 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMKG-Rank: Enhancing Large Language Models with Knowledge Graph for Multilingual Medical Question Answering
Mar 21, 2025Large Language Models (LLMs) have shown remarkable progress in medical question answering (QA), yet their effectiveness remains predominantly limited to English due to imbalanced multilingual training data and scarce medical resources for low-resource languages. To address this critical language gap in medical QA, we propose Multilingual Knowledge Graph-based Retrieval Ranking (MKG-Rank), a knowledge graph-enhanced framework that enables English-centric LLMs to perform multilingual medical QA. Through a word-level translation mechanism, our framework efficiently integrates comprehensive English-centric medical knowledge graphs into LLM reasoning at a low cost, mitigating cross-lingual semantic distortion and achieving precise medical QA across language barriers. To enhance efficiency, we introduce caching and multi-angle ranking strategies to optimize the retrieval process, significantly reducing response times and prioritizing relevant medical knowledge. Extensive evaluations on multilingual medical QA benchmarks across Chinese, Japanese, Korean, and Swahili demonstrate that MKG-Rank consistently outperforms zero-shot LLMs, achieving maximum 35.03% increase in accuracy, while maintaining an average retrieval time of only 0.0009 seconds.
Graphusion: A RAG Framework for Knowledge Graph Construction with a Global Perspective
Oct 23, 2024



Knowledge Graphs (KGs) are crucial in the field of artificial intelligence and are widely used in downstream tasks, such as question-answering (QA). The construction of KGs typically requires significant effort from domain experts. Large Language Models (LLMs) have recently been used for Knowledge Graph Construction (KGC). However, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents, missing a fusion process to combine the knowledge in a global KG. This work introduces Graphusion, a zero-shot KGC framework from free text. It contains three steps: in Step 1, we extract a list of seed entities using topic modeling to guide the final KG includes the most relevant entities; in Step 2, we conduct candidate triplet extraction using LLMs; in Step 3, we design the novel fusion module that provides a global view of the extracted knowledge, incorporating entity merging, conflict resolution, and novel triplet discovery. Results show that Graphusion achieves scores of 2.92 and 2.37 out of 3 for entity extraction and relation recognition, respectively. Moreover, we showcase how Graphusion could be applied to the Natural Language Processing (NLP) domain and validate it in an educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for QA, comprising six tasks and a total of 1,200 QA pairs. Using the Graphusion-constructed KG, we achieve a significant improvement on the benchmark, for example, a 9.2% accuracy improvement on sub-graph completion.
SplitLLM: Collaborative Inference of LLMs for Model Placement and Throughput Optimization
Oct 14, 2024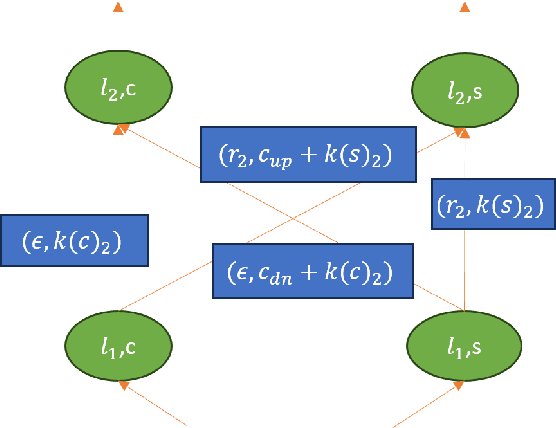

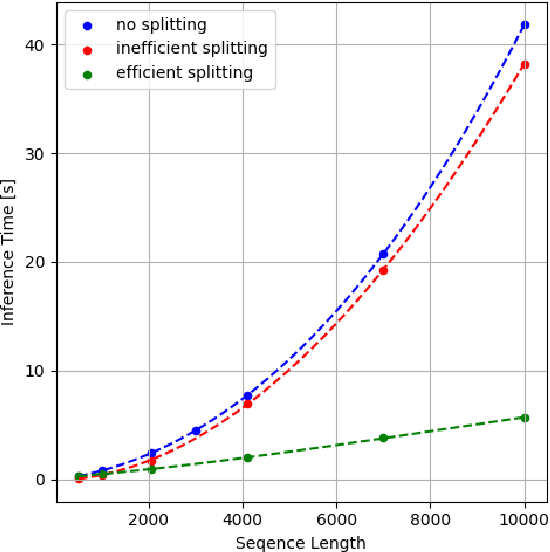
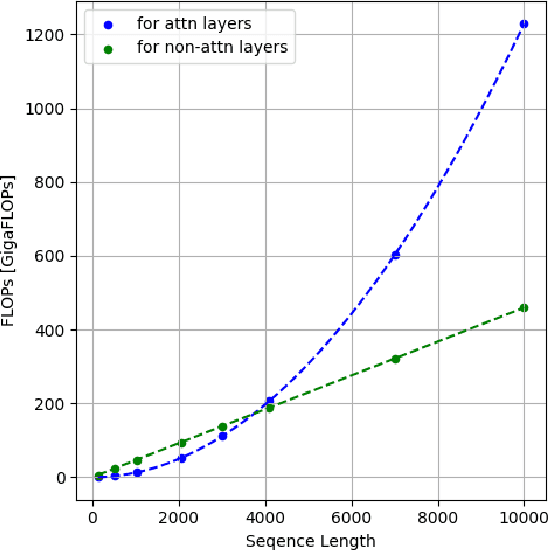
Large language models (LLMs) have been a disruptive innovation in recent years, and they play a crucial role in our daily lives due to their ability to understand and generate human-like text. Their capabilities include natural language understanding, information retrieval and search, translation, chatbots, virtual assistance, and many more. However, it is well known that LLMs are massive in terms of the number of parameters. Additionally, the self-attention mechanism in the underlying architecture of LLMs, Transformers, has quadratic complexity in terms of both computation and memory with respect to the input sequence length. For these reasons, LLM inference is resource-intensive, and thus, the throughput of LLM inference is limited, especially for the longer sequences. In this report, we design a collaborative inference architecture between a server and its clients to alleviate the throughput limit. In this design, we consider the available resources on both sides, i.e., the computation and communication costs. We develop a dynamic programming-based algorithm to optimally allocate computation between the server and the client device to increase the server throughput, while not violating the service level agreement (SLA). We show in the experiments that we are able to efficiently distribute the workload allowing for roughly 1/3 reduction in the server workload, while achieving 19 percent improvement over a greedy method. As a result, we are able to demonstrate that, in an environment with different types of LLM inference requests, the throughput of the server is improved.
Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education
Jul 15, 2024



Knowledge graphs (KGs) are crucial in the field of artificial intelligence and are widely applied in downstream tasks, such as enhancing Question Answering (QA) systems. The construction of KGs typically requires significant effort from domain experts. Recently, Large Language Models (LLMs) have been used for knowledge graph construction (KGC), however, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents. In this work, we introduce Graphusion, a zero-shot KGC framework from free text. The core fusion module provides a global view of triplets, incorporating entity merging, conflict resolution, and novel triplet discovery. We showcase how Graphusion could be applied to the natural language processing (NLP) domain and validate it in the educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for graph reasoning and QA, comprising six tasks and a total of 1,200 QA pairs. Our evaluation demonstrates that Graphusion surpasses supervised baselines by up to 10% in accuracy on link prediction. Additionally, it achieves average scores of 2.92 and 2.37 out of 3 in human evaluations for concept entity extraction and relation recognition, respectively.
Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
Feb 22, 2024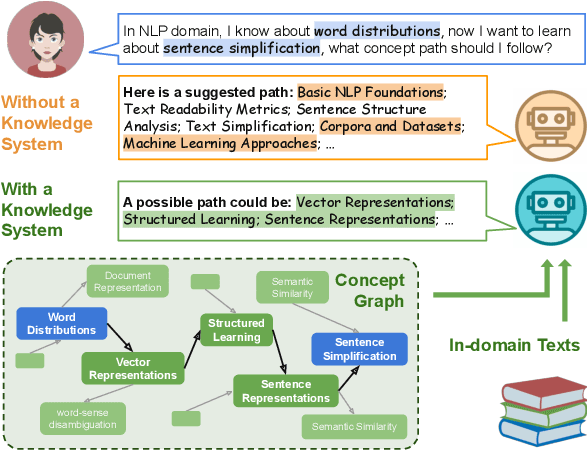
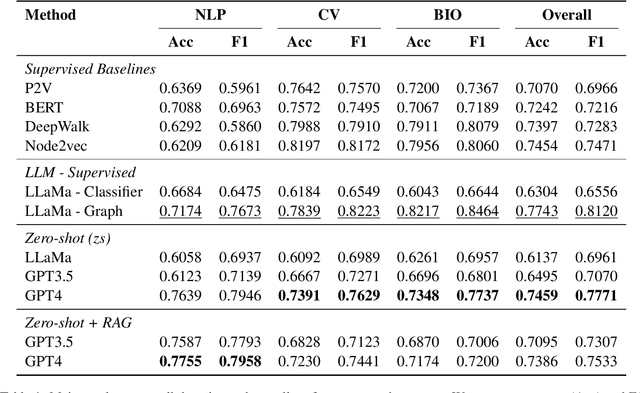
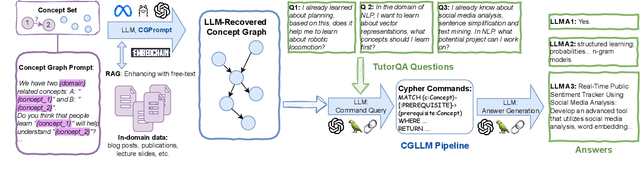

In the domain of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated promise in text-generation tasks. However, their educational applications, particularly for domain-specific queries, remain underexplored. This study investigates LLMs' capabilities in educational scenarios, focusing on concept graph recovery and question-answering (QA). We assess LLMs' zero-shot performance in creating domain-specific concept graphs and introduce TutorQA, a new expert-verified NLP-focused benchmark for scientific graph reasoning and QA. TutorQA consists of five tasks with 500 QA pairs. To tackle TutorQA queries, we present CGLLM, a pipeline integrating concept graphs with LLMs for answering diverse questions. Our results indicate that LLMs' zero-shot concept graph recovery is competitive with supervised methods, showing an average 3% F1 score improvement. In TutorQA tasks, LLMs achieve up to 26% F1 score enhancement. Moreover, human evaluation and analysis show that CGLLM generates answers with more fine-grained concepts.
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Sep 06, 2023Large Language Models (LLMs) have achieved significant success across various natural language processing (NLP) tasks, encompassing question-answering, summarization, and machine translation, among others. While LLMs excel in general tasks, their efficacy in domain-specific applications remains under exploration. Additionally, LLM-generated text sometimes exhibits issues like hallucination and disinformation. In this study, we assess LLMs' capability of producing concise survey articles within the computer science-NLP domain, focusing on 20 chosen topics. Automated evaluations indicate that GPT-4 outperforms GPT-3.5 when benchmarked against the ground truth. Furthermore, four human evaluators provide insights from six perspectives across four model configurations. Through case studies, we demonstrate that while GPT often yields commendable results, there are instances of shortcomings, such as incomplete information and the exhibition of lapses in factual accuracy.
Robust and Resource-efficient Machine Learning Aided Viewport Prediction in Virtual Reality
Dec 20, 2022



360-degree panoramic videos have gained considerable attention in recent years due to the rapid development of head-mounted displays (HMDs) and panoramic cameras. One major problem in streaming panoramic videos is that panoramic videos are much larger in size compared to traditional ones. Moreover, the user devices are often in a wireless environment, with limited battery, computation power, and bandwidth. To reduce resource consumption, researchers have proposed ways to predict the users' viewports so that only part of the entire video needs to be transmitted from the server. However, the robustness of such prediction approaches has been overlooked in the literature: it is usually assumed that only a few models, pre-trained on past users' experiences, are applied for prediction to all users. We observe that those pre-trained models can perform poorly for some users because they might have drastically different behaviors from the majority, and the pre-trained models cannot capture the features in unseen videos. In this work, we propose a novel meta learning based viewport prediction paradigm to alleviate the worst prediction performance and ensure the robustness of viewport prediction. This paradigm uses two machine learning models, where the first model predicts the viewing direction, and the second model predicts the minimum video prefetch size that can include the actual viewport. We first train two meta models so that they are sensitive to new training data, and then quickly adapt them to users while they are watching the videos. Evaluation results reveal that the meta models can adapt quickly to each user, and can significantly increase the prediction accuracy, especially for the worst-performing predictions.
Model Pruning Enables Efficient Federated Learning on Edge Devices
Sep 26, 2019
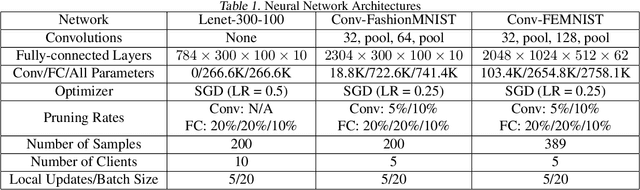
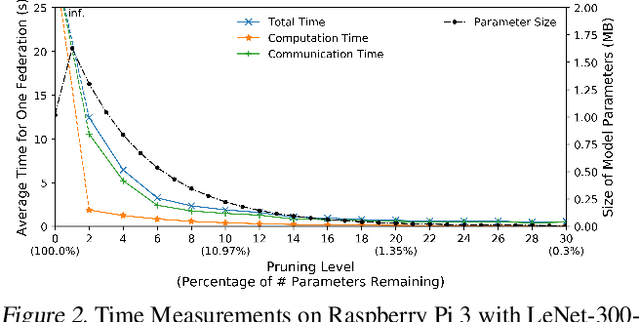
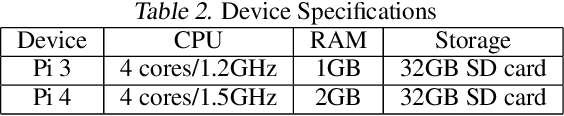
Federated learning is a recent approach for distributed model training without sharing the raw data of clients. It allows model training using the large amount of user data collected by edge and mobile devices, while preserving data privacy. A challenge in federated learning is that the devices usually have much lower computational power and communication bandwidth than machines in data centers. Training large-sized deep neural networks in such a federated setting can consume a large amount of time and resources. To overcome this challenge, we propose a method that integrates model pruning with federated learning in this paper, which includes initial model pruning at the server, further model pruning as part of the federated learning process, followed by the regular federated learning procedure. Our proposed approach can save the computation, communication, and storage costs compared to standard federated learning approaches. Extensive experiments on real edge devices validate the benefit of our proposed method.