 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
Sep 05, 2024



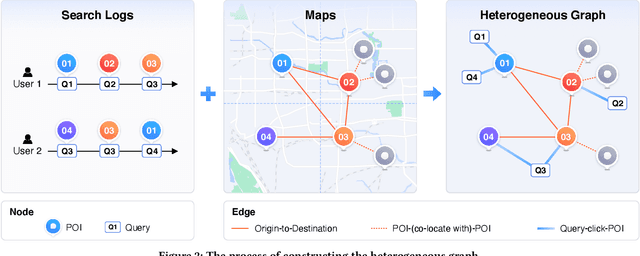
The increasing interest in international travel has raised the demand of retrieving point of interests in multiple languages. This is even superior to find local venues such as restaurants and scenic spots in unfamiliar languages when traveling abroad. Multilingual POI retrieval, enabling users to find desired POIs in a demanded language using queries in numerous languages, has become an indispensable feature of today's global map applications such as Baidu Maps. This task is non-trivial because of two key challenges: (1) visiting sparsity and (2) multilingual query-POI matching. To this end, we propose a Heterogeneous Graph Attention Matching Network (HGAMN) to concurrently address both challenges. Specifically, we construct a heterogeneous graph that contains two types of nodes: POI node and query node using the search logs of Baidu Maps. To alleviate challenge \#1, we construct edges between different POI nodes to link the low-frequency POIs with the high-frequency ones, which enables the transfer of knowledge from the latter to the former. To mitigate challenge \#2, we construct edges between POI and query nodes based on the co-occurrences between queries and POIs, where queries in different languages and formulations can be aggregated for individual POIs. Moreover, we develop an attention-based network to jointly learn node representations of the heterogeneous graph and further design a cross-attention module to fuse the representations of both types of nodes for query-POI relevance scoring. Extensive experiments conducted on large-scale real-world datasets from Baidu Maps demonstrate the superiority and effectiveness of HGAMN. In addition, HGAMN has already been deployed in production at Baidu Maps, and it successfully keeps serving hundreds of millions of requests every day.
ERNIE-GeoL: A Geography-and-Language Pre-trained Model and its Applications in Baidu Maps
Apr 06, 2022

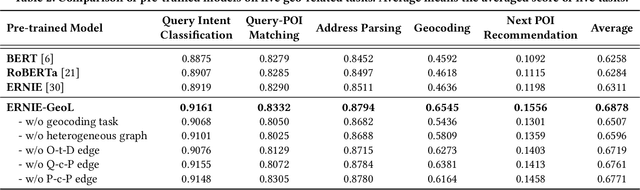
Pre-trained models (PTMs) have become a fundamental backbone for downstream tasks in natural language processing and computer vision. Despite initial gains that were obtained by applying generic PTMs to geo-related tasks at Baidu Maps, a clear performance plateau over time was observed. One of the main reasons for this plateau is the lack of readily available geographic knowledge in generic PTMs. To address this problem, in this paper, we present ERNIE-GeoL, which is a geography-and-language pre-trained model designed and developed for improving the geo-related tasks at Baidu Maps. ERNIE-GeoL is elaborately designed to learn a universal representation of geography-language by pre-training on large-scale data generated from a heterogeneous graph that contains abundant geographic knowledge. Extensive quantitative and qualitative experiments conducted on large-scale real-world datasets demonstrate the superiority and effectiveness of ERNIE-GeoL. ERNIE-GeoL has already been deployed in production at Baidu Maps since April 2021, which significantly benefits the performance of a wide range of downstream tasks. This demonstrates that ERNIE-GeoL can serve as a fundamental backbone for geo-related tasks.
GEDIT: Geographic-Enhanced and Dependency-Guided Tagging for Joint POI and Accessibility Extraction at Baidu Maps
Aug 20, 2021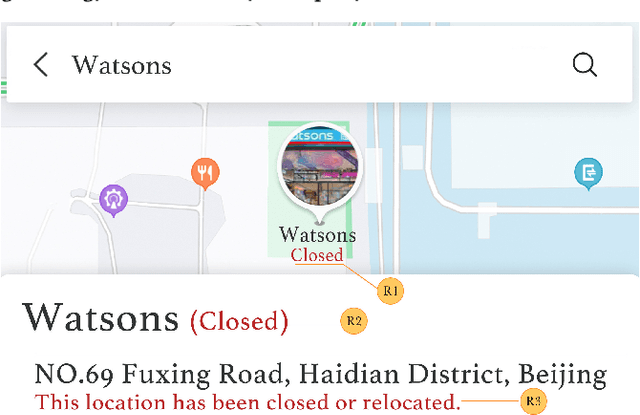

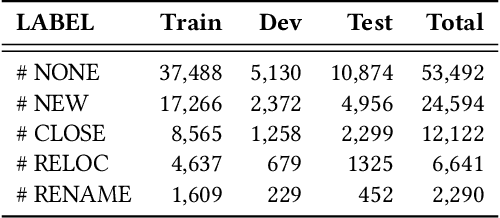

Providing timely accessibility reminders of a point-of-interest (POI) plays a vital role in improving user satisfaction of finding places and making visiting decisions. However, it is difficult to keep the POI database in sync with the real-world counterparts due to the dynamic nature of business changes. To alleviate this problem, we formulate and present a practical solution that jointly extracts POI mentions and identifies their coupled accessibility labels from unstructured text. We approach this task as a sequence tagging problem, where the goal is to produce <POI name, accessibility label> pairs from unstructured text. This task is challenging because of two main issues: (1) POI names are often newly-coined words so as to successfully register new entities or brands and (2) there may exist multiple pairs in the text, which necessitates dealing with one-to-many or many-to-one mapping to make each POI coupled with its accessibility label. To this end, we propose a Geographic-Enhanced and Dependency-guIded sequence Tagging (GEDIT) model to concurrently address the two challenges. First, to alleviate challenge #1, we develop a geographic-enhanced pre-trained model to learn the text representations. Second, to mitigate challenge #2, we apply a relational graph convolutional network to learn the tree node representations from the parsed dependency tree. Finally, we construct a neural sequence tagging model by integrating and feeding the previously pre-learned representations into a CRF layer. Extensive experiments conducted on a real-world dataset demonstrate the superiority and effectiveness of GEDIT. In addition, it has already been deployed in production at Baidu Maps. Statistics show that the proposed solution can save significant human effort and labor costs to deal with the same amount of documents, which confirms that it is a practical way for POI accessibility maintenance.
Learning to Select Bi-Aspect Information for Document-Scale Text Content Manipulation
Feb 24, 2020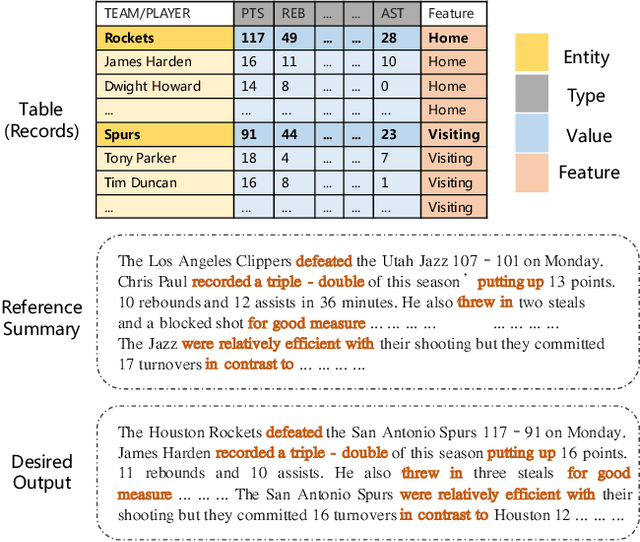
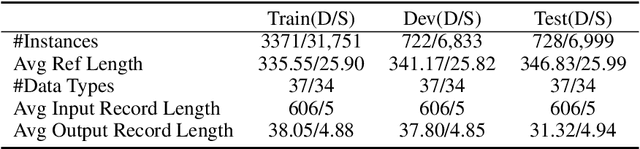
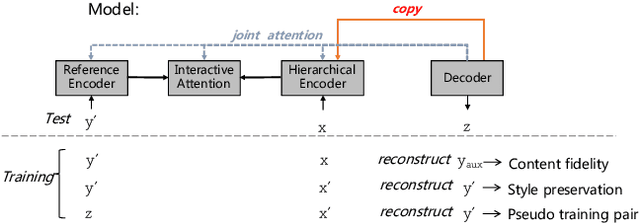

In this paper, we focus on a new practical task, document-scale text content manipulation, which is the opposite of text style transfer and aims to preserve text styles while altering the content. In detail, the input is a set of structured records and a reference text for describing another recordset. The output is a summary that accurately describes the partial content in the source recordset with the same writing style of the reference. The task is unsupervised due to lack of parallel data, and is challenging to select suitable records and style words from bi-aspect inputs respectively and generate a high-fidelity long document. To tackle those problems, we first build a dataset based on a basketball game report corpus as our testbed, and present an unsupervised neural model with interactive attention mechanism, which is used for learning the semantic relationship between records and reference texts to achieve better content transfer and better style preservation. In addition, we also explore the effectiveness of the back-translation in our task for constructing some pseudo-training pairs. Empirical results show superiority of our approaches over competitive methods, and the models also yield a new state-of-the-art result on a sentence-level dataset.
Keyphrase Extraction with Span-based Feature Representations
Feb 13, 2020
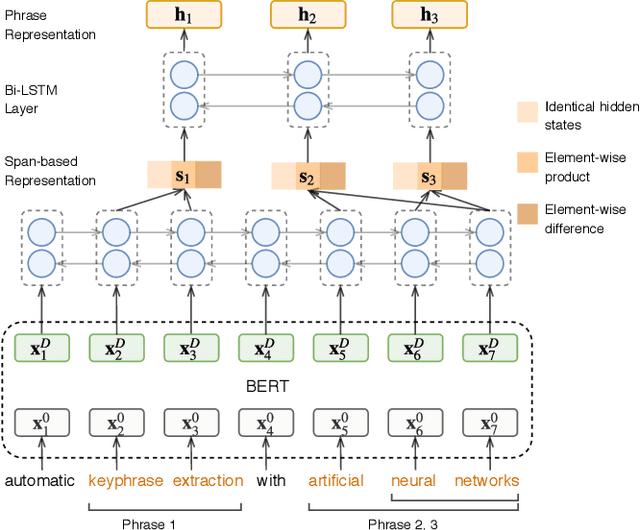

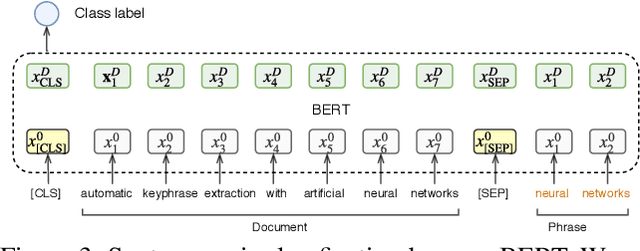
Keyphrases are capable of providing semantic metadata characterizing documents and producing an overview of the content of a document. Since keyphrase extraction is able to facilitate the management, categorization, and retrieval of information, it has received much attention in recent years. There are three approaches to address keyphrase extraction: (i) traditional two-step ranking method, (ii) sequence labeling and (iii) generation using neural networks. Two-step ranking approach is based on feature engineering, which is labor intensive and domain dependent. Sequence labeling is not able to tackle overlapping phrases. Generation methods (i.e., Sequence-to-sequence neural network models) overcome those shortcomings, so they have been widely studied and gain state-of-the-art performance. However, generation methods can not utilize context information effectively. In this paper, we propose a novelty Span Keyphrase Extraction model that extracts span-based feature representation of keyphrase directly from all the content tokens. In this way, our model obtains representation for each keyphrase and further learns to capture the interaction between keyphrases in one document to get better ranking results. In addition, with the help of tokens, our model is able to extract overlapped keyphrases. Experimental results on the benchmark datasets show that our proposed model outperforms the existing methods by a large margin.
Neural Semantic Parsing in Low-Resource Settings with Back-Translation and Meta-Learning
Sep 12, 2019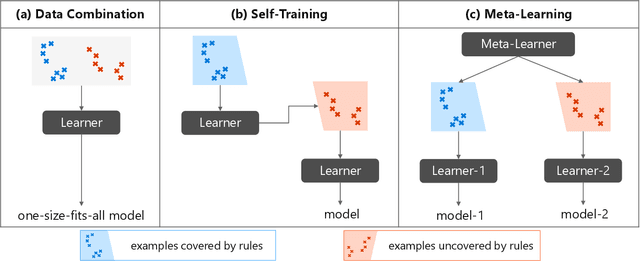
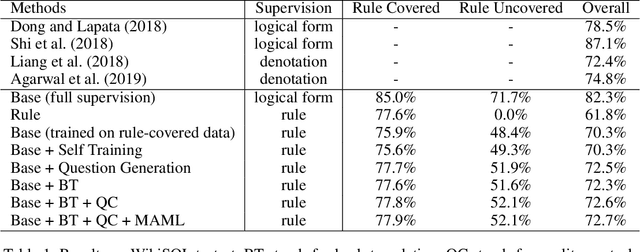

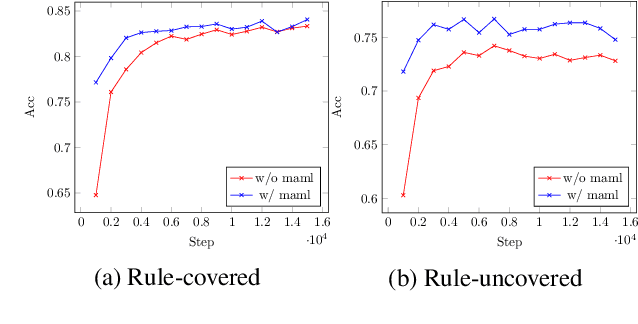
Neural semantic parsing has achieved impressive results in recent years, yet its success relies on the availability of large amounts of supervised data. Our goal is to learn a neural semantic parser when only prior knowledge about a limited number of simple rules is available, without access to either annotated programs or execution results. Our approach is initialized by rules, and improved in a back-translation paradigm using generated question-program pairs from the semantic parser and the question generator. A phrase table with frequent mapping patterns is automatically derived, also updated as training progresses, to measure the quality of generated instances. We train the model with model-agnostic meta-learning to guarantee the accuracy and stability on examples covered by rules, and meanwhile acquire the versatility to generalize well on examples uncovered by rules. Results on three benchmark datasets with different domains and programs show that our approach incrementally improves the accuracy. On WikiSQL, our best model is comparable to the SOTA system learned from denotations.
Knowledge-Aware Conversational Semantic Parsing Over Web Tables
Sep 12, 2018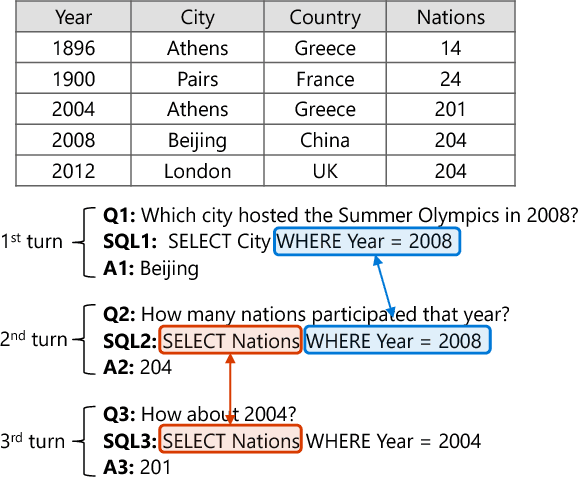



Conversational semantic parsing over tables requires knowledge acquiring and reasoning abilities, which have not been well explored by current state-of-the-art approaches. Motivated by this fact, we propose a knowledge-aware semantic parser to improve parsing performance by integrating various types of knowledge. In this paper, we consider three types of knowledge, including grammar knowledge, expert knowledge, and external resource knowledge. First, grammar knowledge empowers the model to effectively replicate previously generated logical form, which effectively handles the co-reference and ellipsis phenomena in conversation Second, based on expert knowledge, we propose a decomposable model, which is more controllable compared with traditional end-to-end models that put all the burdens of learning on trial-and-error in an end-to-end way. Third, external resource knowledge, i.e., provided by a pre-trained language model or an entity typing model, is used to improve the representation of question and table for a better semantic understanding. We conduct experiments on the SequentialQA dataset. Results show that our knowledge-aware model outperforms the state-of-the-art approaches. Incremental experimental results also prove the usefulness of various knowledge. Further analysis shows that our approach has the ability to derive the meaning representation of a context-dependent utterance by leveraging previously generated outcomes.
Knowledge Based Machine Reading Comprehension
Sep 12, 2018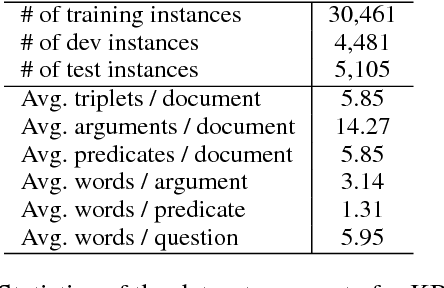
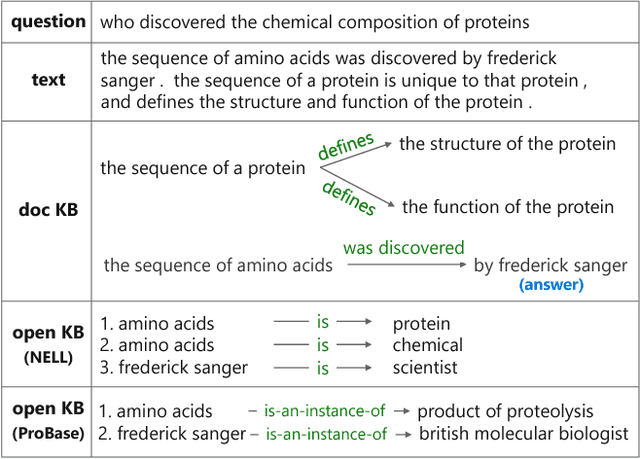
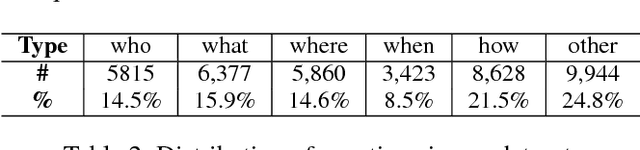
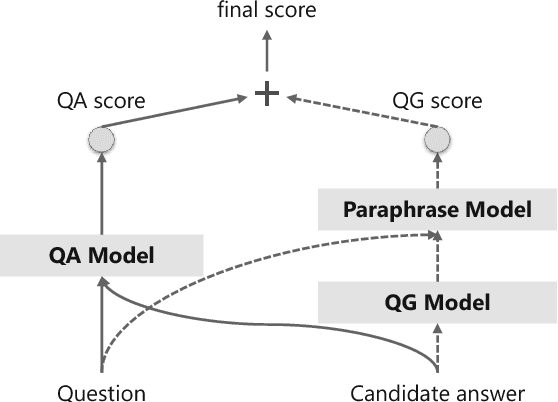
Machine reading comprehension (MRC) requires reasoning about both the knowledge involved in a document and knowledge about the world. However, existing datasets are typically dominated by questions that can be well solved by context matching, which fail to test this capability. To encourage the progress on knowledge-based reasoning in MRC, we present knowledge-based MRC in this paper, and build a new dataset consisting of 40,047 question-answer pairs. The annotation of this dataset is designed so that successfully answering the questions requires understanding and the knowledge involved in a document. We implement a framework consisting of both a question answering model and a question generation model, both of which take the knowledge extracted from the document as well as relevant facts from an external knowledge base such as Freebase/ProBase/Reverb/NELL. Results show that incorporating side information from external KB improves the accuracy of the baseline question answer system. We compare it with a standard MRC model BiDAF, and also provide the difficulty of the dataset and lay out remaining challenges.
Question Generation from SQL Queries Improves Neural Semantic Parsing
Aug 27, 2018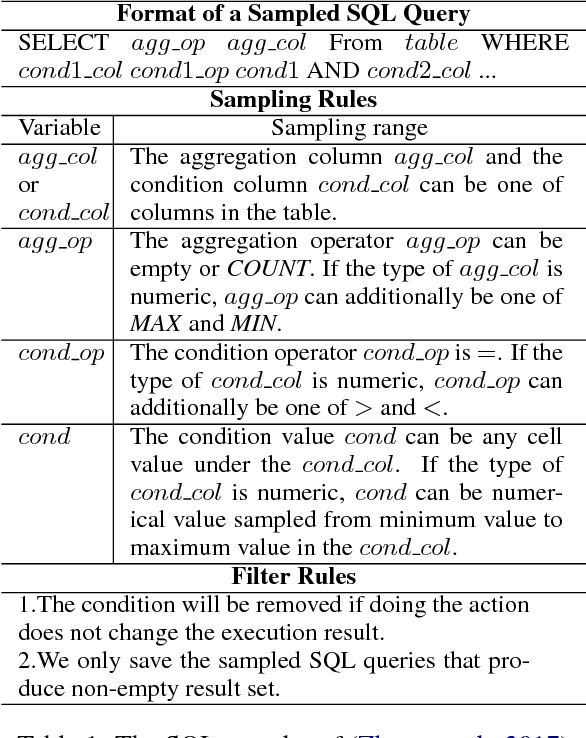



We study how to learn a semantic parser of state-of-the-art accuracy with less supervised training data. We conduct our study on WikiSQL, the largest hand-annotated semantic parsing dataset to date. First, we demonstrate that question generation is an effective method that empowers us to learn a state-of-the-art neural network based semantic parser with thirty percent of the supervised training data. Second, we show that applying question generation to the full supervised training data further improves the state-of-the-art model. In addition, we observe that there is a logarithmic relationship between the accuracy of a semantic parser and the amount of training data.
Semantic Parsing with Syntax- and Table-Aware SQL Generation
Apr 23, 2018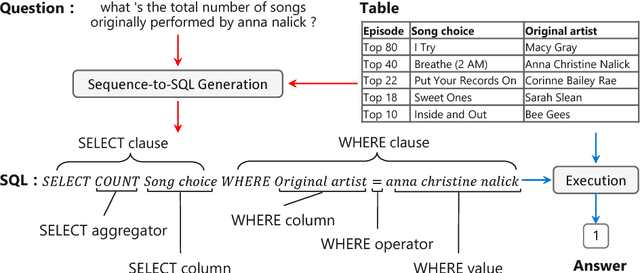
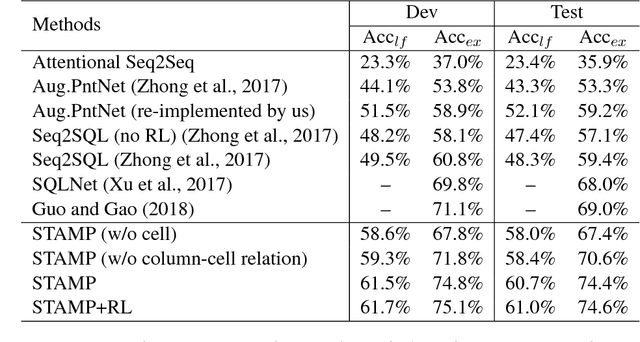
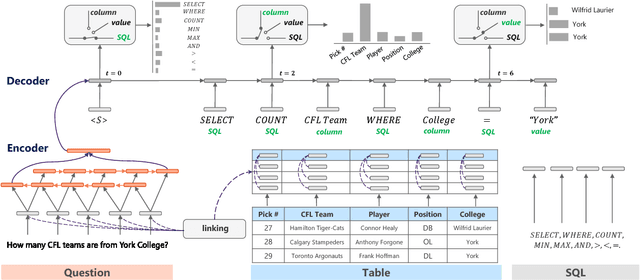
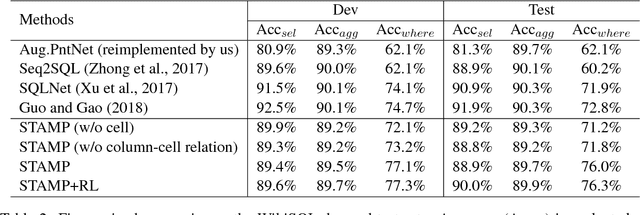
We present a generative model to map natural language questions into SQL queries. Existing neural network based approaches typically generate a SQL query word-by-word, however, a large portion of the generated results are incorrect or not executable due to the mismatch between question words and table contents. Our approach addresses this problem by considering the structure of table and the syntax of SQL language. The quality of the generated SQL query is significantly improved through (1) learning to replicate content from column names, cells or SQL keywords; and (2) improving the generation of WHERE clause by leveraging the column-cell relation. Experiments are conducted on WikiSQL, a recently released dataset with the largest question-SQL pairs. Our approach significantly improves the state-of-the-art execution accuracy from 69.0% to 74.4%.