 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphusion: A RAG Framework for Knowledge Graph Construction with a Global Perspective
Oct 23, 2024



Knowledge Graphs (KGs) are crucial in the field of artificial intelligence and are widely used in downstream tasks, such as question-answering (QA). The construction of KGs typically requires significant effort from domain experts. Large Language Models (LLMs) have recently been used for Knowledge Graph Construction (KGC). However, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents, missing a fusion process to combine the knowledge in a global KG. This work introduces Graphusion, a zero-shot KGC framework from free text. It contains three steps: in Step 1, we extract a list of seed entities using topic modeling to guide the final KG includes the most relevant entities; in Step 2, we conduct candidate triplet extraction using LLMs; in Step 3, we design the novel fusion module that provides a global view of the extracted knowledge, incorporating entity merging, conflict resolution, and novel triplet discovery. Results show that Graphusion achieves scores of 2.92 and 2.37 out of 3 for entity extraction and relation recognition, respectively. Moreover, we showcase how Graphusion could be applied to the Natural Language Processing (NLP) domain and validate it in an educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for QA, comprising six tasks and a total of 1,200 QA pairs. Using the Graphusion-constructed KG, we achieve a significant improvement on the benchmark, for example, a 9.2% accuracy improvement on sub-graph completion.
Graphusion: Leveraging Large Language Models for Scientific Knowledge Graph Fusion and Construction in NLP Education
Jul 15, 2024



Knowledge graphs (KGs) are crucial in the field of artificial intelligence and are widely applied in downstream tasks, such as enhancing Question Answering (QA) systems. The construction of KGs typically requires significant effort from domain experts. Recently, Large Language Models (LLMs) have been used for knowledge graph construction (KGC), however, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents. In this work, we introduce Graphusion, a zero-shot KGC framework from free text. The core fusion module provides a global view of triplets, incorporating entity merging, conflict resolution, and novel triplet discovery. We showcase how Graphusion could be applied to the natural language processing (NLP) domain and validate it in the educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for graph reasoning and QA, comprising six tasks and a total of 1,200 QA pairs. Our evaluation demonstrates that Graphusion surpasses supervised baselines by up to 10% in accuracy on link prediction. Additionally, it achieves average scores of 2.92 and 2.37 out of 3 in human evaluations for concept entity extraction and relation recognition, respectively.
Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
Feb 22, 2024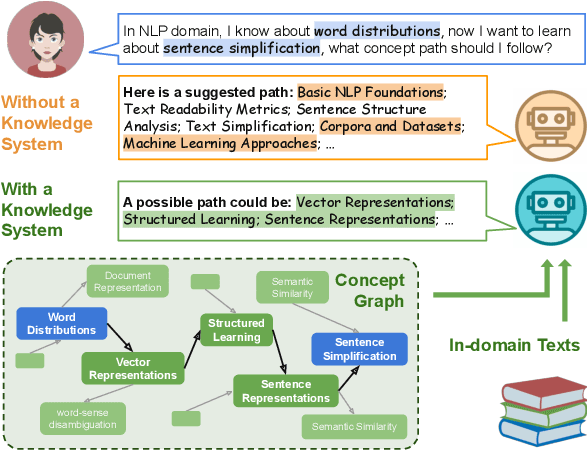
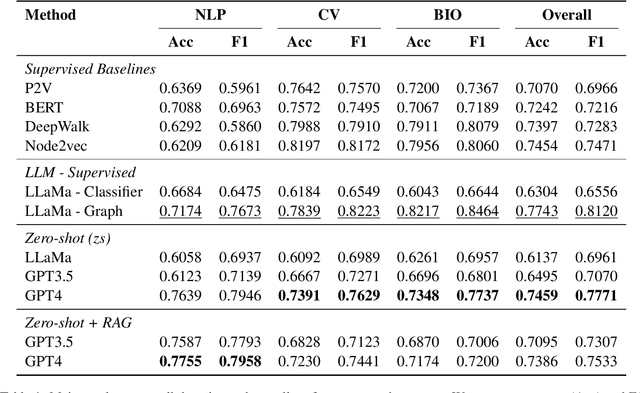
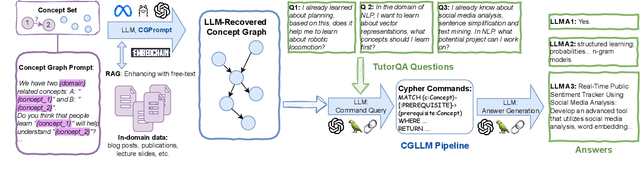

In the domain of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated promise in text-generation tasks. However, their educational applications, particularly for domain-specific queries, remain underexplored. This study investigates LLMs' capabilities in educational scenarios, focusing on concept graph recovery and question-answering (QA). We assess LLMs' zero-shot performance in creating domain-specific concept graphs and introduce TutorQA, a new expert-verified NLP-focused benchmark for scientific graph reasoning and QA. TutorQA consists of five tasks with 500 QA pairs. To tackle TutorQA queries, we present CGLLM, a pipeline integrating concept graphs with LLMs for answering diverse questions. Our results indicate that LLMs' zero-shot concept graph recovery is competitive with supervised methods, showing an average 3% F1 score improvement. In TutorQA tasks, LLMs achieve up to 26% F1 score enhancement. Moreover, human evaluation and analysis show that CGLLM generates answers with more fine-grained concepts.
Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model
Jun 19, 2019


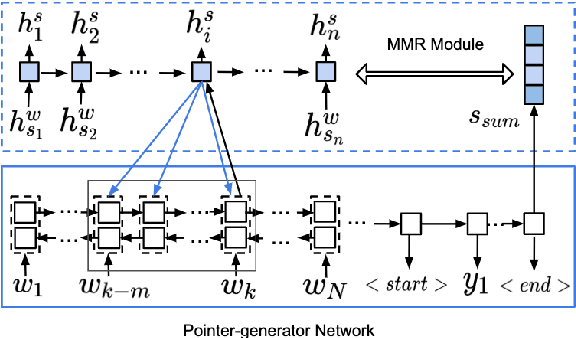
Automatic generation of summaries from multiple news articles is a valuable tool as the number of online publications grows rapidly. Single document summarization (SDS) systems have benefited from advances in neural encoder-decoder model thanks to the availability of large datasets. However, multi-document summarization (MDS) of news articles has been limited to datasets of a couple of hundred examples. In this paper, we introduce Multi-News, the first large-scale MDS news dataset. Additionally, we propose an end-to-end model which incorporates a traditional extractive summarization model with a standard SDS model and achieves competitive results on MDS datasets. We benchmark several methods on Multi-News and release our data and code in hope that this work will promote advances in summarization in the multi-document setting.