 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogEval: A Comprehensive Benchmark Suite for Large Language Models In Log Analysis
Jul 02, 2024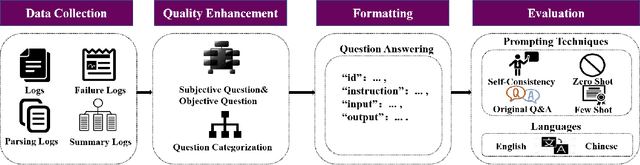
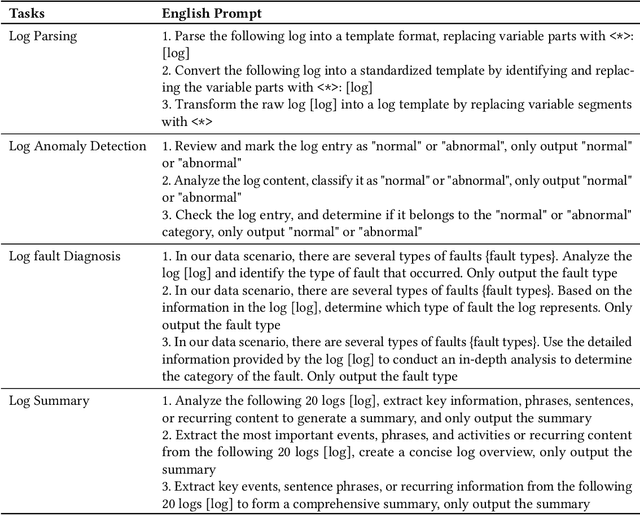

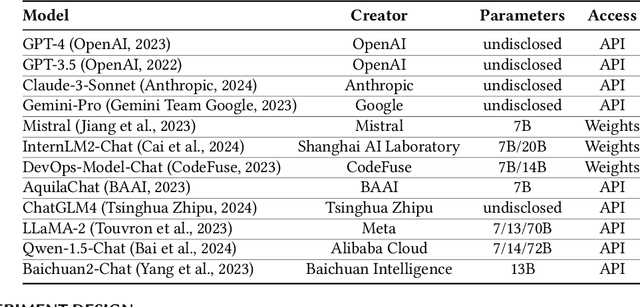
Log analysis is crucial for ensuring the orderly and stable operation of information systems, particularly in the field of Artificial Intelligence for IT Operations (AIOps). Large Language Models (LLMs) have demonstrated significant potential in natural language processing tasks. In the AIOps domain, they excel in tasks such as anomaly detection, root cause analysis of faults, operations and maintenance script generation, and alert information summarization. However, the performance of current LLMs in log analysis tasks remains inadequately validated. To address this gap, we introduce LogEval, a comprehensive benchmark suite designed to evaluate the capabilities of LLMs in various log analysis tasks for the first time. This benchmark covers tasks such as log parsing, log anomaly detection, log fault diagnosis, and log summarization. LogEval evaluates each task using 4,000 publicly available log data entries and employs 15 different prompts for each task to ensure a thorough and fair assessment. By rigorously evaluating leading LLMs, we demonstrate the impact of various LLM technologies on log analysis performance, focusing on aspects such as self-consistency and few-shot contextual learning. We also discuss findings related to model quantification, Chinese-English question-answering evaluation, and prompt engineering. These findings provide insights into the strengths and weaknesses of LLMs in multilingual environments and the effectiveness of different prompt strategies. Various evaluation methods are employed for different tasks to accurately measure the performance of LLMs in log analysis, ensuring a comprehensive assessment. The insights gained from LogEvals evaluation reveal the strengths and limitations of LLMs in log analysis tasks, providing valuable guidance for researchers and practitioners.
ALYMPICS: Language Agents Meet Game Theory
Nov 16, 2023This paper introduces Alympics, a platform that leverages Large Language Model (LLM) agents to facilitate investigations in game theory. By employing LLMs and autonomous agents to simulate human behavior and enable multi-agent collaborations, we can construct realistic and dynamic models of human interactions for game theory hypothesis formulating and testing. To demonstrate this, we present and implement a survival game involving unequal competition for limited resources. Through manipulation of resource availability and agent personalities, we observe how different agents engage in the competition and adapt their strategies. The use of LLM agents in game theory research offers significant advantages, including simulating realistic behavior, providing a controlled, scalable, and reproducible environment. Our work highlights the potential of LLM agents in enhancing the understanding of strategic decision-making within complex socioeconomic contexts. All codes are available at https://github.com/microsoft/Alympics
EIPE-text: Evaluation-Guided Iterative Plan Extraction for Long-Form Narrative Text Generation
Oct 12, 2023



Plan-and-Write is a common hierarchical approach in long-form narrative text generation, which first creates a plan to guide the narrative writing. Following this approach, several studies rely on simply prompting large language models for planning, which often yields suboptimal results. In this paper, we propose a new framework called Evaluation-guided Iterative Plan Extraction for long-form narrative text generation (EIPE-text), which extracts plans from the corpus of narratives and utilizes the extracted plans to construct a better planner. EIPE-text has three stages: plan extraction, learning, and inference. In the plan extraction stage, it iteratively extracts and improves plans from the narrative corpus and constructs a plan corpus. We propose a question answer (QA) based evaluation mechanism to automatically evaluate the plans and generate detailed plan refinement instructions to guide the iterative improvement. In the learning stage, we build a better planner by fine-tuning with the plan corpus or in-context learning with examples in the plan corpus. Finally, we leverage a hierarchical approach to generate long-form narratives. We evaluate the effectiveness of EIPE-text in the domains of novels and storytelling. Both GPT-4-based evaluations and human evaluations demonstrate that our method can generate more coherent and relevant long-form narratives. Our code will be released in the future.
Low-code LLM: Visual Programming over LLMs
Apr 20, 2023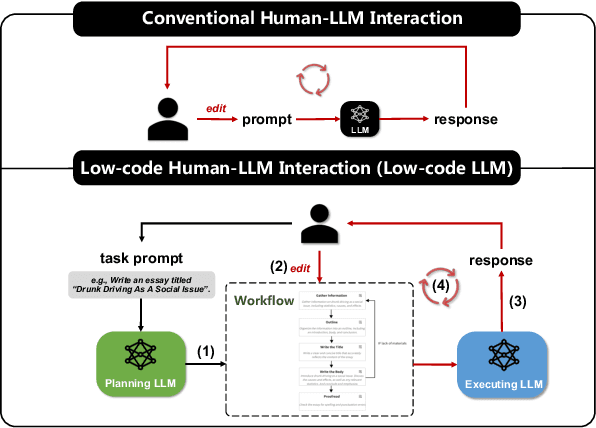

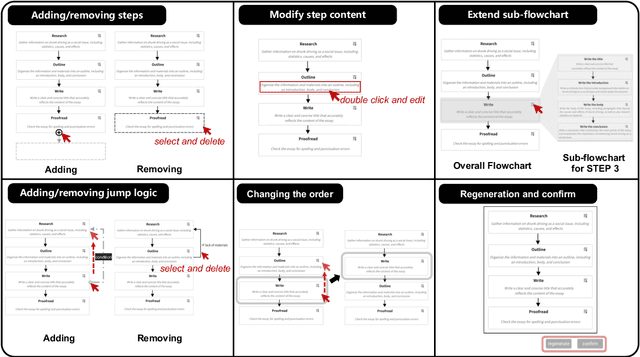

Effectively utilizing LLMs for complex tasks is challenging, often involving a time-consuming and uncontrollable prompt engineering process. This paper introduces a novel human-LLM interaction framework, Low-code LLM. It incorporates six types of simple low-code visual programming interactions, all supported by clicking, dragging, or text editing, to achieve more controllable and stable responses. Through visual interaction with a graphical user interface, users can incorporate their ideas into the workflow without writing trivial prompts. The proposed Low-code LLM framework consists of a Planning LLM that designs a structured planning workflow for complex tasks, which can be correspondingly edited and confirmed by users through low-code visual programming operations, and an Executing LLM that generates responses following the user-confirmed workflow. We highlight three advantages of the low-code LLM: controllable generation results, user-friendly human-LLM interaction, and broadly applicable scenarios. We demonstrate its benefits using four typical applications. By introducing this approach, we aim to bridge the gap between humans and LLMs, enabling more effective and efficient utilization of LLMs for complex tasks. Our system will be soon publicly available at LowCodeLLM.