 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025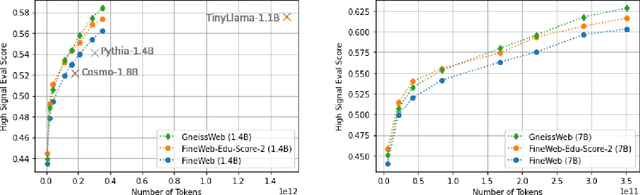
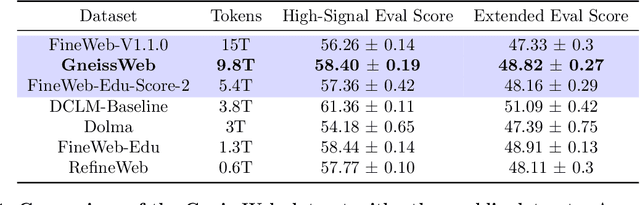
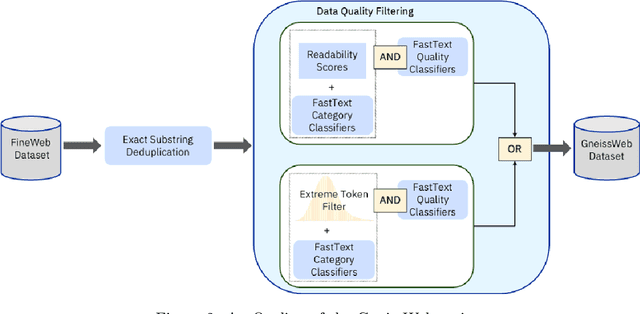

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
LogEval: A Comprehensive Benchmark Suite for Large Language Models In Log Analysis
Jul 02, 2024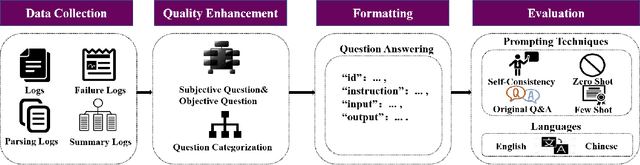
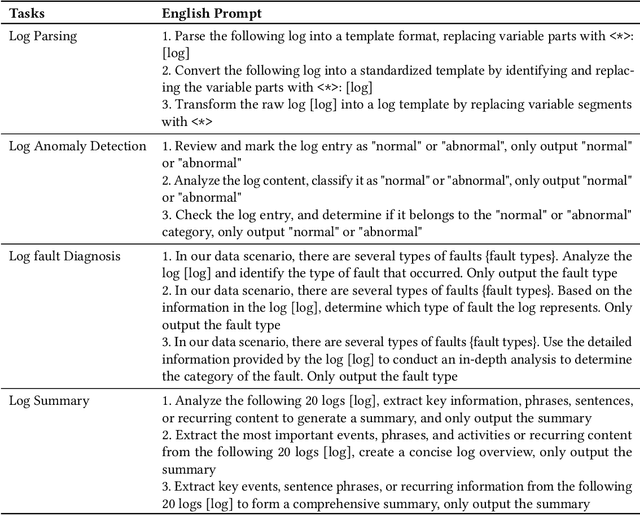

Log analysis is crucial for ensuring the orderly and stable operation of information systems, particularly in the field of Artificial Intelligence for IT Operations (AIOps). Large Language Models (LLMs) have demonstrated significant potential in natural language processing tasks. In the AIOps domain, they excel in tasks such as anomaly detection, root cause analysis of faults, operations and maintenance script generation, and alert information summarization. However, the performance of current LLMs in log analysis tasks remains inadequately validated. To address this gap, we introduce LogEval, a comprehensive benchmark suite designed to evaluate the capabilities of LLMs in various log analysis tasks for the first time. This benchmark covers tasks such as log parsing, log anomaly detection, log fault diagnosis, and log summarization. LogEval evaluates each task using 4,000 publicly available log data entries and employs 15 different prompts for each task to ensure a thorough and fair assessment. By rigorously evaluating leading LLMs, we demonstrate the impact of various LLM technologies on log analysis performance, focusing on aspects such as self-consistency and few-shot contextual learning. We also discuss findings related to model quantification, Chinese-English question-answering evaluation, and prompt engineering. These findings provide insights into the strengths and weaknesses of LLMs in multilingual environments and the effectiveness of different prompt strategies. Various evaluation methods are employed for different tasks to accurately measure the performance of LLMs in log analysis, ensuring a comprehensive assessment. The insights gained from LogEvals evaluation reveal the strengths and limitations of LLMs in log analysis tasks, providing valuable guidance for researchers and practitioners.
Federated Learning for Semantic Parsing: Task Formulation, Evaluation Setup, New Algorithms
May 26, 2023This paper studies a new task of federated learning (FL) for semantic parsing, where multiple clients collaboratively train one global model without sharing their semantic parsing data. By leveraging data from multiple clients, the FL paradigm can be especially beneficial for clients that have little training data to develop a data-hungry neural semantic parser on their own. We propose an evaluation setup to study this task, where we re-purpose widely-used single-domain text-to-SQL datasets as clients to form a realistic heterogeneous FL setting and collaboratively train a global model. As standard FL algorithms suffer from the high client heterogeneity in our realistic setup, we further propose a novel LOss Reduction Adjusted Re-weighting (Lorar) mechanism to mitigate the performance degradation, which adjusts each client's contribution to the global model update based on its training loss reduction during each round. Our intuition is that the larger the loss reduction, the further away the current global model is from the client's local optimum, and the larger weight the client should get. By applying Lorar to three widely adopted FL algorithms (FedAvg, FedOPT and FedProx), we observe that their performance can be improved substantially on average (4%-20% absolute gain under MacroAvg) and that clients with smaller datasets enjoy larger performance gains. In addition, the global model converges faster for almost all the clients.
Joint Coreset Construction and Quantization for Distributed Machine Learning
Apr 13, 2022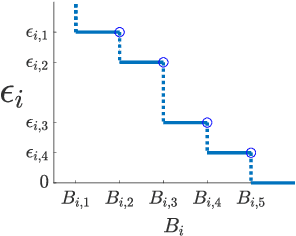
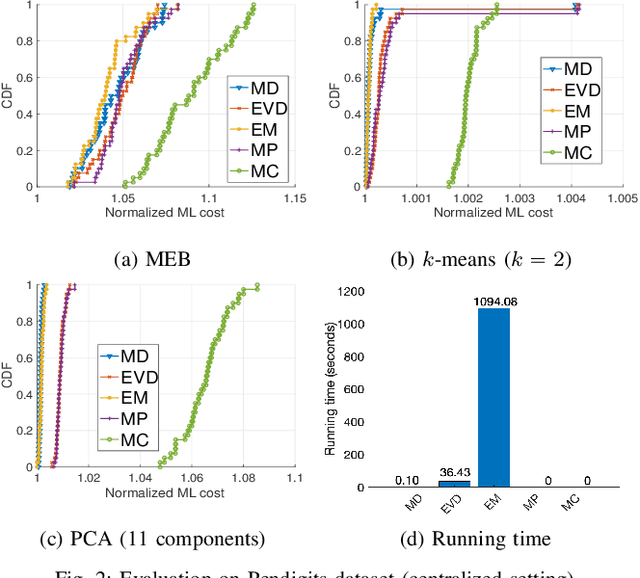
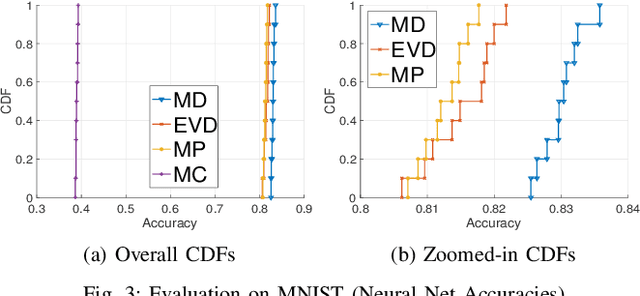
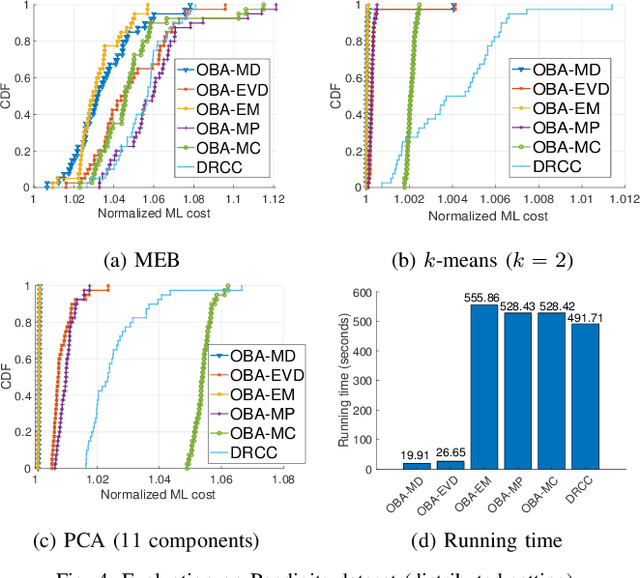
Coresets are small, weighted summaries of larger datasets, aiming at providing provable error bounds for machine learning (ML) tasks while significantly reducing the communication and computation costs. To achieve a better trade-off between ML error bounds and costs, we propose the first framework to incorporate quantization techniques into the process of coreset construction. Specifically, we theoretically analyze the ML error bounds caused by a combination of coreset construction and quantization. Based on that, we formulate an optimization problem to minimize the ML error under a fixed budget of communication cost. To improve the scalability for large datasets, we identify two proxies of the original objective function, for which efficient algorithms are developed. For the case of data on multiple nodes, we further design a novel algorithm to allocate the communication budget to the nodes while minimizing the overall ML error. Through extensive experiments on multiple real-world datasets, we demonstrate the effectiveness and efficiency of our proposed algorithms for a variety of ML tasks. In particular, our algorithms have achieved more than 90% data reduction with less than 10% degradation in ML performance in most cases.
Communication-efficient k-Means for Edge-based Machine Learning
Feb 08, 2021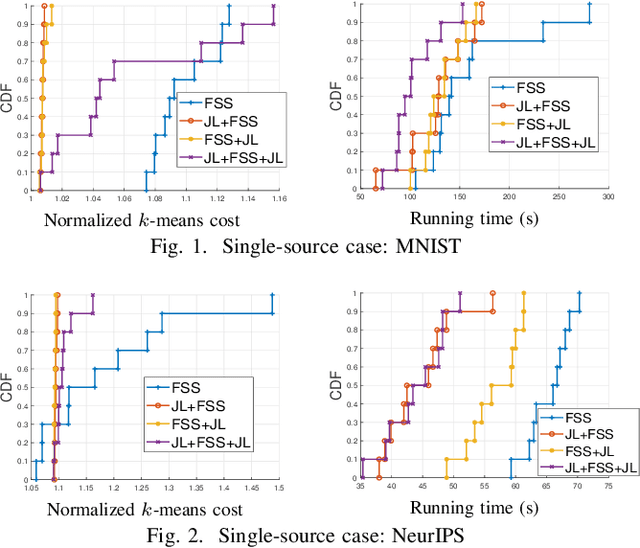
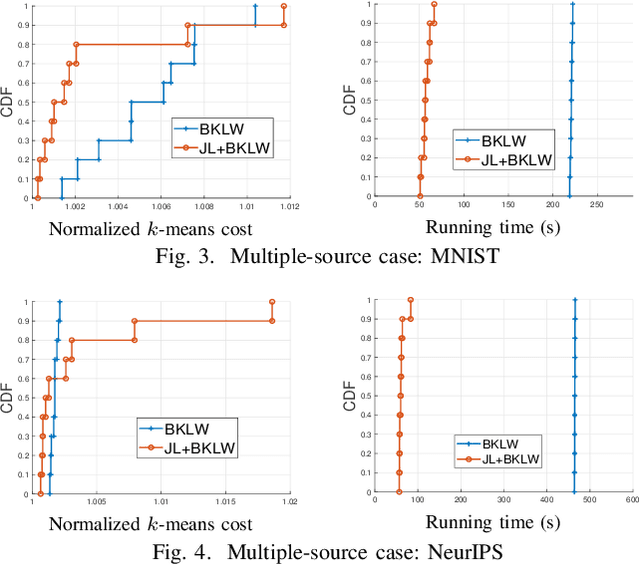
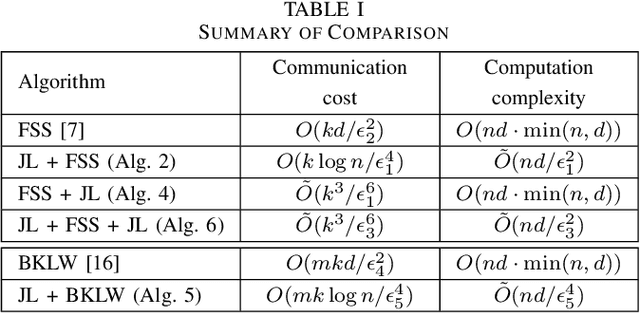
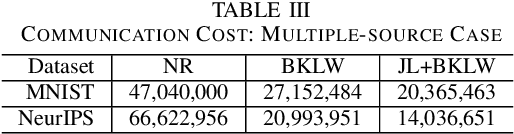
We consider the problem of computing the k-means centers for a large high-dimensional dataset in the context of edge-based machine learning, where data sources offload machine learning computation to nearby edge servers. k-Means computation is fundamental to many data analytics, and the capability of computing provably accurate k-means centers by leveraging the computation power of the edge servers, at a low communication and computation cost to the data sources, will greatly improve the performance of these analytics. We propose to let the data sources send small summaries, generated by joint dimensionality reduction (DR) and cardinality reduction (CR), to support approximate k-means computation at reduced complexity and communication cost. By analyzing the complexity, the communication cost, and the approximation error of k-means algorithms based on state-of-the-art DR/CR methods, we show that: (i) it is possible to achieve a near-optimal approximation at a near-linear complexity and a constant or logarithmic communication cost, (ii) the order of applying DR and CR significantly affects the complexity and the communication cost, and (iii) combining DR/CR methods with a properly configured quantizer can further reduce the communication cost without compromising the other performance metrics. Our findings are validated through experiments based on real datasets.
Sharing Models or Coresets: A Study based on Membership Inference Attack
Jul 06, 2020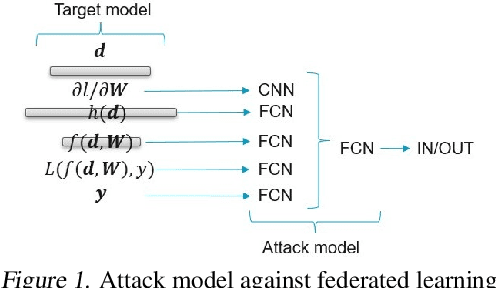
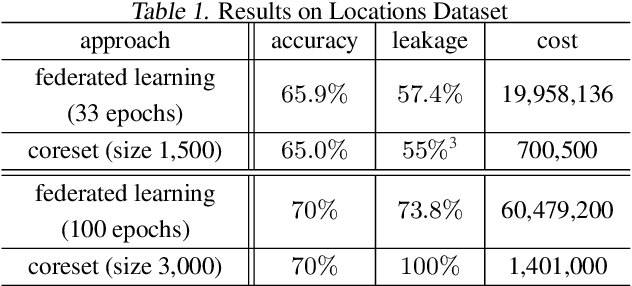
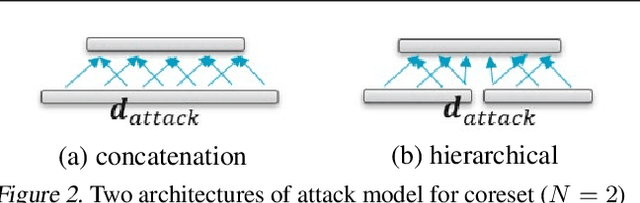
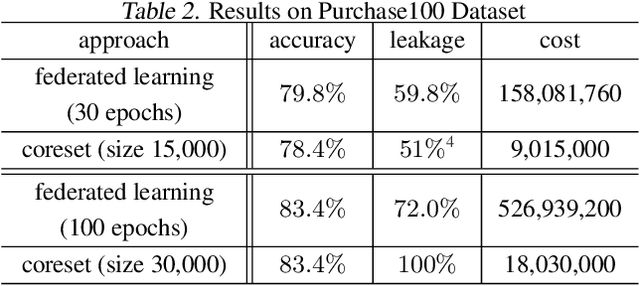
Distributed machine learning generally aims at training a global model based on distributed data without collecting all the data to a centralized location, where two different approaches have been proposed: collecting and aggregating local models (federated learning) and collecting and training over representative data summaries (coreset). While each approach preserves data privacy to some extent thanks to not sharing the raw data, the exact extent of protection is unclear under sophisticated attacks that try to infer the raw data from the shared information. We present the first comparison between the two approaches in terms of target model accuracy, communication cost, and data privacy, where the last is measured by the accuracy of a state-of-the-art attack strategy called the membership inference attack. Our experiments quantify the accuracy-privacy-cost tradeoff of each approach, and reveal a nontrivial comparison that can be used to guide the design of model training processes.
Data Selection for Federated Learning with Relevant and Irrelevant Data at Clients
Jan 22, 2020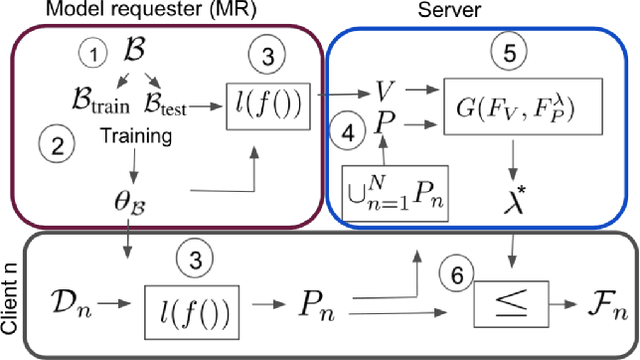

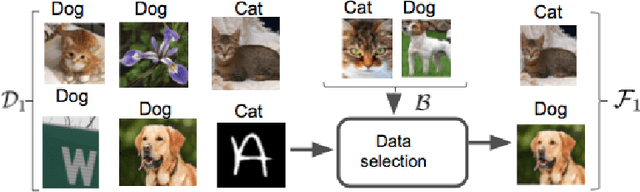
Federated learning is an effective way of training a machine learning model from data collected by client devices. A challenge is that among the large variety of data collected at each client, it is likely that only a subset is relevant for a learning task while the rest of data has a negative impact on model training. Therefore, before starting the learning process, it is important to select the subset of data that is relevant to the given federated learning task. In this paper, we propose a method for distributedly selecting relevant data, where we use a benchmark model trained on a small benchmark dataset that is task-specific, to evaluate the relevance of individual data samples at each client and select the data with sufficiently high relevance. Then, each client only uses the selected subset of its data in the federated learning process. The effectiveness of our proposed approach is evaluated on multiple real-world datasets in a simulated system with a large number of clients, showing up to $25\%$ improvement in model accuracy compared to training with all data.