 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Selection for Federated Learning with Relevant and Irrelevant Data at Clients
Paper and Code
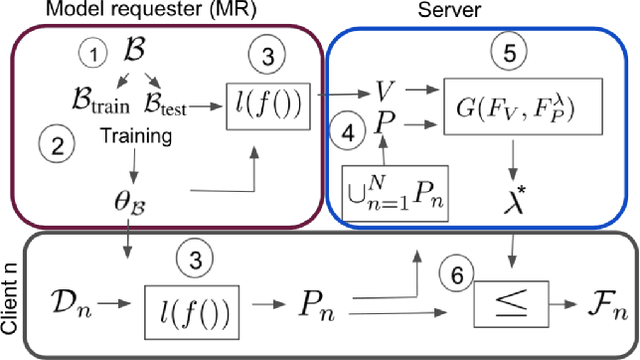

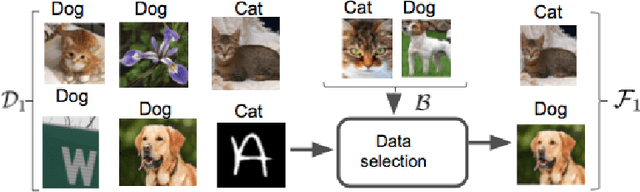
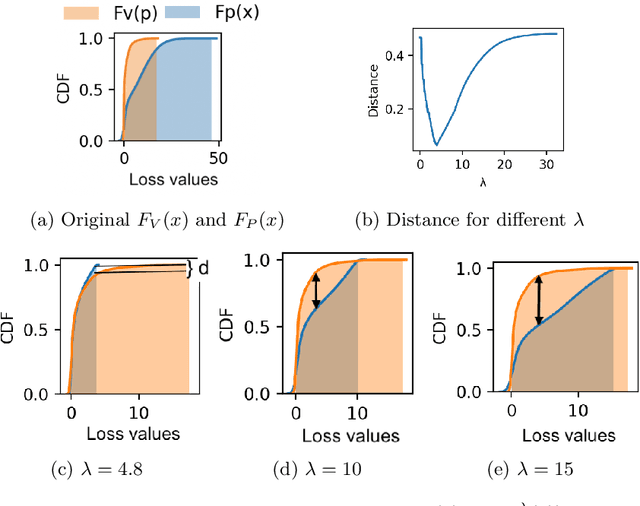
Federated learning is an effective way of training a machine learning model from data collected by client devices. A challenge is that among the large variety of data collected at each client, it is likely that only a subset is relevant for a learning task while the rest of data has a negative impact on model training. Therefore, before starting the learning process, it is important to select the subset of data that is relevant to the given federated learning task. In this paper, we propose a method for distributedly selecting relevant data, where we use a benchmark model trained on a small benchmark dataset that is task-specific, to evaluate the relevance of individual data samples at each client and select the data with sufficiently high relevance. Then, each client only uses the selected subset of its data in the federated learning process. The effectiveness of our proposed approach is evaluated on multiple real-world datasets in a simulated system with a large number of clients, showing up to $25\%$ improvement in model accuracy compared to training with all data.