 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Song Translation for Tonal Languages
Mar 25, 2022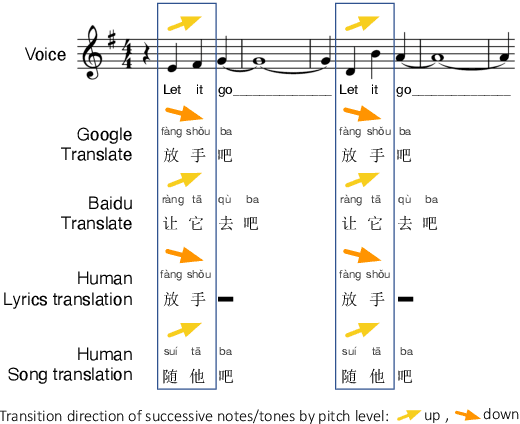
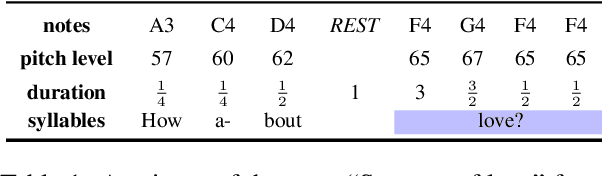
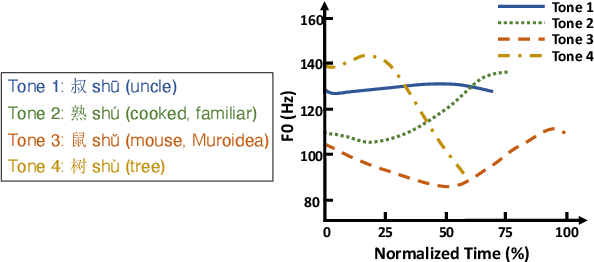
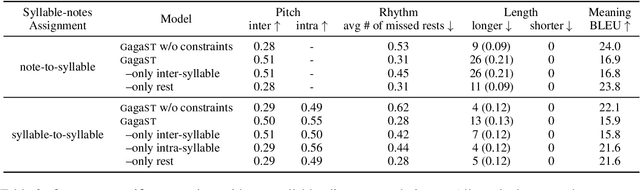
This paper develops automatic song translation (AST) for tonal languages and addresses the unique challenge of aligning words' tones with melody of a song in addition to conveying the original meaning. We propose three criteria for effective AST -- preserving meaning, singability and intelligibility -- and design metrics for these criteria. We develop a new benchmark for English--Mandarin song translation and develop an unsupervised AST system, Guided AliGnment for Automatic Song Translation (GagaST), which combines pre-training with three decoding constraints. Both automatic and human evaluations show GagaST successfully balances semantics and singability.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020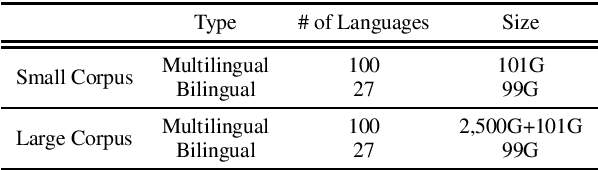
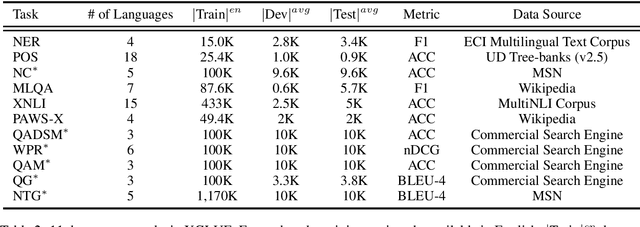
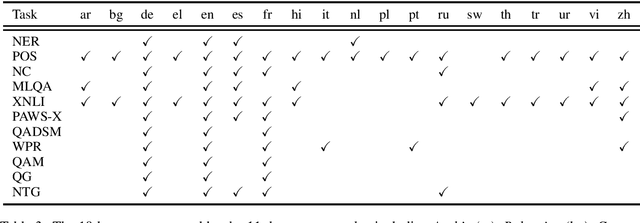
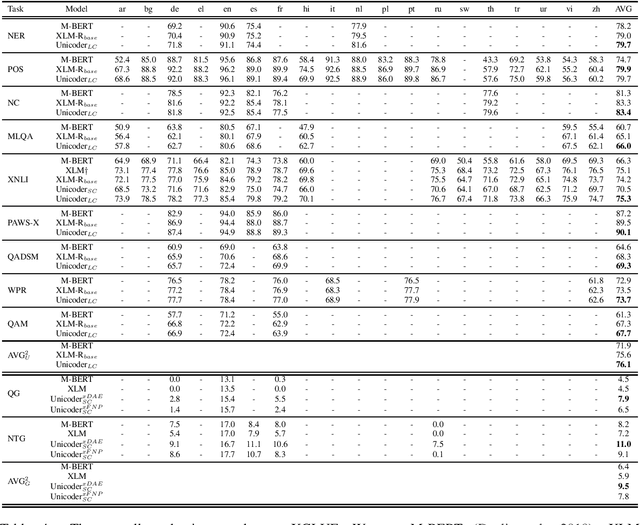
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
Inducing and Embedding Senses with Scaled Gumbel Softmax
Apr 22, 2018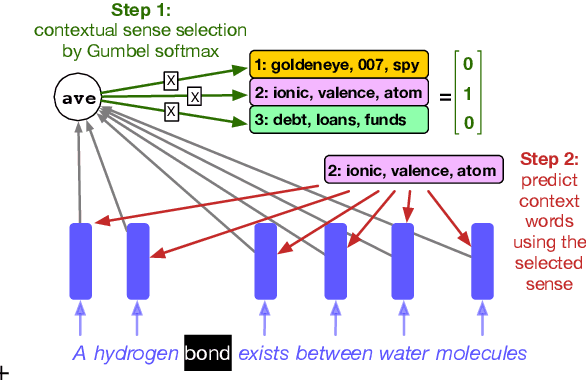
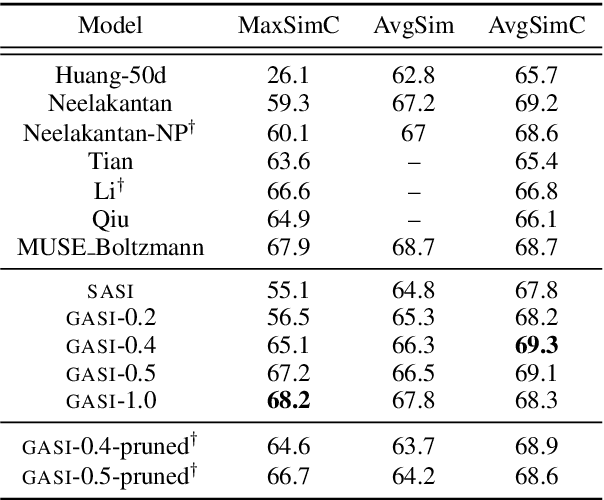
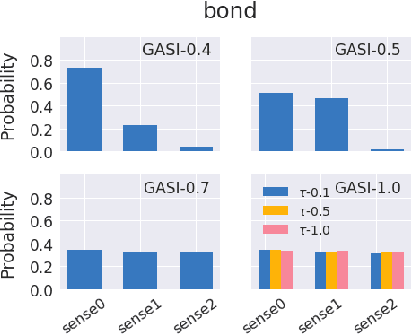

Methods for learning word sense embeddings represent a single word with multiple sense-specific vectors. These methods should not only produce interpretable sense embeddings, but should also learn how to select which sense to use in a given context. We propose an unsupervised model that learns sense embeddings using a modified Gumbel softmax function, which allows for differentiable discrete sense selection. Our model produces sense embeddings that are competitive (and sometimes state of the art) on multiple similarity based downstream evaluations. However, performance on these downstream evaluations tasks does not correlate with interpretability of sense embeddings, as we discover through an interpretability comparison with competing multi-sense embeddings. While many previous approaches perform well on downstream evaluations, they do not produce interpretable embeddings and learn duplicated sense groups; our method achieves the best of both worlds.
On Evaluating and Comparing Conversational Agents
Jan 11, 2018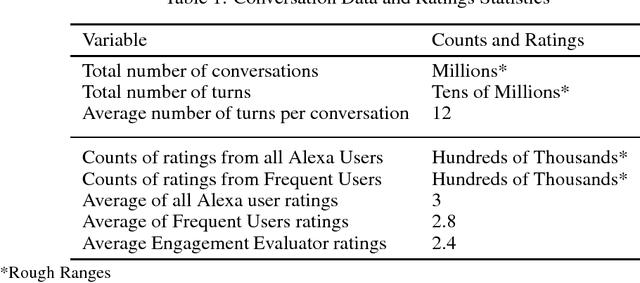

Conversational agents are exploding in popularity. However, much work remains in the area of non goal-oriented conversations, despite significant growth in research interest over recent years. To advance the state of the art in conversational AI, Amazon launched the Alexa Prize, a 2.5-million dollar university competition where sixteen selected university teams built conversational agents to deliver the best social conversational experience. Alexa Prize provided the academic community with the unique opportunity to perform research with a live system used by millions of users. The subjectivity associated with evaluating conversations is key element underlying the challenge of building non-goal oriented dialogue systems. In this paper, we propose a comprehensive evaluation strategy with multiple metrics designed to reduce subjectivity by selecting metrics which correlate well with human judgement. The proposed metrics provide granular analysis of the conversational agents, which is not captured in human ratings. We show that these metrics can be used as a reasonable proxy for human judgment. We provide a mechanism to unify the metrics for selecting the top performing agents, which has also been applied throughout the Alexa Prize competition. To our knowledge, to date it is the largest setting for evaluating agents with millions of conversations and hundreds of thousands of ratings from users. We believe that this work is a step towards an automatic evaluation process for conversational AIs.
* 10 pages, 5 tables. NIPS 2017 Conversational AI workshop. http://alborz-geramifard.com/workshops/nips17-Conversational-AI/Main.html
Topic-based Evaluation for Conversational Bots
Jan 11, 2018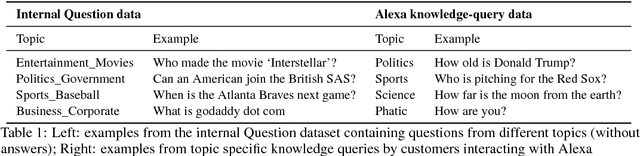
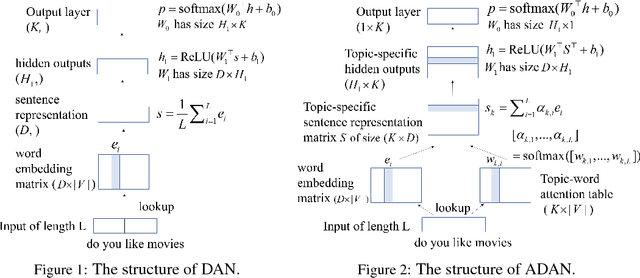

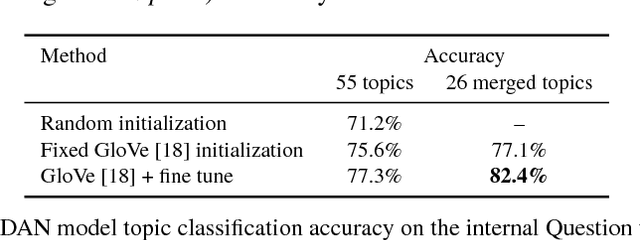
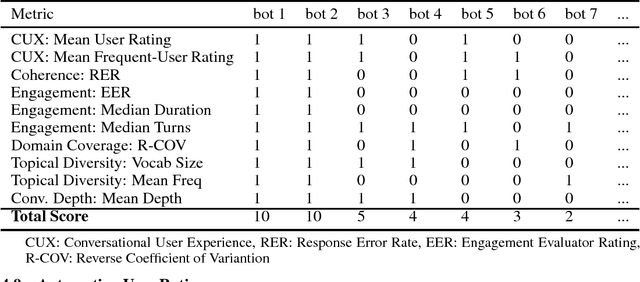
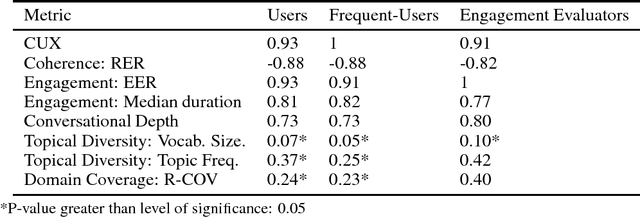
Dialog evaluation is a challenging problem, especially for non task-oriented dialogs where conversational success is not well-defined. We propose to evaluate dialog quality using topic-based metrics that describe the ability of a conversational bot to sustain coherent and engaging conversations on a topic, and the diversity of topics that a bot can handle. To detect conversation topics per utterance, we adopt Deep Average Networks (DAN) and train a topic classifier on a variety of question and query data categorized into multiple topics. We propose a novel extension to DAN by adding a topic-word attention table that allows the system to jointly capture topic keywords in an utterance and perform topic classification. We compare our proposed topic based metrics with the ratings provided by users and show that our metrics both correlate with and complement human judgment. Our analysis is performed on tens of thousands of real human-bot dialogs from the Alexa Prize competition and highlights user expectations for conversational bots.
* 10 Pages, 2 figures, 9 tables. NIPS 2017 Conversational AI workshop paper. http://alborz-geramifard.com/workshops/nips17-Conversational-AI/Main.html