 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebQA: Multihop and Multimodal QA
Sep 21, 2021
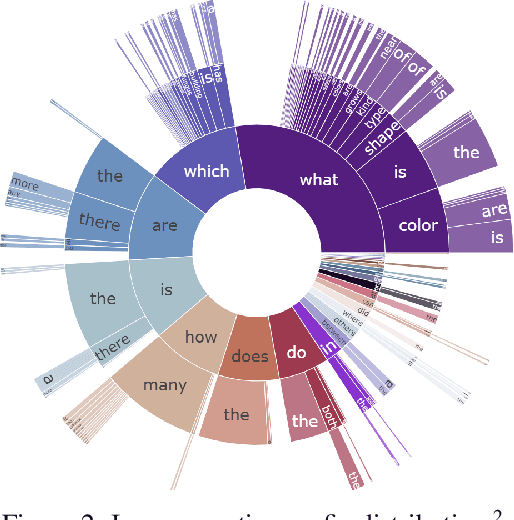


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020
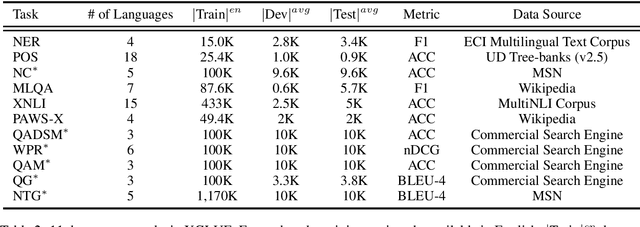
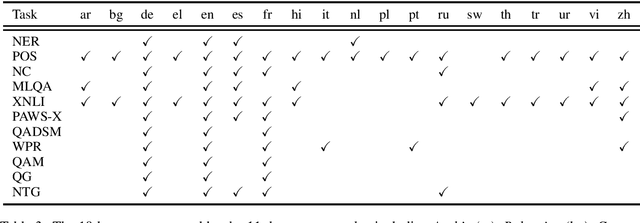
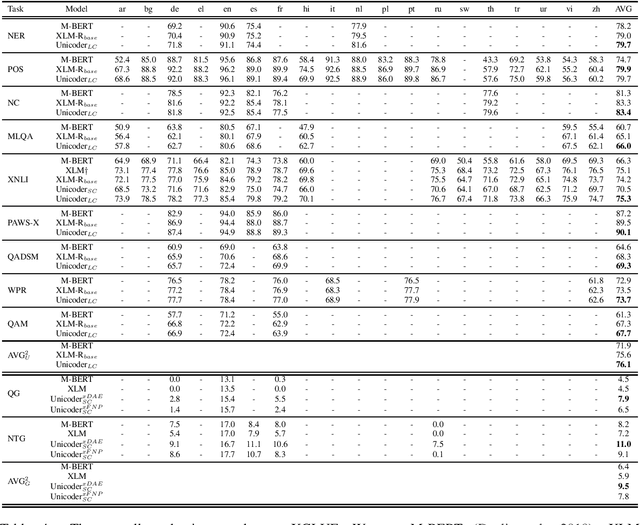
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
Pre-training Text Representations as Meta Learning
Apr 12, 2020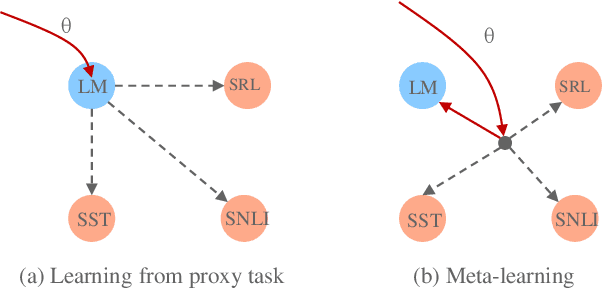
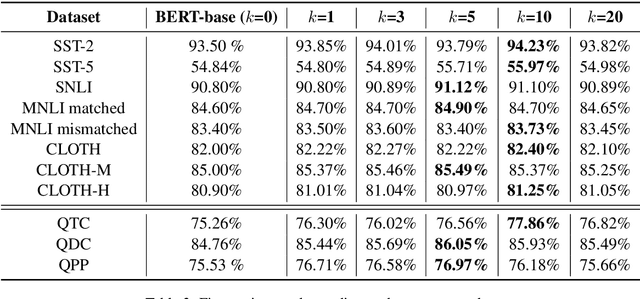
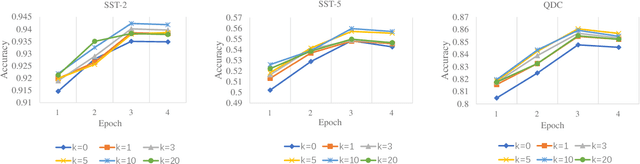
Pre-training text representations has recently been shown to significantly improve the state-of-the-art in many natural language processing tasks. The central goal of pre-training is to learn text representations that are useful for subsequent tasks. However, existing approaches are optimized by minimizing a proxy objective, such as the negative log likelihood of language modeling. In this work, we introduce a learning algorithm which directly optimizes model's ability to learn text representations for effective learning of downstream tasks. We show that there is an intrinsic connection between multi-task pre-training and model-agnostic meta-learning with a sequence of meta-train steps. The standard multi-task learning objective adopted in BERT is a special case of our learning algorithm where the depth of meta-train is zero. We study the problem in two settings: unsupervised pre-training and supervised pre-training with different pre-training objects to verify the generality of our approach.Experimental results show that our algorithm brings improvements and learns better initializations for a variety of downstream tasks.
The Microsoft Toolkit of Multi-Task Deep Neural Networks for Natural Language Understanding
Feb 19, 2020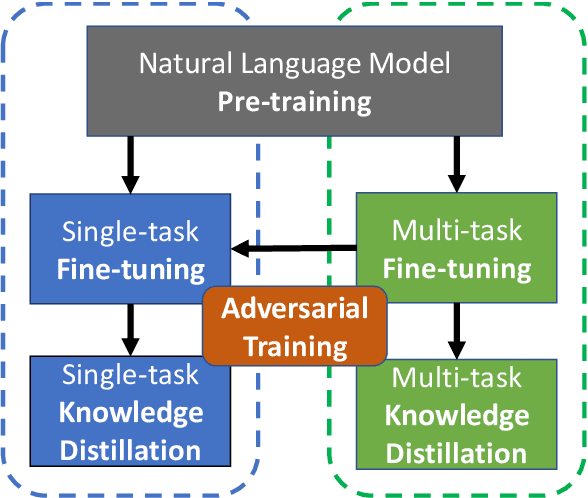
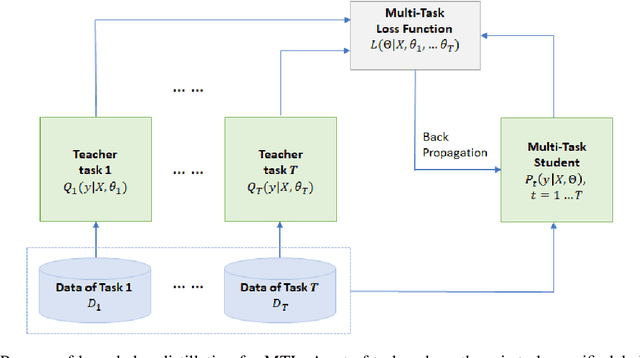
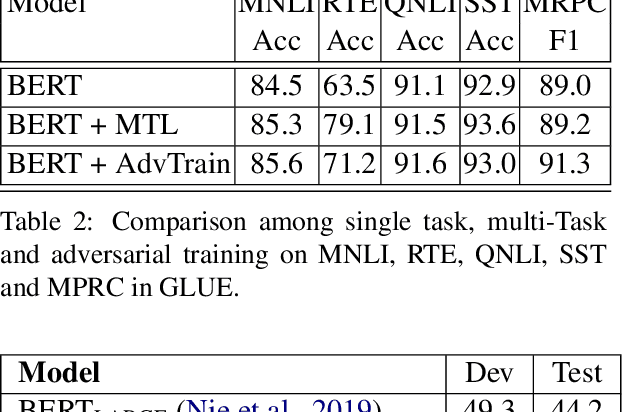
We present MT-DNN, an open-source natural language understanding (NLU) toolkit that makes it easy for researchers and developers to train customized deep learning models. Built upon PyTorch and Transformers, MT-DNN is designed to facilitate rapid customization for a broad spectrum of NLU tasks, using a variety of objectives (classification, regression, structured prediction) and text encoders (e.g., RNNs, BERT, RoBERTa, UniLM). A unique feature of MT-DNN is its built-in support for robust and transferable learning using the adversarial multi-task learning paradigm. To enable efficient production deployment, MT-DNN supports multi-task knowledge distillation, which can substantially compress a deep neural model without significant performance drop. We demonstrate the effectiveness of MT-DNN on a wide range of NLU applications across general and biomedical domains. The software and pre-trained models will be publicly available at https://github.com/namisan/mt-dnn.
K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters
Feb 10, 2020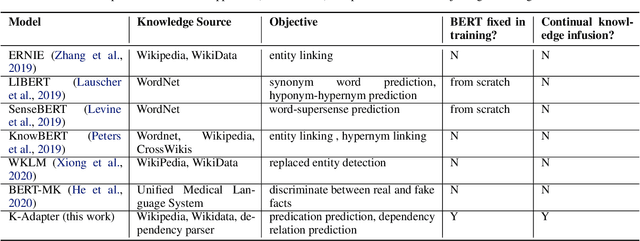
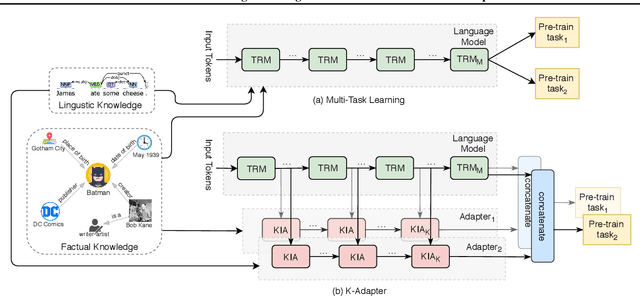
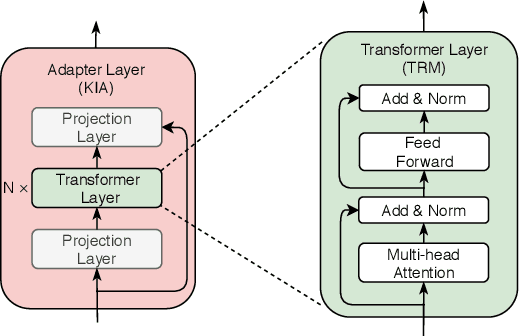
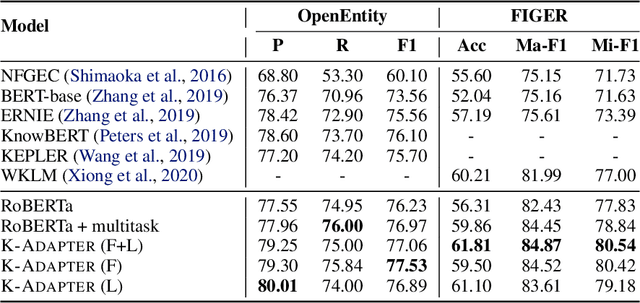
We study the problem of injecting knowledge into large pre-trained models like BERT and RoBERTa. Existing methods typically update the original parameters of pre-trained models when injecting knowledge. However, when multiple kinds of knowledge are injected, they may suffer from the problem of catastrophic forgetting. To address this, we propose K-Adapter, which remains the original parameters of the pre-trained model fixed and supports continual knowledge infusion. Taking RoBERTa as the pre-trained model, K-Adapter has a neural adapter for each kind of infused knowledge, like a plug-in connected to RoBERTa. There is no information flow between different adapters, thus different adapters are efficiently trained in a distributed way. We inject two kinds of knowledge, including factual knowledge obtained from automatically aligned text-triplets on Wikipedia and Wikidata, and linguistic knowledge obtained from dependency parsing. Results on three knowledge-driven tasks (total six datasets) including relation classification, entity typing and question answering demonstrate that each adapter improves the performance, and the combination of both adapters brings further improvements. Probing experiments further show that K-Adapter captures richer factual and commonsense knowledge than RoBERTa.
TableQnA: Answering List Intent Queries With Web Tables
Jan 10, 2020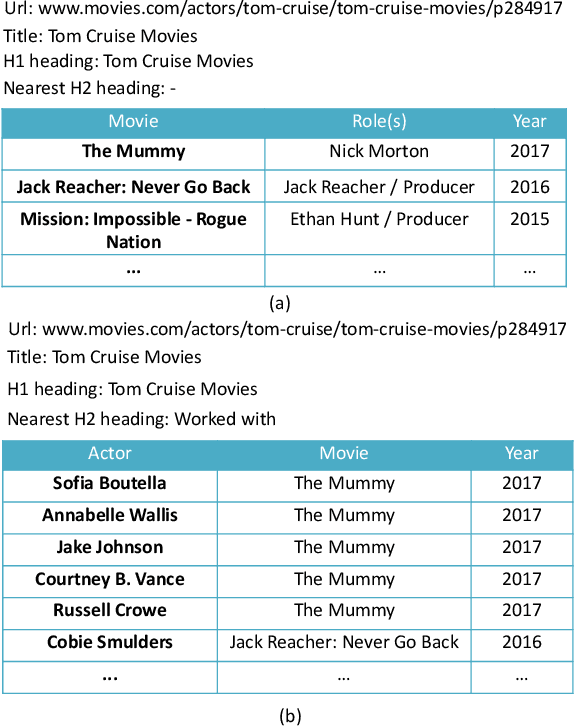
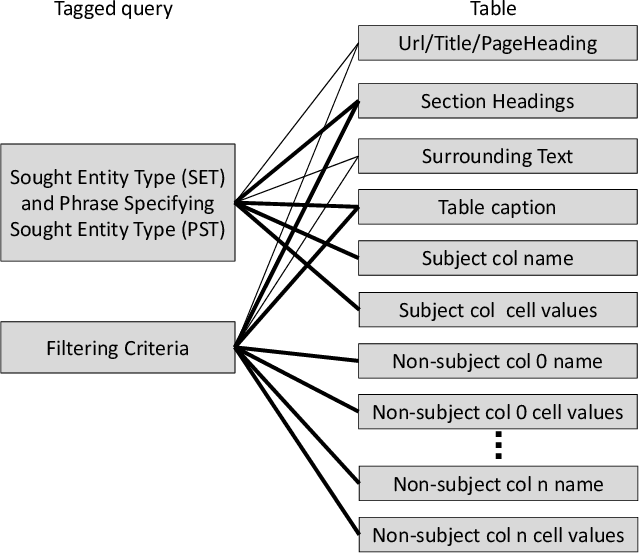

The web contains a vast corpus of HTML tables. They can be used to provide direct answers to many web queries. We focus on answering two classes of queries with those tables: those seeking lists of entities (e.g., `cities in california') and those seeking superlative entities (e.g., `largest city in california'). The main challenge is to achieve high precision with significant coverage. Existing approaches train machine learning models to select the answer from the candidates; they rely on textual match features between the query and the content of the table along with features capturing table quality/importance. These features alone are inadequate for achieving the above goals. Our main insight is that we can improve precision by (i) first extracting intent (structured information) from the query for the above query classes and (ii) then performing structure-aware matching (instead of just textual matching) between the extracted intent and the candidates to select the answer. We model (i) as a sequence tagging task. We leverage state-of-the-art deep neural network models with word embeddings. The model requires large scale training data which is expensive to obtain via manual labeling; we therefore develop a novel method to automatically generate the training data. For (ii), we develop novel features to compute structure-aware match and train a machine learning model. Our experiments on real-life web search queries show that (i) our intent extractor for list and superlative intent queries has significantly higher precision and coverage compared with baseline approaches and (ii) our table answer selector significantly outperforms the state-of-the-art baseline approach. This technology has been used in production by Microsoft's Bing search engine since 2016.
Open Domain Question Answering Using Web Tables
Jan 10, 2020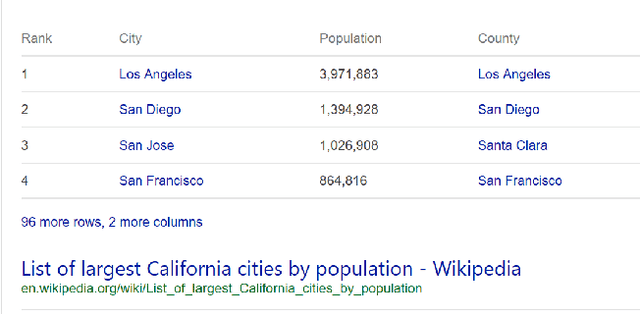

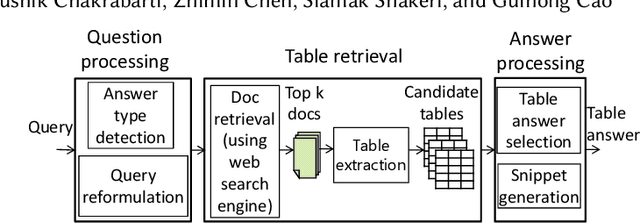
Tables extracted from web documents can be used to directly answer many web search queries. Previous works on question answering (QA) using web tables have focused on factoid queries, i.e., those answerable with a short string like person name or a number. However, many queries answerable using tables are non-factoid in nature. In this paper, we develop an open-domain QA approach using web tables that works for both factoid and non-factoid queries. Our key insight is to combine deep neural network-based semantic similarity between the query and the table with features that quantify the dominance of the table in the document as well as the quality of the information in the table. Our experiments on real-life web search queries show that our approach significantly outperforms state-of-the-art baseline approaches. Our solution is used in production in a major commercial web search engine and serves direct answers for tens of millions of real user queries per month.
Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering
Sep 09, 2019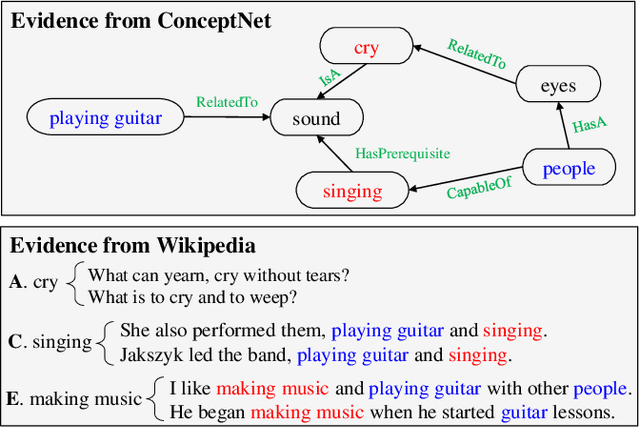
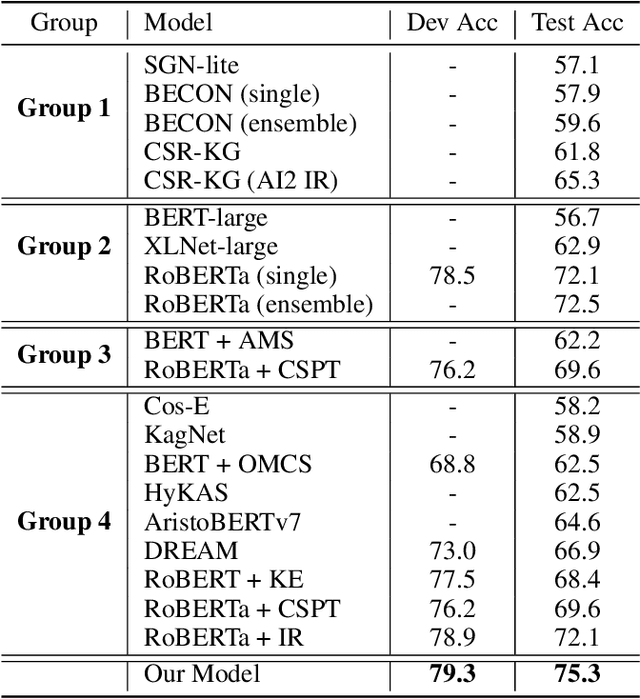
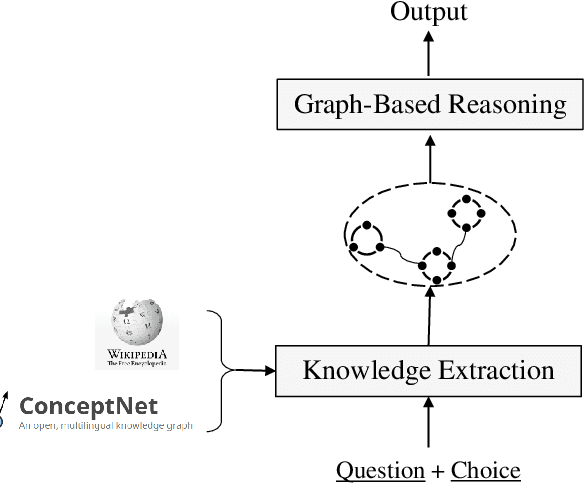

Commonsense question answering aims to answer questions which require background knowledge that is not explicitly expressed in the question. The key challenge is how to obtain evidence from external knowledge and make predictions based on the evidence. Recent works either learn to generate evidence from human-annotated evidence which is expensive to collect, or extract evidence from either structured or unstructured knowledge bases which fails to take advantages of both sources. In this work, we propose to automatically extract evidence from heterogeneous knowledge sources, and answer questions based on the extracted evidence. Specifically, we extract evidence from both structured knowledge base (i.e. ConceptNet) and Wikipedia plain texts. We construct graphs for both sources to obtain the relational structures of evidence. Based on these graphs, we propose a graph-based approach consisting of a graph-based contextual word representation learning module and a graph-based inference module. The first module utilizes graph structural information to re-define the distance between words for learning better contextual word representations. The second module adopts graph convolutional network to encode neighbor information into the representations of nodes, and aggregates evidence with graph attention mechanism for predicting the final answer. Experimental results on CommonsenseQA dataset illustrate that our graph-based approach over both knowledge sources brings improvement over strong baselines. Our approach achieves the state-of-the-art accuracy (75.3%) on the CommonsenseQA leaderboard.
Semantic Parsing with Syntax- and Table-Aware SQL Generation
Apr 23, 2018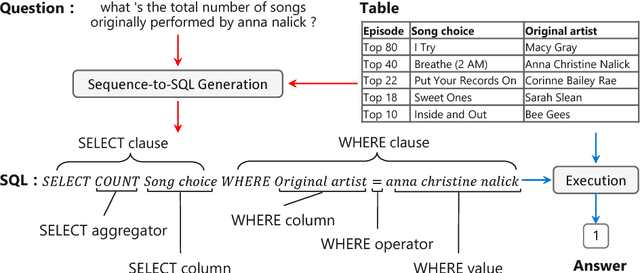
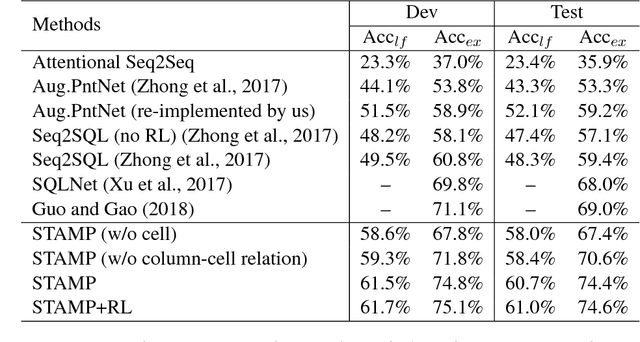
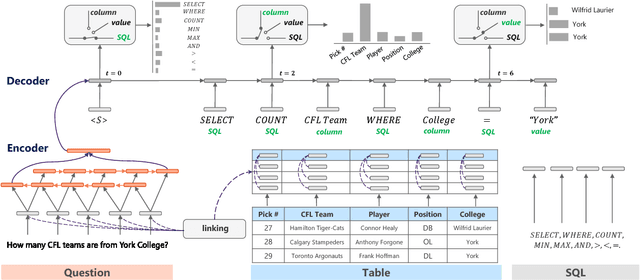
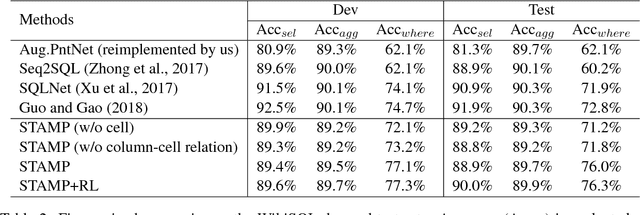
We present a generative model to map natural language questions into SQL queries. Existing neural network based approaches typically generate a SQL query word-by-word, however, a large portion of the generated results are incorrect or not executable due to the mismatch between question words and table contents. Our approach addresses this problem by considering the structure of table and the syntax of SQL language. The quality of the generated SQL query is significantly improved through (1) learning to replicate content from column names, cells or SQL keywords; and (2) improving the generation of WHERE clause by leveraging the column-cell relation. Experiments are conducted on WikiSQL, a recently released dataset with the largest question-SQL pairs. Our approach significantly improves the state-of-the-art execution accuracy from 69.0% to 74.4%.