 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
Paper and Code
May 18, 2022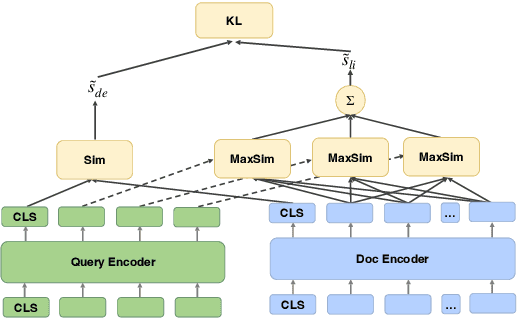

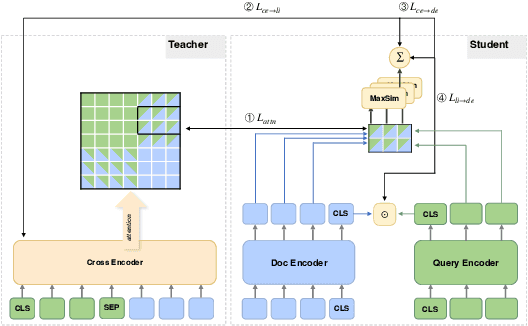
Neural retrievers based on pre-trained language models (PLMs), such as dual-encoders, have achieved promising performance on the task of open-domain question answering (QA). Their effectiveness can further reach new state-of-the-arts by incorporating cross-architecture knowledge distillation. However, most of the existing studies just directly apply conventional distillation methods. They fail to consider the particular situation where the teacher and student have different structures. In this paper, we propose a novel distillation method that significantly advances cross-architecture distillation for dual-encoders. Our method 1) introduces a self on-the-fly distillation method that can effectively distill late interaction (i.e., ColBERT) to vanilla dual-encoder, and 2) incorporates a cascade distillation process to further improve the performance with a cross-encoder teacher. Extensive experiments are conducted to validate that our proposed solution outperforms strong baselines and establish a new state-of-the-art on open-domain QA benchmarks.