 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior-Adaptive Q-Learning: A Unifying Framework for Offline-to-Online RL
Nov 05, 2025Offline reinforcement learning (RL) enables training from fixed data without online interaction, but policies learned offline often struggle when deployed in dynamic environments due to distributional shift and unreliable value estimates on unseen state-action pairs. We introduce Behavior-Adaptive Q-Learning (BAQ), a framework designed to enable a smooth and reliable transition from offline to online RL. The key idea is to leverage an implicit behavioral model derived from offline data to provide a behavior-consistency signal during online fine-tuning. BAQ incorporates a dual-objective loss that (i) aligns the online policy toward the offline behavior when uncertainty is high, and (ii) gradually relaxes this constraint as more confident online experience is accumulated. This adaptive mechanism reduces error propagation from out-of-distribution estimates, stabilizes early online updates, and accelerates adaptation to new scenarios. Across standard benchmarks, BAQ consistently outperforms prior offline-to-online RL approaches, achieving faster recovery, improved robustness, and higher overall performance. Our results demonstrate that implicit behavior adaptation is a principled and practical solution for reliable real-world policy deployment.
From Static to Dynamic: Enhancing Offline-to-Online Reinforcement Learning via Energy-Guided Diffusion Stratification
Nov 05, 2025Transitioning from offline to online reinforcement learning (RL) poses critical challenges due to distributional shifts between the fixed behavior policy in the offline dataset and the evolving policy during online learning. Although this issue is widely recognized, few methods attempt to explicitly assess or utilize the distributional structure of the offline data itself, leaving a research gap in adapting learning strategies to different types of samples. To address this challenge, we propose an innovative method, Energy-Guided Diffusion Stratification (StratDiff), which facilitates smoother transitions in offline-to-online RL. StratDiff deploys a diffusion model to learn prior knowledge from the offline dataset. It then refines this knowledge through energy-based functions to improve policy imitation and generate offline-like actions during online fine-tuning. The KL divergence between the generated action and the corresponding sampled action is computed for each sample and used to stratify the training batch into offline-like and online-like subsets. Offline-like samples are updated using offline objectives, while online-like samples follow online learning strategies. We demonstrate the effectiveness of StratDiff by integrating it with off-the-shelf methods Cal-QL and IQL. Extensive empirical evaluations on D4RL benchmarks show that StratDiff significantly outperforms existing methods, achieving enhanced adaptability and more stable performance across diverse RL settings.
Enhancing Q-Value Updates in Deep Q-Learning via Successor-State Prediction
Nov 05, 2025



Deep Q-Networks (DQNs) estimate future returns by learning from transitions sampled from a replay buffer. However, the target updates in DQN often rely on next states generated by actions from past, potentially suboptimal, policy. As a result, these states may not provide informative learning signals, causing high variance into the update process. This issue is exacerbated when the sampled transitions are poorly aligned with the agent's current policy. To address this limitation, we propose the Successor-state Aggregation Deep Q-Network (SADQ), which explicitly models environment dynamics using a stochastic transition model. SADQ integrates successor-state distributions into the Q-value estimation process, enabling more stable and policy-aligned value updates. Additionally, it explores a more efficient action selection strategy with the modeled transition structure. We provide theoretical guarantees that SADQ maintains unbiased value estimates while reducing training variance. Our extensive empirical results across standard RL benchmarks and real-world vector-based control tasks demonstrate that SADQ consistently outperforms DQN variants in both stability and learning efficiency.
Bitnet.cpp: Efficient Edge Inference for Ternary LLMs
Feb 17, 2025The advent of 1-bit large language models (LLMs), led by BitNet b1.58, has spurred interest in ternary LLMs. Despite this, research and practical applications focusing on efficient edge inference for ternary LLMs remain scarce. To bridge this gap, we introduce Bitnet.cpp, an inference system optimized for BitNet b1.58 and ternary LLMs. Given that mixed-precision matrix multiplication (mpGEMM) constitutes the bulk of inference time in ternary LLMs, Bitnet.cpp incorporates a novel mpGEMM library to facilitate sub-2-bits-per-weight, efficient and lossless inference. The library features two core solutions: Ternary Lookup Table (TL), which addresses spatial inefficiencies of previous bit-wise methods, and Int2 with a Scale (I2_S), which ensures lossless edge inference, both enabling high-speed inference. Our experiments show that Bitnet.cpp achieves up to a 6.25x increase in speed over full-precision baselines and up to 2.32x over low-bit baselines, setting new benchmarks in the field. Additionally, we expand TL to element-wise lookup table (ELUT) for low-bit LLMs in the appendix, presenting both theoretical and empirical evidence of its considerable potential. Bitnet.cpp is publicly available at https://github.com/microsoft/BitNet/tree/paper , offering a sophisticated solution for the efficient and practical deployment of edge LLMs.
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
Oct 21, 2024Recent advances in 1-bit Large Language Models (LLMs), such as BitNet and BitNet b1.58, present a promising approach to enhancing the efficiency of LLMs in terms of speed and energy consumption. These developments also enable local LLM deployment across a broad range of devices. In this work, we introduce bitnet.cpp, a tailored software stack designed to unlock the full potential of 1-bit LLMs. Specifically, we develop a set of kernels to support fast and lossless inference of ternary BitNet b1.58 LLMs on CPUs. Extensive experiments demonstrate that bitnet.cpp achieves significant speedups, ranging from 2.37x to 6.17x on x86 CPUs and from 1.37x to 5.07x on ARM CPUs, across various model sizes. The code is available at https://github.com/microsoft/BitNet.
FedAR: Addressing Client Unavailability in Federated Learning with Local Update Approximation and Rectification
Jul 26, 2024

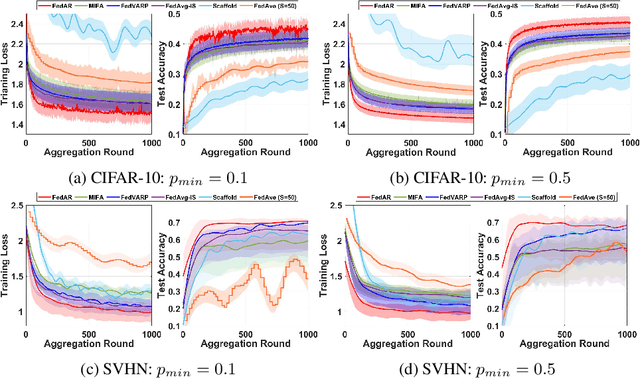

Federated learning (FL) enables clients to collaboratively train machine learning models under the coordination of a server in a privacy-preserving manner. One of the main challenges in FL is that the server may not receive local updates from each client in each round due to client resource limitations and intermittent network connectivity. The existence of unavailable clients severely deteriorates the overall FL performance. In this paper, we propose , a novel client update Approximation and Rectification algorithm for FL to address the client unavailability issue. FedAR can get all clients involved in the global model update to achieve a high-quality global model on the server, which also furnishes accurate predictions for each client. To this end, the server uses the latest update from each client as a surrogate for its current update. It then assigns a different weight to each client's surrogate update to derive the global model, in order to guarantee contributions from both available and unavailable clients. Our theoretical analysis proves that FedAR achieves optimal convergence rates on non-IID datasets for both convex and non-convex smooth loss functions. Extensive empirical studies show that FedAR comprehensively outperforms state-of-the-art FL baselines including FedAvg, MIFA, FedVARP and Scaffold in terms of the training loss, test accuracy, and bias mitigation. Moreover, FedAR also depicts impressive performance in the presence of a large number of clients with severe client unavailability.