 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Collaborative Learning Across Data Silos
Mar 23, 2022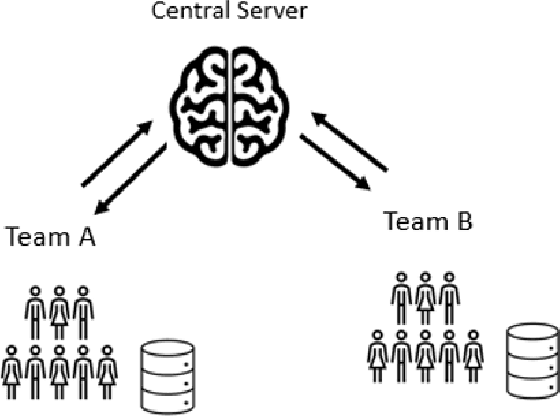
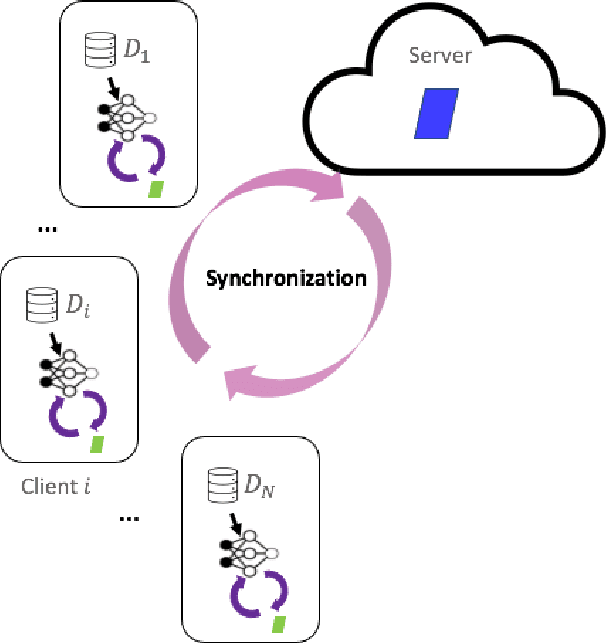
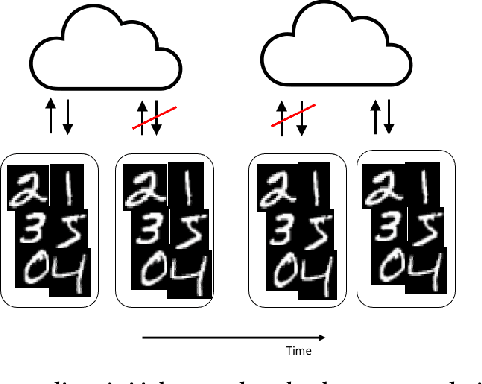
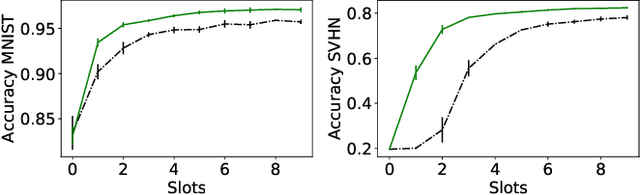
Machine learning algorithms can perform well when trained on large datasets. While large organisations often have considerable data assets, it can be difficult for these assets to be unified in a manner that makes training possible. Data is very often 'siloed' in different parts of the organisation, with little to no access between silos. This fragmentation of data assets is especially prevalent in heavily regulated industries like financial services or healthcare. In this paper we propose a framework to enable asynchronous collaborative training of machine learning models across data silos. This allows data science teams to collaboratively train a machine learning model, without sharing data with one another. Our proposed approach enhances conventional federated learning techniques to make them suitable for this asynchronous training in this intra-organisation, cross-silo setting. We validate our proposed approach via extensive experiments.
Data Selection for Federated Learning with Relevant and Irrelevant Data at Clients
Jan 22, 2020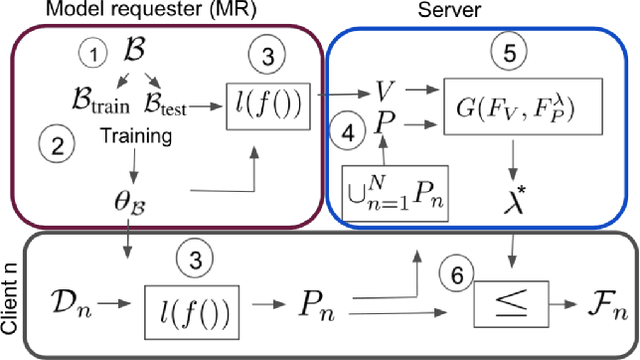

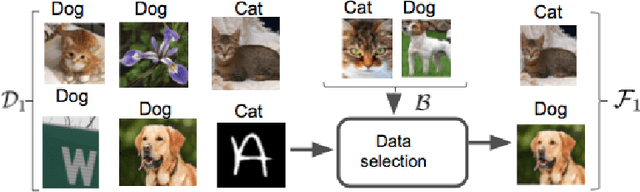
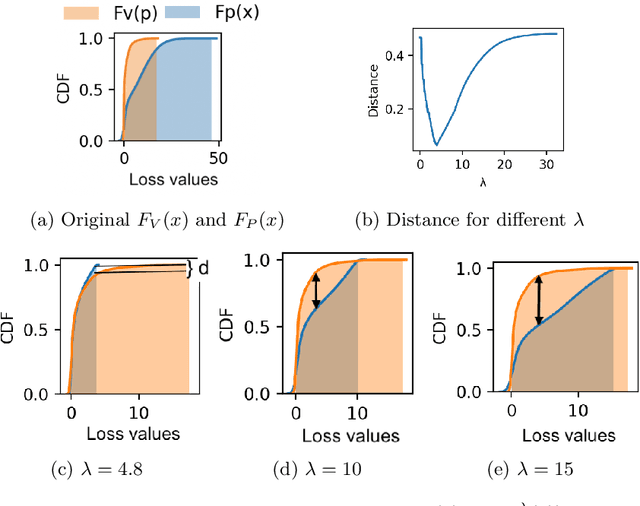
Federated learning is an effective way of training a machine learning model from data collected by client devices. A challenge is that among the large variety of data collected at each client, it is likely that only a subset is relevant for a learning task while the rest of data has a negative impact on model training. Therefore, before starting the learning process, it is important to select the subset of data that is relevant to the given federated learning task. In this paper, we propose a method for distributedly selecting relevant data, where we use a benchmark model trained on a small benchmark dataset that is task-specific, to evaluate the relevance of individual data samples at each client and select the data with sufficiently high relevance. Then, each client only uses the selected subset of its data in the federated learning process. The effectiveness of our proposed approach is evaluated on multiple real-world datasets in a simulated system with a large number of clients, showing up to $25\%$ improvement in model accuracy compared to training with all data.
Online Collection and Forecasting of Resource Utilization in Large-Scale Distributed Systems
May 22, 2019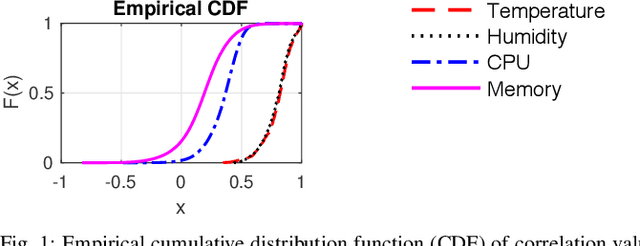
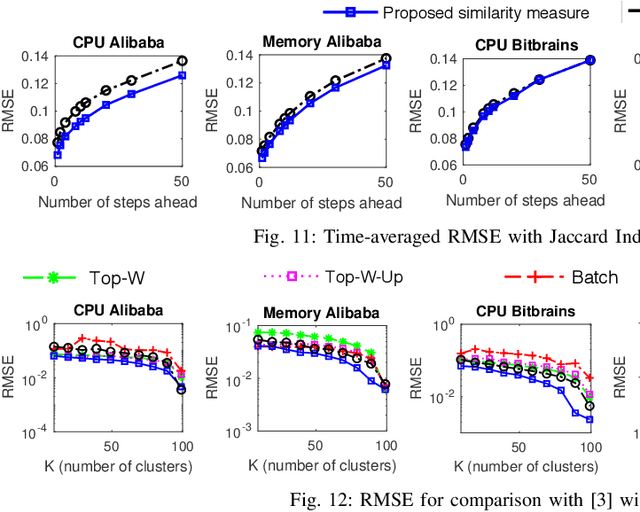
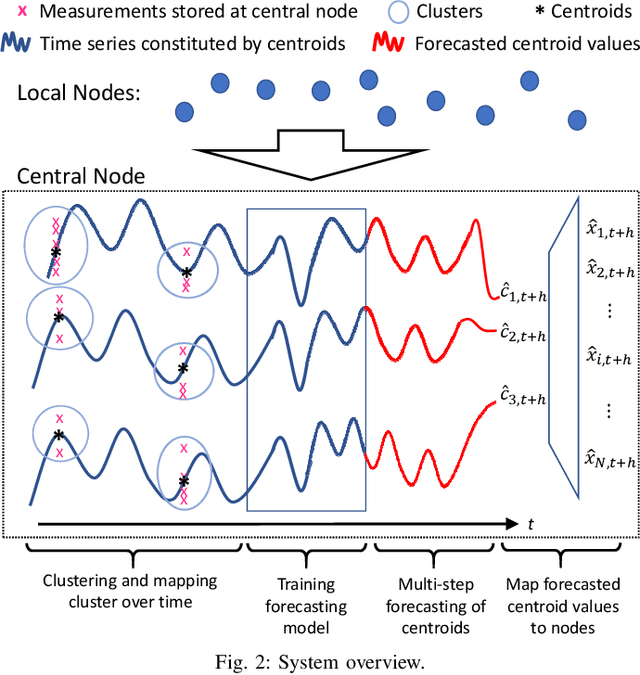

Large-scale distributed computing systems often contain thousands of distributed nodes (machines). Monitoring the conditions of these nodes is important for system management purposes, which, however, can be extremely resource demanding as this requires collecting local measurements of each individual node and constantly sending those measurements to a central controller. Meanwhile, it is often useful to forecast the future system conditions for various purposes such as resource planning/allocation and anomaly detection, but it is usually too resource-consuming to have one forecasting model running for each node, which may also neglect correlations in observed metrics across different nodes. In this paper, we propose a mechanism for collecting and forecasting the resource utilization of machines in a distributed computing system in a scalable manner. We present an algorithm that allows each local node to decide when to transmit its most recent measurement to the central node, so that the transmission frequency is kept below a given constraint value. Based on the measurements received from local nodes, the central node summarizes the received data into a small number of clusters. Since the cluster partitioning can change over time, we also present a method to capture the evolution of clusters and their centroids. As an effective way to reduce the amount of computation, time-series forecasting models are trained on the time-varying centroids of each cluster, to forecast the future resource utilizations of a group of local nodes. The effectiveness of our proposed approach is confirmed by extensive experiments using multiple real-world datasets.
Adaptive Federated Learning in Resource Constrained Edge Computing Systems
Aug 02, 2018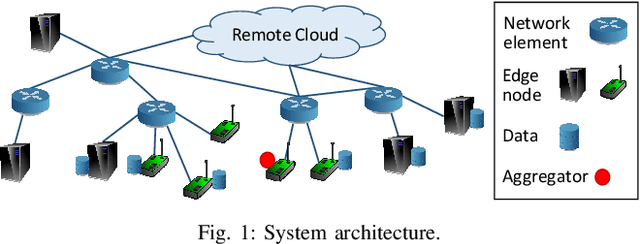
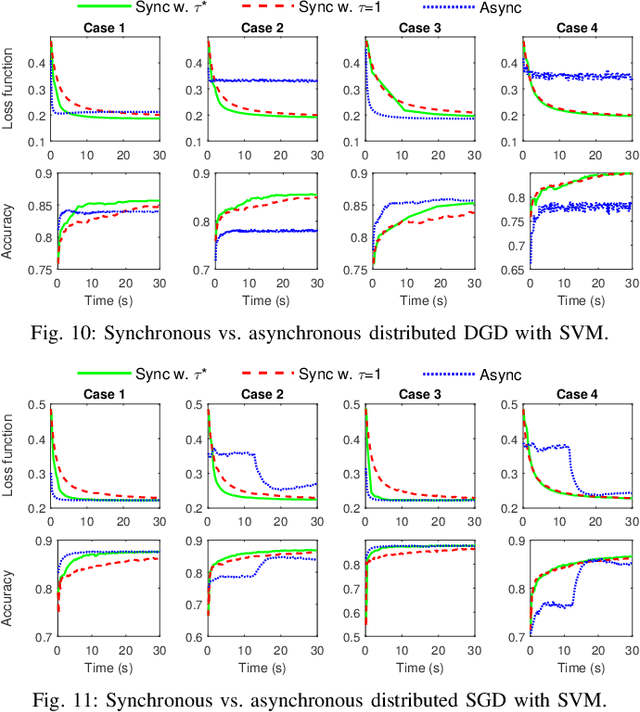
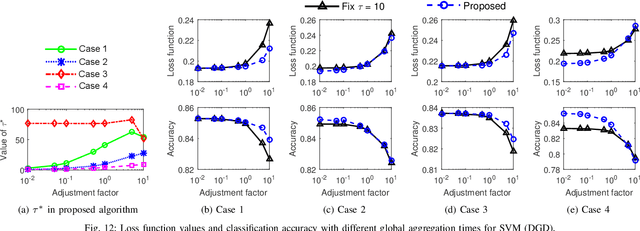
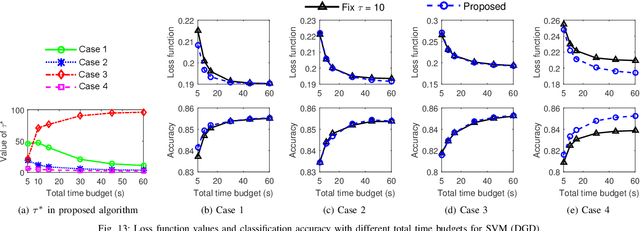
Emerging technologies and applications including Internet of Things (IoT), social networking, and crowd-sourcing generate large amounts of data at the network edge. Machine learning models are often built from the collected data, to enable the detection, classification, and prediction of future events. Due to bandwidth, storage, and privacy concerns, it is often impractical to send all the data to a centralized location. In this paper, we consider the problem of learning model parameters from data distributed across multiple edge nodes, without sending raw data to a centralized place. Our focus is on a generic class of machine learning models that are trained using gradient-descent based approaches. We analyze the convergence bound of distributed gradient descent from a theoretical point of view, based on which we propose a control algorithm that determines the best trade-off between local update and global parameter aggregation to minimize the loss function under a given resource budget. The performance of the proposed algorithm is evaluated via extensive experiments with real datasets, both on a networked prototype system and in a larger-scale simulated environment. The experimentation results show that our proposed approach performs near to the optimum with various machine learning models and different data distributions.