 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-the-Wild Camouflage Attack on Vehicle Detectors through Controllable Image Editing
Mar 19, 2026Deep neural networks (DNNs) have achieved remarkable success in computer vision but remain highly vulnerable to adversarial attacks. Among them, camouflage attacks manipulate an object's visible appearance to deceive detectors while remaining stealthy to humans. In this paper, we propose a new framework that formulates vehicle camouflage attacks as a conditional image-editing problem. Specifically, we explore both image-level and scene-level camouflage generation strategies, and fine-tune a ControlNet to synthesize camouflaged vehicles directly on real images. We design a unified objective that jointly enforces vehicle structural fidelity, style consistency, and adversarial effectiveness. Extensive experiments on the COCO and LINZ datasets show that our method achieves significantly stronger attack effectiveness, leading to more than 38% AP50 decrease, while better preserving vehicle structure and improving human-perceived stealthiness compared to existing approaches. Furthermore, our framework generalizes effectively to unseen black-box detectors and exhibits promising transferability to the physical world. Project page is available at https://humansensinglab.github.io/CtrlCamo
CITED: A Decision Boundary-Aware Signature for GNNs Towards Model Extraction Defense
Feb 23, 2026Graph neural networks (GNNs) have demonstrated superior performance in various applications, such as recommendation systems and financial risk management. However, deploying large-scale GNN models locally is particularly challenging for users, as it requires significant computational resources and extensive property data. Consequently, Machine Learning as a Service (MLaaS) has become increasingly popular, offering a convenient way to deploy and access various models, including GNNs. However, an emerging threat known as Model Extraction Attacks (MEAs) presents significant risks, as adversaries can readily obtain surrogate GNN models exhibiting similar functionality. Specifically, attackers repeatedly query the target model using subgraph inputs to collect corresponding responses. These input-output pairs are subsequently utilized to train their own surrogate models at minimal cost. Many techniques have been proposed to defend against MEAs, but most are limited to specific output levels (e.g., embedding or label) and suffer from inherent technical drawbacks. To address these limitations, we propose a novel ownership verification framework CITED which is a first-of-its-kind method to achieve ownership verification on both embedding and label levels. Moreover, CITED is a novel signature-based method that neither harms downstream performance nor introduces auxiliary models that reduce efficiency, while still outperforming all watermarking and fingerprinting approaches. Extensive experiments demonstrate the effectiveness and robustness of our CITED framework. Code is available at: https://github.com/LabRAI/CITED.
ACIL: Active Class Incremental Learning for Image Classification
Feb 04, 2026Continual learning (or class incremental learning) is a realistic learning scenario for computer vision systems, where deep neural networks are trained on episodic data, and the data from previous episodes are generally inaccessible to the model. Existing research in this domain has primarily focused on avoiding catastrophic forgetting, which occurs due to the continuously changing class distributions in each episode and the inaccessibility of the data from previous episodes. However, these methods assume that all the training samples in every episode are annotated; this not only incurs a huge annotation cost, but also results in a wastage of annotation effort, since most of the samples in a given episode will not be accessible to the model in subsequent episodes. Active learning algorithms identify the salient and informative samples from large amounts of unlabeled data and are instrumental in reducing the human annotation effort in inducing a deep neural network. In this paper, we propose ACIL, a novel active learning framework for class incremental learning settings. We exploit a criterion based on uncertainty and diversity to identify the exemplar samples that need to be annotated in each episode, and will be appended to the data in the next episode. Such a framework can drastically reduce annotation cost and can also avoid catastrophic forgetting. Our extensive empirical analyses on several vision datasets corroborate the promise and potential of our framework against relevant baselines.
Adapting Vehicle Detectors for Aerial Imagery to Unseen Domains with Weak Supervision
Jul 28, 2025Detecting vehicles in aerial imagery is a critical task with applications in traffic monitoring, urban planning, and defense intelligence. Deep learning methods have provided state-of-the-art (SOTA) results for this application. However, a significant challenge arises when models trained on data from one geographic region fail to generalize effectively to other areas. Variability in factors such as environmental conditions, urban layouts, road networks, vehicle types, and image acquisition parameters (e.g., resolution, lighting, and angle) leads to domain shifts that degrade model performance. This paper proposes a novel method that uses generative AI to synthesize high-quality aerial images and their labels, improving detector training through data augmentation. Our key contribution is the development of a multi-stage, multi-modal knowledge transfer framework utilizing fine-tuned latent diffusion models (LDMs) to mitigate the distribution gap between the source and target environments. Extensive experiments across diverse aerial imagery domains show consistent performance improvements in AP50 over supervised learning on source domain data, weakly supervised adaptation methods, unsupervised domain adaptation methods, and open-set object detectors by 4-23%, 6-10%, 7-40%, and more than 50%, respectively. Furthermore, we introduce two newly annotated aerial datasets from New Zealand and Utah to support further research in this field. Project page is available at: https://humansensinglab.github.io/AGenDA
FedAR: Addressing Client Unavailability in Federated Learning with Local Update Approximation and Rectification
Jul 26, 2024

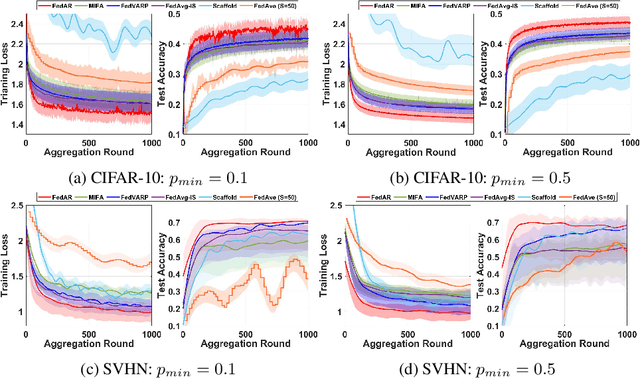

Federated learning (FL) enables clients to collaboratively train machine learning models under the coordination of a server in a privacy-preserving manner. One of the main challenges in FL is that the server may not receive local updates from each client in each round due to client resource limitations and intermittent network connectivity. The existence of unavailable clients severely deteriorates the overall FL performance. In this paper, we propose , a novel client update Approximation and Rectification algorithm for FL to address the client unavailability issue. FedAR can get all clients involved in the global model update to achieve a high-quality global model on the server, which also furnishes accurate predictions for each client. To this end, the server uses the latest update from each client as a surrogate for its current update. It then assigns a different weight to each client's surrogate update to derive the global model, in order to guarantee contributions from both available and unavailable clients. Our theoretical analysis proves that FedAR achieves optimal convergence rates on non-IID datasets for both convex and non-convex smooth loss functions. Extensive empirical studies show that FedAR comprehensively outperforms state-of-the-art FL baselines including FedAvg, MIFA, FedVARP and Scaffold in terms of the training loss, test accuracy, and bias mitigation. Moreover, FedAR also depicts impressive performance in the presence of a large number of clients with severe client unavailability.
D3GU: Multi-Target Active Domain Adaptation via Enhancing Domain Alignment
Jan 10, 2024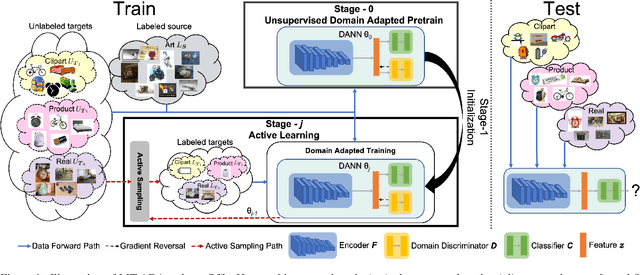
Unsupervised domain adaptation (UDA) for image classification has made remarkable progress in transferring classification knowledge from a labeled source domain to an unlabeled target domain, thanks to effective domain alignment techniques. Recently, in order to further improve performance on a target domain, many Single-Target Active Domain Adaptation (ST-ADA) methods have been proposed to identify and annotate the salient and exemplar target samples. However, it requires one model to be trained and deployed for each target domain and the domain label associated with each test sample. This largely restricts its application in the ubiquitous scenarios with multiple target domains. Therefore, we propose a Multi-Target Active Domain Adaptation (MT-ADA) framework for image classification, named D3GU, to simultaneously align different domains and actively select samples from them for annotation. This is the first research effort in this field to our best knowledge. D3GU applies Decomposed Domain Discrimination (D3) during training to achieve both source-target and target-target domain alignments. Then during active sampling, a Gradient Utility (GU) score is designed to weight every unlabeled target image by its contribution towards classification and domain alignment tasks, and is further combined with KMeans clustering to form GU-KMeans for diverse image sampling. Extensive experiments on three benchmark datasets, Office31, OfficeHome, and DomainNet, have been conducted to validate consistently superior performance of D3GU for MT-ADA.
Active Learning for Video Classification with Frame Level Queries
Jul 10, 2023
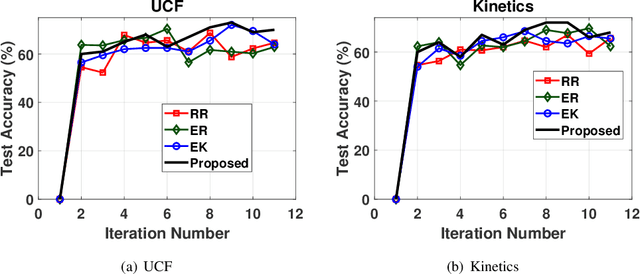
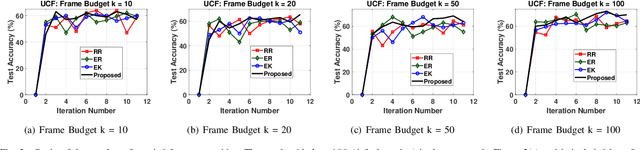
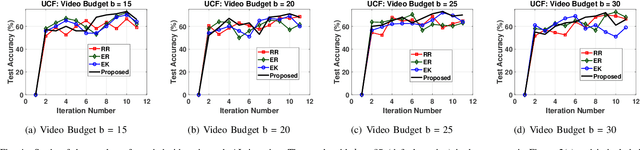
Deep learning algorithms have pushed the boundaries of computer vision research and have depicted commendable performance in a variety of applications. However, training a robust deep neural network necessitates a large amount of labeled training data, acquiring which involves significant time and human effort. This problem is even more serious for an application like video classification, where a human annotator has to watch an entire video end-to-end to furnish a label. Active learning algorithms automatically identify the most informative samples from large amounts of unlabeled data; this tremendously reduces the human annotation effort in inducing a machine learning model, as only the few samples that are identified by the algorithm, need to be labeled manually. In this paper, we propose a novel active learning framework for video classification, with the goal of further reducing the labeling onus on the human annotators. Our framework identifies a batch of exemplar videos, together with a set of informative frames for each video; the human annotator needs to merely review the frames and provide a label for each video. This involves much less manual work than watching the complete video to come up with a label. We formulate a criterion based on uncertainty and diversity to identify the informative videos and exploit representative sampling techniques to extract a set of exemplar frames from each video. To the best of our knowledge, this is the first research effort to develop an active learning framework for video classification, where the annotators need to inspect only a few frames to produce a label, rather than watching the end-to-end video.
Model Selection with Nonlinear Embedding for Unsupervised Domain Adaptation
Jun 23, 2017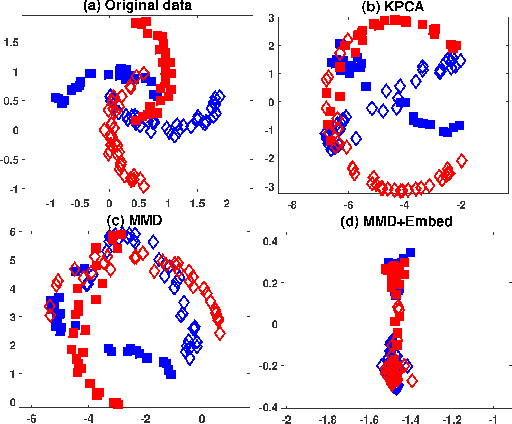

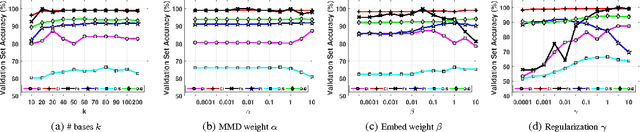
Domain adaptation deals with adapting classifiers trained on data from a source distribution, to work effectively on data from a target distribution. In this paper, we introduce the Nonlinear Embedding Transform (NET) for unsupervised domain adaptation. The NET reduces cross-domain disparity through nonlinear domain alignment. It also embeds the domain-aligned data such that similar data points are clustered together. This results in enhanced classification. To determine the parameters in the NET model (and in other unsupervised domain adaptation models), we introduce a validation procedure by sampling source data points that are similar in distribution to the target data. We test the NET and the validation procedure using popular image datasets and compare the classification results across competitive procedures for unsupervised domain adaptation.
Nonlinear Embedding Transform for Unsupervised Domain Adaptation
Jun 22, 2017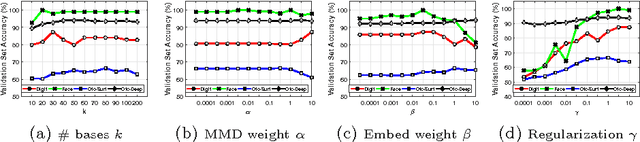
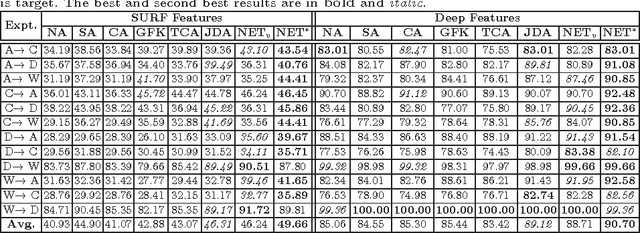
The problem of domain adaptation (DA) deals with adapting classifier models trained on one data distribution to different data distributions. In this paper, we introduce the Nonlinear Embedding Transform (NET) for unsupervised DA by combining domain alignment along with similarity-based embedding. We also introduce a validation procedure to estimate the model parameters for the NET algorithm using the source data. Comprehensive evaluations on multiple vision datasets demonstrate that the NET algorithm outperforms existing competitive procedures for unsupervised DA.
Deep Hashing Network for Unsupervised Domain Adaptation
Jun 22, 2017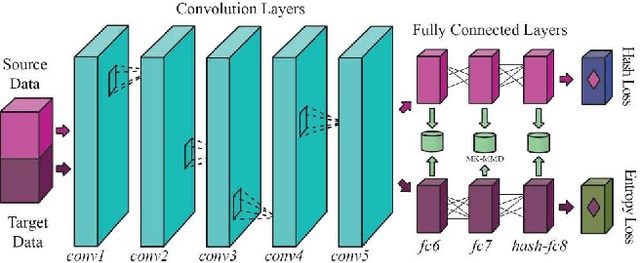


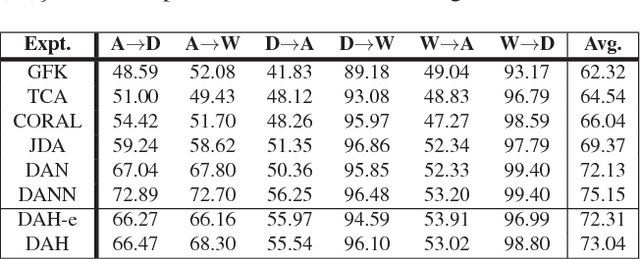
In recent years, deep neural networks have emerged as a dominant machine learning tool for a wide variety of application domains. However, training a deep neural network requires a large amount of labeled data, which is an expensive process in terms of time, labor and human expertise. Domain adaptation or transfer learning algorithms address this challenge by leveraging labeled data in a different, but related source domain, to develop a model for the target domain. Further, the explosive growth of digital data has posed a fundamental challenge concerning its storage and retrieval. Due to its storage and retrieval efficiency, recent years have witnessed a wide application of hashing in a variety of computer vision applications. In this paper, we first introduce a new dataset, Office-Home, to evaluate domain adaptation algorithms. The dataset contains images of a variety of everyday objects from multiple domains. We then propose a novel deep learning framework that can exploit labeled source data and unlabeled target data to learn informative hash codes, to accurately classify unseen target data. To the best of our knowledge, this is the first research effort to exploit the feature learning capabilities of deep neural networks to learn representative hash codes to address the domain adaptation problem. Our extensive empirical studies on multiple transfer tasks corroborate the usefulness of the framework in learning efficient hash codes which outperform existing competitive baselines for unsupervised domain adaptation.