 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Selection for Federated Learning with Relevant and Irrelevant Data at Clients
Jan 22, 2020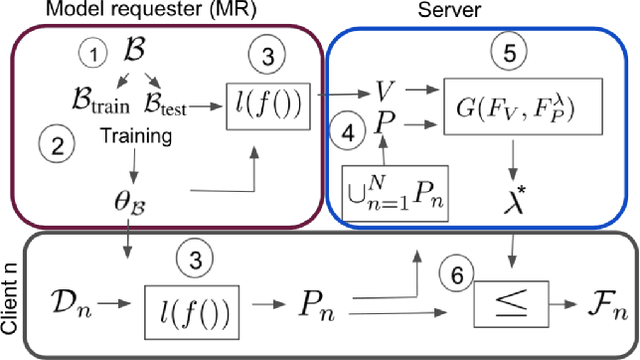

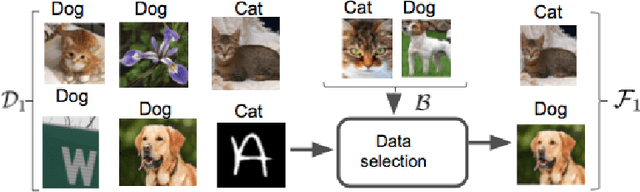
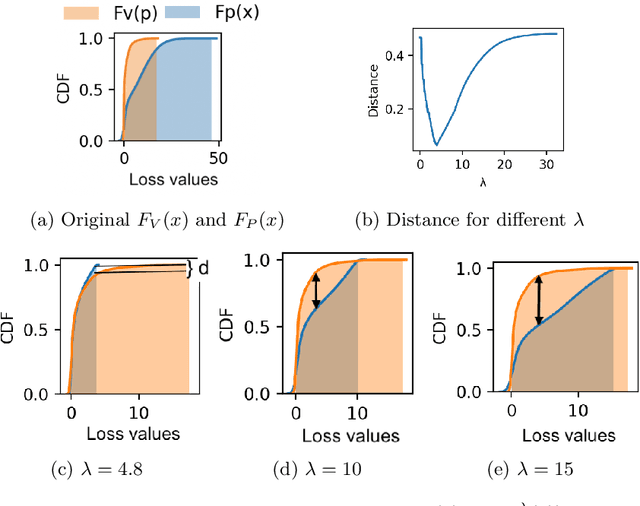
Federated learning is an effective way of training a machine learning model from data collected by client devices. A challenge is that among the large variety of data collected at each client, it is likely that only a subset is relevant for a learning task while the rest of data has a negative impact on model training. Therefore, before starting the learning process, it is important to select the subset of data that is relevant to the given federated learning task. In this paper, we propose a method for distributedly selecting relevant data, where we use a benchmark model trained on a small benchmark dataset that is task-specific, to evaluate the relevance of individual data samples at each client and select the data with sufficiently high relevance. Then, each client only uses the selected subset of its data in the federated learning process. The effectiveness of our proposed approach is evaluated on multiple real-world datasets in a simulated system with a large number of clients, showing up to $25\%$ improvement in model accuracy compared to training with all data.
Model Pruning Enables Efficient Federated Learning on Edge Devices
Sep 26, 2019
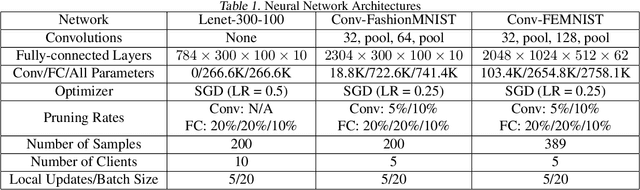
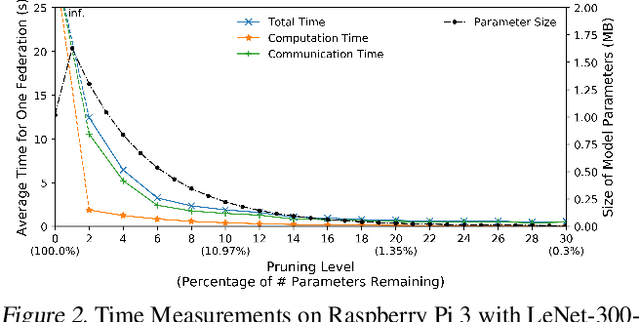
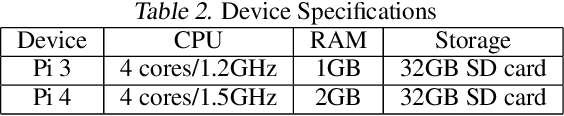
Federated learning is a recent approach for distributed model training without sharing the raw data of clients. It allows model training using the large amount of user data collected by edge and mobile devices, while preserving data privacy. A challenge in federated learning is that the devices usually have much lower computational power and communication bandwidth than machines in data centers. Training large-sized deep neural networks in such a federated setting can consume a large amount of time and resources. To overcome this challenge, we propose a method that integrates model pruning with federated learning in this paper, which includes initial model pruning at the server, further model pruning as part of the federated learning process, followed by the regular federated learning procedure. Our proposed approach can save the computation, communication, and storage costs compared to standard federated learning approaches. Extensive experiments on real edge devices validate the benefit of our proposed method.
Online Collection and Forecasting of Resource Utilization in Large-Scale Distributed Systems
May 22, 2019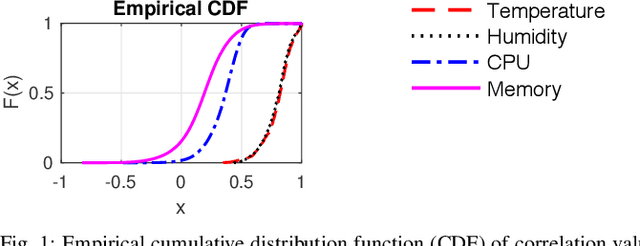
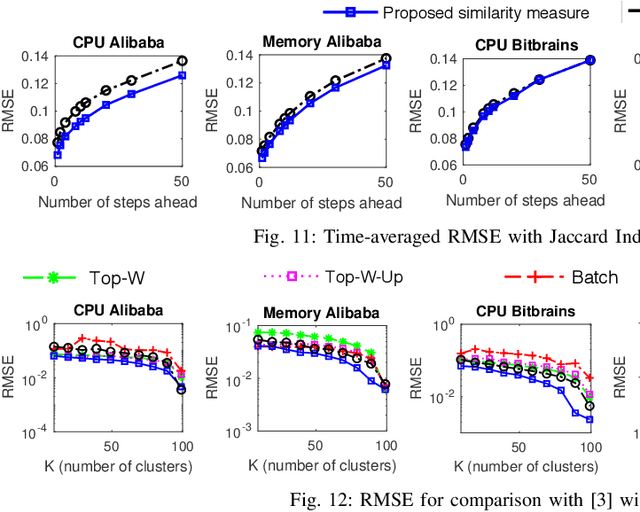
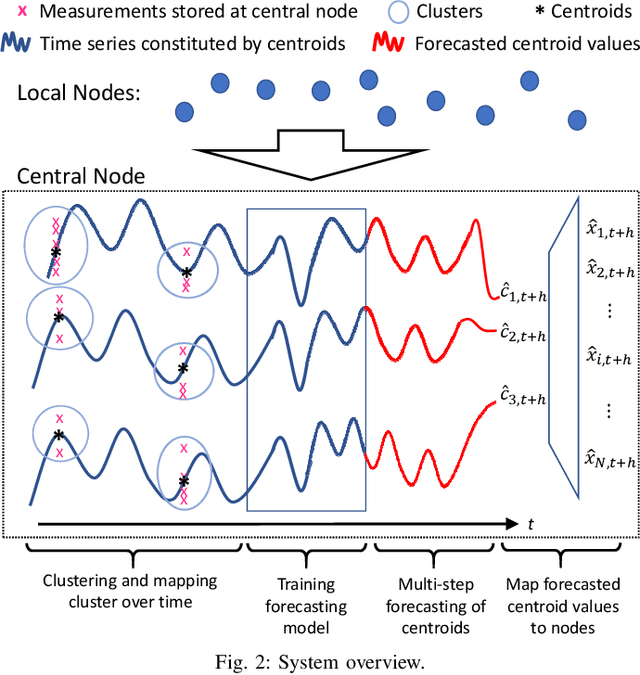

Large-scale distributed computing systems often contain thousands of distributed nodes (machines). Monitoring the conditions of these nodes is important for system management purposes, which, however, can be extremely resource demanding as this requires collecting local measurements of each individual node and constantly sending those measurements to a central controller. Meanwhile, it is often useful to forecast the future system conditions for various purposes such as resource planning/allocation and anomaly detection, but it is usually too resource-consuming to have one forecasting model running for each node, which may also neglect correlations in observed metrics across different nodes. In this paper, we propose a mechanism for collecting and forecasting the resource utilization of machines in a distributed computing system in a scalable manner. We present an algorithm that allows each local node to decide when to transmit its most recent measurement to the central node, so that the transmission frequency is kept below a given constraint value. Based on the measurements received from local nodes, the central node summarizes the received data into a small number of clusters. Since the cluster partitioning can change over time, we also present a method to capture the evolution of clusters and their centroids. As an effective way to reduce the amount of computation, time-series forecasting models are trained on the time-varying centroids of each cluster, to forecast the future resource utilizations of a group of local nodes. The effectiveness of our proposed approach is confirmed by extensive experiments using multiple real-world datasets.