 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Segment Anything Model with Visual Mamba for Diagnosing Placenta Accreta Spectrum
May 30, 2026Placenta Accreta Spectrum (PAS) is a rare but highly dangerous obstetric disease. Early and accurate PAS diagnosis is critical for maternal health. Traditional PAS diagnosis relies on experienced doctors by analyzing the cesarean history and Magnetic Resonance Imaging (MRI) data. However, district-level hospitals often lack the expertise and resources for accurate PAS diagnosis. To address these challenges, we establish the first MRI-based PAS dataset, which includes both fine-grained segmentation and classification annotations. Meanwhile, diagnosing PAS can be significantly enhanced by segmenting lesion areas from MRI images of the uterus. To achieve automatic PAS diagnosis, we propose 3DSAMba, a novel feature learning framework for effective lesion segmentation. More specifically, we first design a 3D Segment Anything Model (SAM) and incorporate medical domain information into the model through an efficient adapter mechanism. In addition, we introduce a Multi-Level Aggregation Mamba (MLAM) to aggregate feature maps across different levels and a Fusion State Space Model (FSSM) to fuse multi-scale features from both the encoder and decoder. Finally, we apply segmentation masks to the original MRI images through element-wise multiplication, effectively isolating lesion areas for more accurate PAS diagnosis. Extensive experiments validate that our framework significantly improves the PAS diagnostic performance. To facilitate further research in PAS diagnosis, we have released the dataset and source code at https://github.com/Drchip61/PASD.
SlideSparse: Fast and Flexible (2N-2):2N Structured Sparsity
Mar 05, 2026NVIDIA's 2:4 Sparse Tensor Cores deliver 2x throughput but demand strict 50% pruning -- a ratio that collapses LLM reasoning accuracy (Qwen3: 54% to 15%). Milder $(2N-2):2N$ patterns (e.g., 6:8, 25% pruning) preserve accuracy yet receive no hardware support, falling back to dense execution without any benefit from sparsity. We present SlideSparse, the first system to unlock Sparse Tensor Core acceleration for the $(2N-2):2N$ model family on commodity GPUs. Our Sliding Window Decomposition reconstructs any $(2N-2):2N$ weight block into $N-1$ overlapping 2:4-compliant windows without any accuracy loss; Activation Lifting fuses the corresponding activation rearrangement into per-token quantization at near-zero cost. Integrated into vLLM, SlideSparse is evaluated across various GPUs (A100, H100, B200, RTX 4090, RTX 5080, DGX-spark), precisions (FP4, INT8, FP8, BF16, FP16), and model families (Llama, Qwen, BitNet). On compute-bound workloads, the measured speedup ratio (1.33x) approaches the theoretical upper-bound $N/(N-1)=4/3$ at 6:8 weight sparsity in Qwen2.5-7B, establishing $(2N-2):2N$ as a practical path to accuracy-preserving LLM acceleration. Code available at https://github.com/bcacdwk/vllmbench.
Sparse-BitNet: 1.58-bit LLMs are Naturally Friendly to Semi-Structured Sparsity
Mar 05, 2026Semi-structured N:M sparsity and low-bit quantization (e.g., 1.58-bit BitNet) are two promising approaches for improving the efficiency of large language models (LLMs), yet they have largely been studied in isolation. In this work, we investigate their interaction and show that 1.58-bit BitNet is naturally more compatible with N:M sparsity than full-precision models. To study this effect, we propose Sparse-BitNet, a unified framework that jointly applies 1.58-bit quantization and dynamic N:M sparsification while ensuring stable training for the first time. Across multiple model scales and training regimes (sparse pretraining and dense-to-sparse schedules), 1.58-bit BitNet consistently exhibits smaller performance degradation than full-precision baselines at the same sparsity levels and can tolerate higher structured sparsity before accuracy collapse. Moreover, using our custom sparse tensor core, Sparse-BitNet achieves substantial speedups in both training and inference, reaching up to 1.30X. These results highlight that combining extremely low-bit quantization with semi-structured N:M sparsity is a promising direction for efficient LLMs. Code available at https://github.com/AAzdi/Sparse-BitNet
VIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
Anatomy-Guided Multitask Learning for MRI-Based Classification of Placenta Accreta Spectrum and its Subtypes
May 23, 2025Placenta Accreta Spectrum Disorders (PAS) pose significant risks during pregnancy, frequently leading to postpartum hemorrhage during cesarean deliveries and other severe clinical complications, with bleeding severity correlating to the degree of placental invasion. Consequently, accurate prenatal diagnosis of PAS and its subtypes-placenta accreta (PA), placenta increta (PI), and placenta percreta (PP)-is crucial. However, existing guidelines and methodologies predominantly focus on the presence of PAS, with limited research addressing subtype recognition. Additionally, previous multi-class diagnostic efforts have primarily relied on inefficient two-stage cascaded binary classification tasks. In this study, we propose a novel convolutional neural network (CNN) architecture designed for efficient one-stage multiclass diagnosis of PAS and its subtypes, based on 4,140 magnetic resonance imaging (MRI) slices. Our model features two branches: the main classification branch utilizes a residual block architecture comprising multiple residual blocks, while the second branch integrates anatomical features of the uteroplacental area and the adjacent uterine serous layer to enhance the model's attention during classification. Furthermore, we implement a multitask learning strategy to leverage both branches effectively. Experiments conducted on a real clinical dataset demonstrate that our model achieves state-of-the-art performance.
BitNet b1.58 2B4T Technical Report
Apr 16, 2025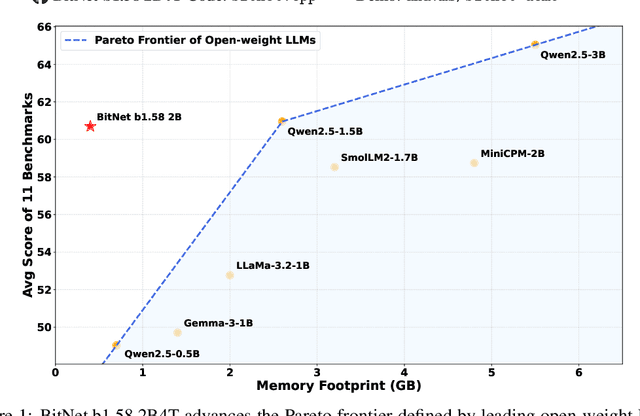
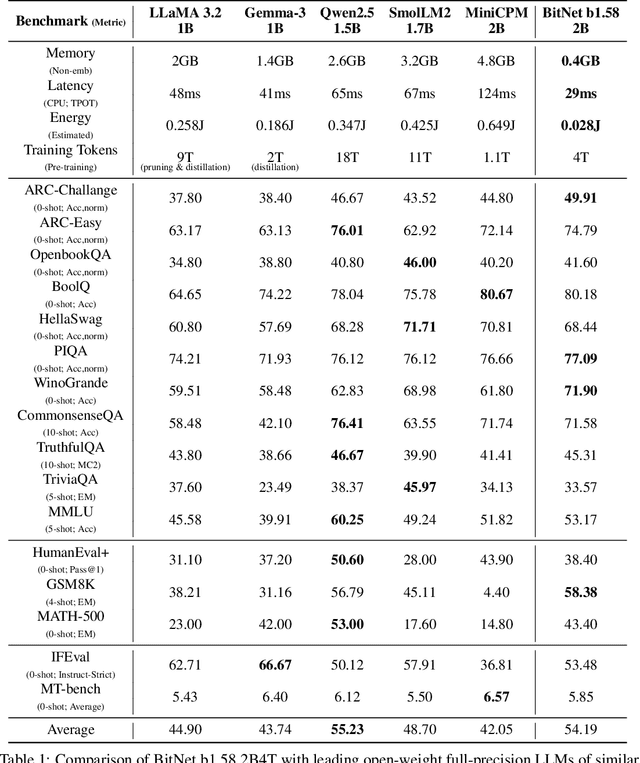
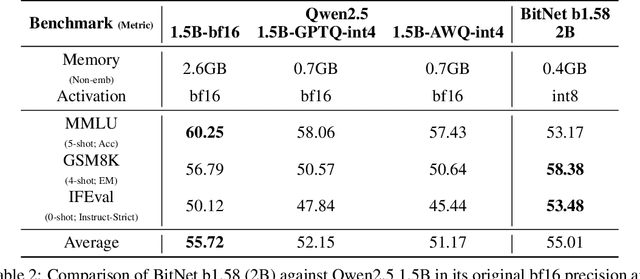
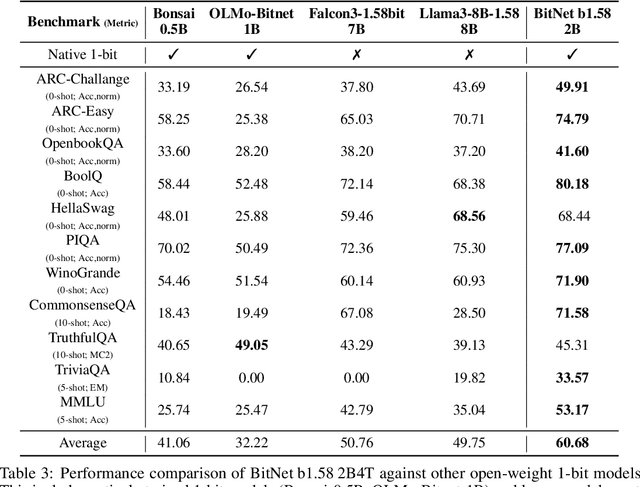
We introduce BitNet b1.58 2B4T, the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale. Trained on a corpus of 4 trillion tokens, the model has been rigorously evaluated across benchmarks covering language understanding, mathematical reasoning, coding proficiency, and conversational ability. Our results demonstrate that BitNet b1.58 2B4T achieves performance on par with leading open-weight, full-precision LLMs of similar size, while offering significant advantages in computational efficiency, including substantially reduced memory footprint, energy consumption, and decoding latency. To facilitate further research and adoption, the model weights are released via Hugging Face along with open-source inference implementations for both GPU and CPU architectures.
Bitnet.cpp: Efficient Edge Inference for Ternary LLMs
Feb 17, 2025The advent of 1-bit large language models (LLMs), led by BitNet b1.58, has spurred interest in ternary LLMs. Despite this, research and practical applications focusing on efficient edge inference for ternary LLMs remain scarce. To bridge this gap, we introduce Bitnet.cpp, an inference system optimized for BitNet b1.58 and ternary LLMs. Given that mixed-precision matrix multiplication (mpGEMM) constitutes the bulk of inference time in ternary LLMs, Bitnet.cpp incorporates a novel mpGEMM library to facilitate sub-2-bits-per-weight, efficient and lossless inference. The library features two core solutions: Ternary Lookup Table (TL), which addresses spatial inefficiencies of previous bit-wise methods, and Int2 with a Scale (I2_S), which ensures lossless edge inference, both enabling high-speed inference. Our experiments show that Bitnet.cpp achieves up to a 6.25x increase in speed over full-precision baselines and up to 2.32x over low-bit baselines, setting new benchmarks in the field. Additionally, we expand TL to element-wise lookup table (ELUT) for low-bit LLMs in the appendix, presenting both theoretical and empirical evidence of its considerable potential. Bitnet.cpp is publicly available at https://github.com/microsoft/BitNet/tree/paper , offering a sophisticated solution for the efficient and practical deployment of edge LLMs.
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
Oct 21, 2024Recent advances in 1-bit Large Language Models (LLMs), such as BitNet and BitNet b1.58, present a promising approach to enhancing the efficiency of LLMs in terms of speed and energy consumption. These developments also enable local LLM deployment across a broad range of devices. In this work, we introduce bitnet.cpp, a tailored software stack designed to unlock the full potential of 1-bit LLMs. Specifically, we develop a set of kernels to support fast and lossless inference of ternary BitNet b1.58 LLMs on CPUs. Extensive experiments demonstrate that bitnet.cpp achieves significant speedups, ranging from 2.37x to 6.17x on x86 CPUs and from 1.37x to 5.07x on ARM CPUs, across various model sizes. The code is available at https://github.com/microsoft/BitNet.
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
Apr 01, 2024



This paper presents a comprehensive survey of the current status and opportunities for Large Language Models (LLMs) in strategic reasoning, a sophisticated form of reasoning that necessitates understanding and predicting adversary actions in multi-agent settings while adjusting strategies accordingly. Strategic reasoning is distinguished by its focus on the dynamic and uncertain nature of interactions among multi-agents, where comprehending the environment and anticipating the behavior of others is crucial. We explore the scopes, applications, methodologies, and evaluation metrics related to strategic reasoning with LLMs, highlighting the burgeoning development in this area and the interdisciplinary approaches enhancing their decision-making performance. It aims to systematize and clarify the scattered literature on this subject, providing a systematic review that underscores the importance of strategic reasoning as a critical cognitive capability and offers insights into future research directions and potential improvements.
Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting
May 11, 2023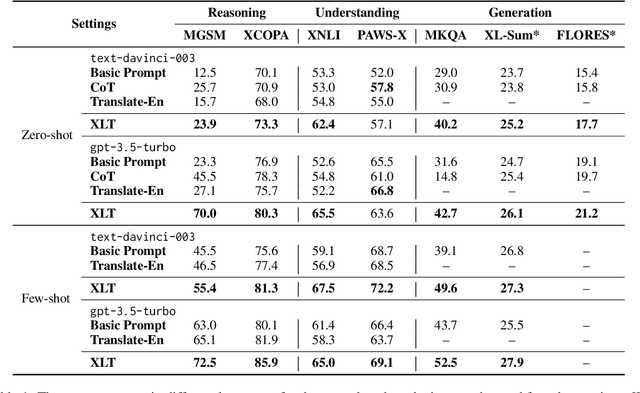

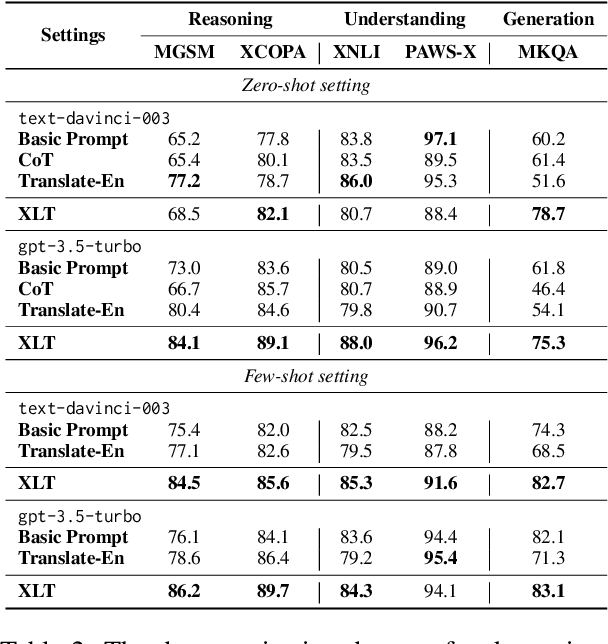

Large language models (LLMs) demonstrate impressive multilingual capability, but their performance varies substantially across different languages. In this work, we introduce a simple yet effective method, called cross-lingual-thought prompting (XLT), to systematically improve the multilingual capability of LLMs. Specifically, XLT is a generic template prompt that stimulates cross-lingual and logical reasoning skills to enhance task performance across languages. We conduct comprehensive evaluations on 7 typical benchmarks related to reasoning, understanding, and generation tasks, covering both high-resource and low-resource languages. Experimental results show that XLT not only remarkably enhances the performance of various multilingual tasks but also significantly reduces the gap between the average performance and the best performance of each task in different languages. Notably, XLT brings over 10 points of average improvement in arithmetic reasoning and open-domain question-answering tasks.