 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving VQA Reliability: A Dual-Assessment Approach with Self-Reflection and Cross-Model Verification
Dec 16, 2025Vision-language models (VLMs) have demonstrated significant potential in Visual Question Answering (VQA). However, the susceptibility of VLMs to hallucinations can lead to overconfident yet incorrect answers, severely undermining answer reliability. To address this, we propose Dual-Assessment for VLM Reliability (DAVR), a novel framework that integrates Self-Reflection and Cross-Model Verification for comprehensive uncertainty estimation. The DAVR framework features a dual-pathway architecture: one pathway leverages dual selector modules to assess response reliability by fusing VLM latent features with QA embeddings, while the other deploys external reference models for factual cross-checking to mitigate hallucinations. Evaluated in the Reliable VQA Challenge at ICCV-CLVL 2025, DAVR achieves a leading $Φ_{100}$ score of 39.64 and a 100-AUC of 97.22, securing first place and demonstrating its effectiveness in enhancing the trustworthiness of VLM responses.
OMUDA: Omni-level Masking for Unsupervised Domain Adaptation in Semantic Segmentation
Dec 13, 2025Unsupervised domain adaptation (UDA) enables semantic segmentation models to generalize from a labeled source domain to an unlabeled target domain. However, existing UDA methods still struggle to bridge the domain gap due to cross-domain contextual ambiguity, inconsistent feature representations, and class-wise pseudo-label noise. To address these challenges, we propose Omni-level Masking for Unsupervised Domain Adaptation (OMUDA), a unified framework that introduces hierarchical masking strategies across distinct representation levels. Specifically, OMUDA comprises: 1) a Context-Aware Masking (CAM) strategy that adaptively distinguishes foreground from background to balance global context and local details; 2) a Feature Distillation Masking (FDM) strategy that enhances robust and consistent feature learning through knowledge transfer from pre-trained models; and 3) a Class Decoupling Masking (CDM) strategy that mitigates the impact of noisy pseudo-labels by explicitly modeling class-wise uncertainty. This hierarchical masking paradigm effectively reduces the domain shift at the contextual, representational, and categorical levels, providing a unified solution beyond existing approaches. Extensive experiments on multiple challenging cross-domain semantic segmentation benchmarks validate the effectiveness of OMUDA. Notably, on the SYNTHIA->Cityscapes and GTA5->Cityscapes tasks, OMUDA can be seamlessly integrated into existing UDA methods and consistently achieving state-of-the-art results with an average improvement of 7%.
The Potential and Value of AI Chatbot in Personalized Cognitive Training
Oct 25, 2024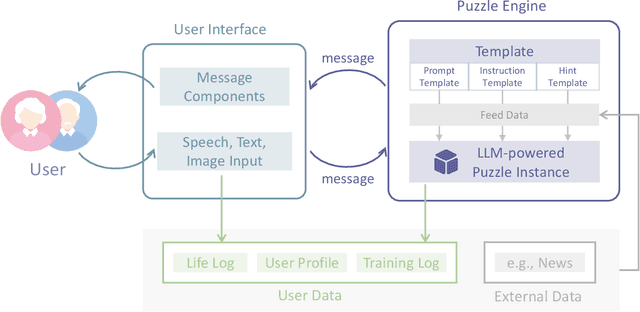


In recent years, the rapid aging of the global population has led to an increase in cognitive disorders, such as Alzheimer's disease, presenting significant public health challenges. Although no effective treatments currently exist to reverse Alzheimer's, prevention and early intervention, including cognitive training, are critical. This report explores the potential of AI chatbots in enhancing personalized cognitive training. We introduce ReMe, a web-based framework designed to create AI chatbots that facilitate cognitive training research, specifically targeting episodic memory tasks derived from personal life logs. By leveraging large language models, ReMe provides enhanced user-friendly, interactive, and personalized training experiences. Case studies demonstrate ReMe's effectiveness in engaging users through life recall and open-ended language puzzles, highlighting its potential to improve cognitive training design. Despite promising results, further research is needed to validate training effectiveness through large-scale studies that include cognitive ability evaluations. Overall, ReMe offers a promising approach to personalized cognitive training, utilizing AI capabilities to meet the growing demand for non-pharmacological interventions in cognitive health, with future research aiming to expand its applications and efficacy.
TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
Mar 29, 2023



Artificial Intelligence (AI) has made incredible progress recently. On the one hand, advanced foundation models like ChatGPT can offer powerful conversation, in-context learning and code generation abilities on a broad range of open-domain tasks. They can also generate high-level solution outlines for domain-specific tasks based on the common sense knowledge they have acquired. However, they still face difficulties with some specialized tasks because they lack enough domain-specific data during pre-training or they often have errors in their neural network computations on those tasks that need accurate executions. On the other hand, there are also many existing models and systems (symbolic-based or neural-based) that can do some domain-specific tasks very well. However, due to the different implementation or working mechanisms, they are not easily accessible or compatible with foundation models. Therefore, there is a clear and pressing need for a mechanism that can leverage foundation models to propose task solution outlines and then automatically match some of the sub-tasks in the outlines to the off-the-shelf models and systems with special functionalities to complete them. Inspired by this, we introduce TaskMatrix.AI as a new AI ecosystem that connects foundation models with millions of APIs for task completion. Unlike most previous work that aimed to improve a single AI model, TaskMatrix.AI focuses more on using existing foundation models (as a brain-like central system) and APIs of other AI models and systems (as sub-task solvers) to achieve diversified tasks in both digital and physical domains. As a position paper, we will present our vision of how to build such an ecosystem, explain each key component, and use study cases to illustrate both the feasibility of this vision and the main challenges we need to address next.