 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Rationale: Multi-Modal Reasoning Mixture for Visual Question Answering
Jun 03, 2024Zero-shot visual question answering (VQA) is a challenging task that requires reasoning across modalities. While some existing methods rely on a single rationale within the Chain of Thoughts (CoT) framework, they may fall short of capturing the complexity of the VQA problem. On the other hand, some other methods that use multiple rationales may still suffer from low diversity, poor modality alignment, and inefficient retrieval and fusion. In response to these challenges, we propose \emph{Mixture of Rationales (MoR)}, a novel multi-modal reasoning method that mixes multiple rationales for VQA. MoR uses a single frozen Vision-and-Language Pre-trained Models (VLPM) model to {dynamically generate, retrieve and fuse multi-modal thoughts}. We evaluate MoR on two challenging VQA datasets, i.e. NLVR2 and OKVQA, with two representative backbones OFA and VL-T5. MoR achieves a 12.43\% accuracy improvement on NLVR2, and a 2.45\% accuracy improvement on OKVQA-S( the science and technology category of OKVQA).
Hypertext Entity Extraction in Webpage
Mar 04, 2024



Webpage entity extraction is a fundamental natural language processing task in both research and applications. Nowadays, the majority of webpage entity extraction models are trained on structured datasets which strive to retain textual content and its structure information. However, existing datasets all overlook the rich hypertext features (e.g., font color, font size) which show their effectiveness in previous works. To this end, we first collect a \textbf{H}ypertext \textbf{E}ntity \textbf{E}xtraction \textbf{D}ataset (\textit{HEED}) from the e-commerce domains, scraping both the text and the corresponding explicit hypertext features with high-quality manual entity annotations. Furthermore, we present the \textbf{Mo}E-based \textbf{E}ntity \textbf{E}xtraction \textbf{F}ramework (\textit{MoEEF}), which efficiently integrates multiple features to enhance model performance by Mixture of Experts and outperforms strong baselines, including the state-of-the-art small-scale models and GPT-3.5-turbo. Moreover, the effectiveness of hypertext features in \textit{HEED} and several model components in \textit{MoEEF} are analyzed.
Beyond Surface: Probing LLaMA Across Scales and Layers
Dec 14, 2023This paper presents an in-depth analysis of Large Language Models (LLMs), focusing on LLaMA, a prominent open-source foundational model in natural language processing. Instead of assessing LLaMA through its generative output, we design multiple-choice tasks to probe its intrinsic understanding in high-order tasks such as reasoning and computation. We examine the model horizontally, comparing different sizes, and vertically, assessing different layers. We unveil several key and uncommon findings based on the designed probing tasks: (1) Horizontally, enlarging model sizes almost could not automatically impart additional knowledge or computational prowess. Instead, it can enhance reasoning abilities, especially in math problem solving, and helps reduce hallucinations, but only beyond certain size thresholds; (2) In vertical analysis, the lower layers of LLaMA lack substantial arithmetic and factual knowledge, showcasing logical thinking, multilingual and recognitive abilities, with top layers housing most computational power and real-world knowledge.
Coherent Entity Disambiguation via Modeling Topic and Categorical Dependency
Nov 06, 2023



Previous entity disambiguation (ED) methods adopt a discriminative paradigm, where prediction is made based on matching scores between mention context and candidate entities using length-limited encoders. However, these methods often struggle to capture explicit discourse-level dependencies, resulting in incoherent predictions at the abstract level (e.g. topic or category). We propose CoherentED, an ED system equipped with novel designs aimed at enhancing the coherence of entity predictions. Our method first introduces an unsupervised variational autoencoder (VAE) to extract latent topic vectors of context sentences. This approach not only allows the encoder to handle longer documents more effectively, conserves valuable input space, but also keeps a topic-level coherence. Additionally, we incorporate an external category memory, enabling the system to retrieve relevant categories for undecided mentions. By employing step-by-step entity decisions, this design facilitates the modeling of entity-entity interactions, thereby maintaining maximum coherence at the category level. We achieve new state-of-the-art results on popular ED benchmarks, with an average improvement of 1.3 F1 points. Our model demonstrates particularly outstanding performance on challenging long-text scenarios.
Instructed Language Models with Retrievers Are Powerful Entity Linkers
Nov 06, 2023Generative approaches powered by large language models (LLMs) have demonstrated emergent abilities in tasks that require complex reasoning abilities. Yet the generative nature still makes the generated content suffer from hallucinations, thus unsuitable for entity-centric tasks like entity linking (EL) requiring precise entity predictions over a large knowledge base. We present Instructed Generative Entity Linker (INSGENEL), the first approach that enables casual language models to perform entity linking over knowledge bases. Several methods to equip language models with EL capability were proposed in this work, including (i) a sequence-to-sequence training EL objective with instruction-tuning, (ii) a novel generative EL framework based on a light-weight potential mention retriever that frees the model from heavy and non-parallelizable decoding, achieving 4$\times$ speedup without compromise on linking metrics. INSGENEL outperforms previous generative alternatives with +6.8 F1 points gain on average, also with a huge advantage in training data efficiency and training compute consumption. In addition, our skillfully engineered in-context learning (ICL) framework for EL still lags behind INSGENEL significantly, reaffirming that the EL task remains a persistent hurdle for general LLMs.
RUEL: Retrieval-Augmented User Representation with Edge Browser Logs for Sequential Recommendation
Sep 19, 2023



Online recommender systems (RS) aim to match user needs with the vast amount of resources available on various platforms. A key challenge is to model user preferences accurately under the condition of data sparsity. To address this challenge, some methods have leveraged external user behavior data from multiple platforms to enrich user representation. However, all of these methods require a consistent user ID across platforms and ignore the information from similar users. In this study, we propose RUEL, a novel retrieval-based sequential recommender that can effectively incorporate external anonymous user behavior data from Edge browser logs to enhance recommendation. We first collect and preprocess a large volume of Edge browser logs over a one-year period and link them to target entities that correspond to candidate items in recommendation datasets. We then design a contrastive learning framework with a momentum encoder and a memory bank to retrieve the most relevant and diverse browsing sequences from the full browsing log based on the semantic similarity between user representations. After retrieval, we apply an item-level attentive selector to filter out noisy items and generate refined sequence embeddings for the final predictor. RUEL is the first method that connects user browsing data with typical recommendation datasets and can be generalized to various recommendation scenarios and datasets. We conduct extensive experiments on four real datasets for sequential recommendation tasks and demonstrate that RUEL significantly outperforms state-of-the-art baselines. We also conduct ablation studies and qualitative analysis to validate the effectiveness of each component of RUEL and provide additional insights into our method.
Alleviating Over-smoothing for Unsupervised Sentence Representation
May 09, 2023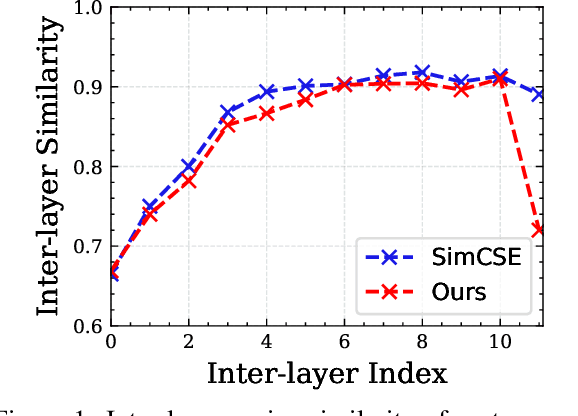

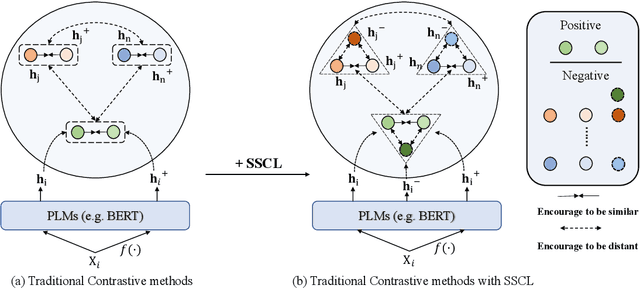
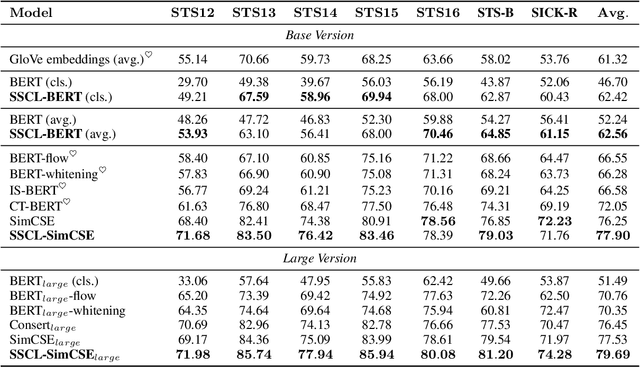
Currently, learning better unsupervised sentence representations is the pursuit of many natural language processing communities. Lots of approaches based on pre-trained language models (PLMs) and contrastive learning have achieved promising results on this task. Experimentally, we observe that the over-smoothing problem reduces the capacity of these powerful PLMs, leading to sub-optimal sentence representations. In this paper, we present a Simple method named Self-Contrastive Learning (SSCL) to alleviate this issue, which samples negatives from PLMs intermediate layers, improving the quality of the sentence representation. Our proposed method is quite simple and can be easily extended to various state-of-the-art models for performance boosting, which can be seen as a plug-and-play contrastive framework for learning unsupervised sentence representation. Extensive results prove that SSCL brings the superior performance improvements of different strong baselines (e.g., BERT and SimCSE) on Semantic Textual Similarity and Transfer datasets. Our codes are available at https://github.com/nuochenpku/SSCL.
* 13 pages
Augmenting Passage Representations with Query Generation for Enhanced Cross-Lingual Dense Retrieval
May 06, 2023Effective cross-lingual dense retrieval methods that rely on multilingual pre-trained language models (PLMs) need to be trained to encompass both the relevance matching task and the cross-language alignment task. However, cross-lingual data for training is often scarcely available. In this paper, rather than using more cross-lingual data for training, we propose to use cross-lingual query generation to augment passage representations with queries in languages other than the original passage language. These augmented representations are used at inference time so that the representation can encode more information across the different target languages. Training of a cross-lingual query generator does not require additional training data to that used for the dense retriever. The query generator training is also effective because the pre-training task for the generator (T5 text-to-text training) is very similar to the fine-tuning task (generation of a query). The use of the generator does not increase query latency at inference and can be combined with any cross-lingual dense retrieval method. Results from experiments on a benchmark cross-lingual information retrieval dataset show that our approach can improve the effectiveness of existing cross-lingual dense retrieval methods. Implementation of our methods, along with all generated query files are made publicly available at https://github.com/ielab/xQG4xDR.
Typos-aware Bottlenecked Pre-Training for Robust Dense Retrieval
Apr 17, 2023Current dense retrievers (DRs) are limited in their ability to effectively process misspelled queries, which constitute a significant portion of query traffic in commercial search engines. The main issue is that the pre-trained language model-based encoders used by DRs are typically trained and fine-tuned using clean, well-curated text data. Misspelled queries are typically not found in the data used for training these models, and thus misspelled queries observed at inference time are out-of-distribution compared to the data used for training and fine-tuning. Previous efforts to address this issue have focused on \textit{fine-tuning} strategies, but their effectiveness on misspelled queries remains lower than that of pipelines that employ separate state-of-the-art spell-checking components. To address this challenge, we propose ToRoDer (TypOs-aware bottlenecked pre-training for RObust DEnse Retrieval), a novel \textit{pre-training} strategy for DRs that increases their robustness to misspelled queries while preserving their effectiveness in downstream retrieval tasks. ToRoDer utilizes an encoder-decoder architecture where the encoder takes misspelled text with masked tokens as input and outputs bottlenecked information to the decoder. The decoder then takes as input the bottlenecked embeddings, along with token embeddings of the original text with the misspelled tokens masked out. The pre-training task is to recover the masked tokens for both the encoder and decoder. Our extensive experimental results and detailed ablation studies show that DRs pre-trained with ToRoDer exhibit significantly higher effectiveness on misspelled queries, sensibly closing the gap with pipelines that use a separate, complex spell-checker component, while retaining their effectiveness on correctly spelled queries.
TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
Mar 29, 2023



Artificial Intelligence (AI) has made incredible progress recently. On the one hand, advanced foundation models like ChatGPT can offer powerful conversation, in-context learning and code generation abilities on a broad range of open-domain tasks. They can also generate high-level solution outlines for domain-specific tasks based on the common sense knowledge they have acquired. However, they still face difficulties with some specialized tasks because they lack enough domain-specific data during pre-training or they often have errors in their neural network computations on those tasks that need accurate executions. On the other hand, there are also many existing models and systems (symbolic-based or neural-based) that can do some domain-specific tasks very well. However, due to the different implementation or working mechanisms, they are not easily accessible or compatible with foundation models. Therefore, there is a clear and pressing need for a mechanism that can leverage foundation models to propose task solution outlines and then automatically match some of the sub-tasks in the outlines to the off-the-shelf models and systems with special functionalities to complete them. Inspired by this, we introduce TaskMatrix.AI as a new AI ecosystem that connects foundation models with millions of APIs for task completion. Unlike most previous work that aimed to improve a single AI model, TaskMatrix.AI focuses more on using existing foundation models (as a brain-like central system) and APIs of other AI models and systems (as sub-task solvers) to achieve diversified tasks in both digital and physical domains. As a position paper, we will present our vision of how to build such an ecosystem, explain each key component, and use study cases to illustrate both the feasibility of this vision and the main challenges we need to address next.