network, providing a better performance in semi-supervised classification. First, we adopt a graph Transformer network jointly label embedding to propagate both the feature and label information. Second, to train UniMP without overfitting in self-loop label information, we propose a masked label prediction method, in which some per-entage of training examples are simply masked at random, and then predicted. UniMP conceptually unifies feature propagation and label propagation and be empirically powerful. It obtains new state-of-the-art semi-supervised classification results in Open Graph Benchmark (OGB). Our implementation is available online https://github.com/PaddlePaddle/PGL/tree/main/ ogb_examples/nodeproppred/unimp.