 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphusion: A RAG Framework for Knowledge Graph Construction with a Global Perspective
Oct 23, 2024



Knowledge Graphs (KGs) are crucial in the field of artificial intelligence and are widely used in downstream tasks, such as question-answering (QA). The construction of KGs typically requires significant effort from domain experts. Large Language Models (LLMs) have recently been used for Knowledge Graph Construction (KGC). However, most existing approaches focus on a local perspective, extracting knowledge triplets from individual sentences or documents, missing a fusion process to combine the knowledge in a global KG. This work introduces Graphusion, a zero-shot KGC framework from free text. It contains three steps: in Step 1, we extract a list of seed entities using topic modeling to guide the final KG includes the most relevant entities; in Step 2, we conduct candidate triplet extraction using LLMs; in Step 3, we design the novel fusion module that provides a global view of the extracted knowledge, incorporating entity merging, conflict resolution, and novel triplet discovery. Results show that Graphusion achieves scores of 2.92 and 2.37 out of 3 for entity extraction and relation recognition, respectively. Moreover, we showcase how Graphusion could be applied to the Natural Language Processing (NLP) domain and validate it in an educational scenario. Specifically, we introduce TutorQA, a new expert-verified benchmark for QA, comprising six tasks and a total of 1,200 QA pairs. Using the Graphusion-constructed KG, we achieve a significant improvement on the benchmark, for example, a 9.2% accuracy improvement on sub-graph completion.
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
Oct 15, 2024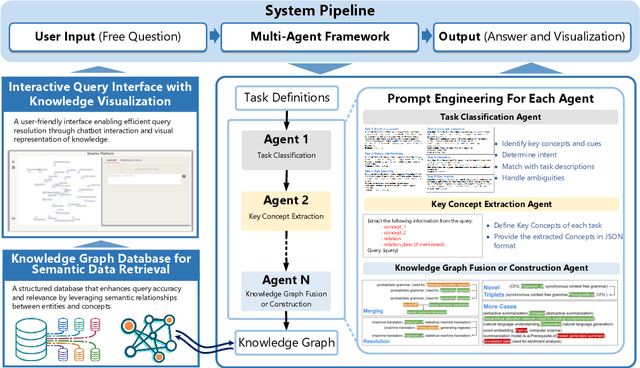
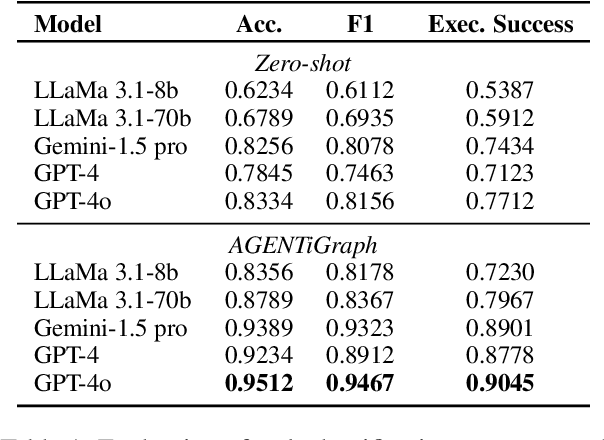
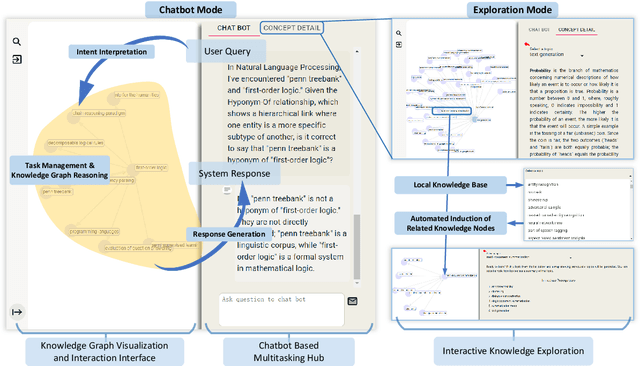
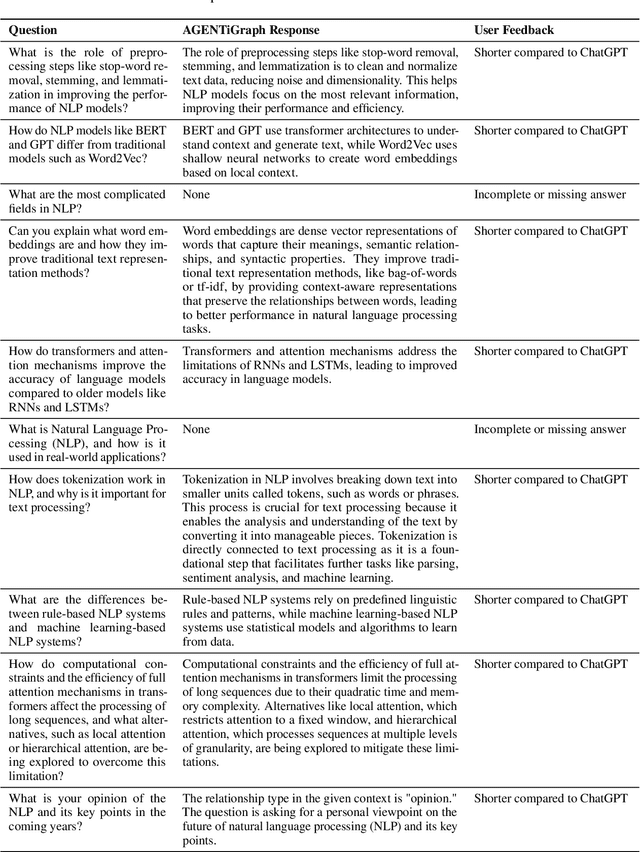
Large Language Models~(LLMs) have demonstrated capabilities across various applications but face challenges such as hallucination, limited reasoning abilities, and factual inconsistencies, especially when tackling complex, domain-specific tasks like question answering~(QA). While Knowledge Graphs~(KGs) have been shown to help mitigate these issues, research on the integration of LLMs with background KGs remains limited. In particular, user accessibility and the flexibility of the underlying KG have not been thoroughly explored. We introduce AGENTiGraph (Adaptive Generative ENgine for Task-based Interaction and Graphical Representation), a platform for knowledge management through natural language interaction. It integrates knowledge extraction, integration, and real-time visualization. AGENTiGraph employs a multi-agent architecture to dynamically interpret user intents, manage tasks, and integrate new knowledge, ensuring adaptability to evolving user requirements and data contexts. Our approach demonstrates superior performance in knowledge graph interactions, particularly for complex domain-specific tasks. Experimental results on a dataset of 3,500 test cases show AGENTiGraph significantly outperforms state-of-the-art zero-shot baselines, achieving 95.12\% accuracy in task classification and 90.45\% success rate in task execution. User studies corroborate its effectiveness in real-world scenarios. To showcase versatility, we extended AGENTiGraph to legislation and healthcare domains, constructing specialized KGs capable of answering complex queries in legal and medical contexts.
Numerical Literals in Link Prediction: A Critical Examination of Models and Datasets
Jul 25, 2024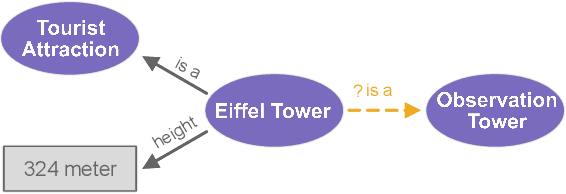
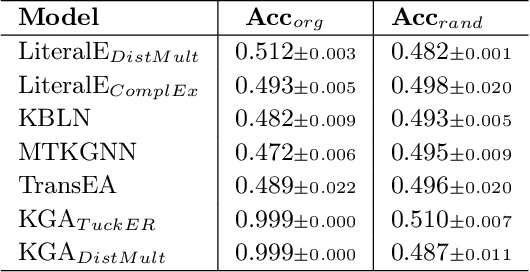
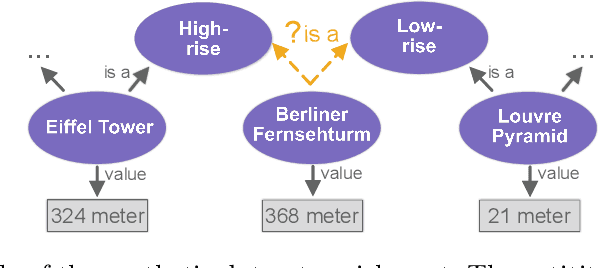
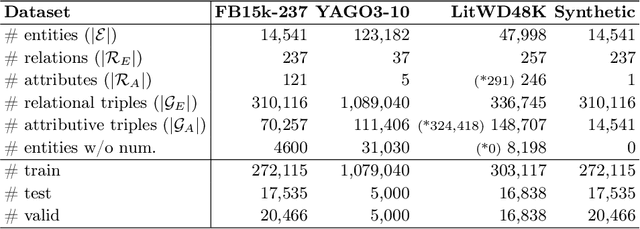
Link Prediction(LP) is an essential task over Knowledge Graphs(KGs), traditionally focussed on using and predicting the relations between entities. Textual entity descriptions have already been shown to be valuable, but models that incorporate numerical literals have shown minor improvements on existing benchmark datasets. It is unclear whether a model is actually better in using numerical literals, or better capable of utilizing the graph structure. This raises doubts about the effectiveness of these methods and about the suitability of the existing benchmark datasets. We propose a methodology to evaluate LP models that incorporate numerical literals. We propose i) a new synthetic dataset to better understand how well these models use numerical literals and ii) dataset ablations strategies to investigate potential difficulties with the existing datasets. We identify a prevalent trend: many models underutilize literal information and potentially rely on additional parameters for performance gains. Our investigation highlights the need for more extensive evaluations when releasing new models and datasets.
Pointing out the Shortcomings of Relation Extraction Models with Semantically Motivated Adversarials
Feb 29, 2024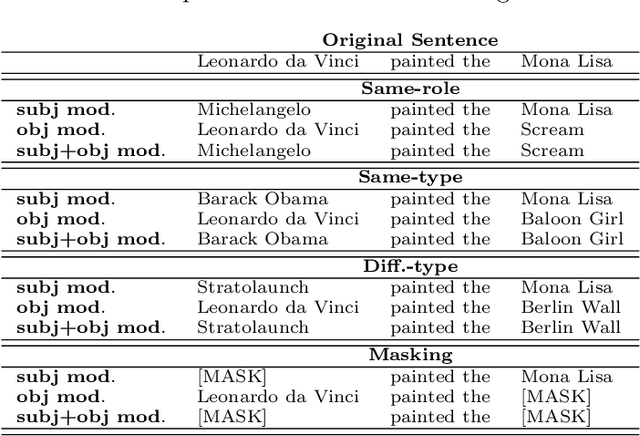

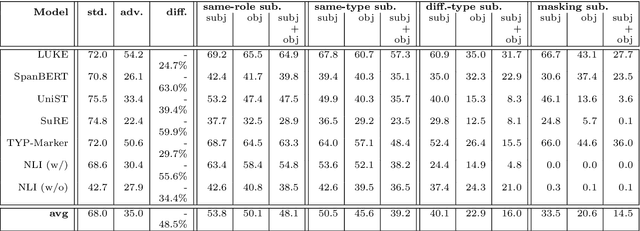
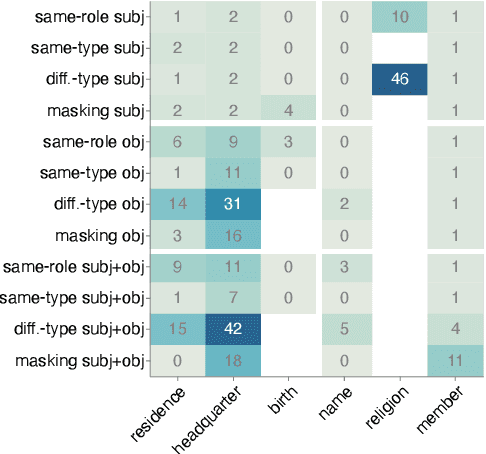
In recent years, large language models have achieved state-of-the-art performance across various NLP tasks. However, investigations have shown that these models tend to rely on shortcut features, leading to inaccurate predictions and causing the models to be unreliable at generalization to out-of-distribution (OOD) samples. For instance, in the context of relation extraction (RE), we would expect a model to identify the same relation independently of the entities involved in it. For example, consider the sentence "Leonardo da Vinci painted the Mona Lisa" expressing the created(Leonardo_da_Vinci, Mona_Lisa) relation. If we substiute "Leonardo da Vinci" with "Barack Obama", then the sentence still expresses the created relation. A robust model is supposed to detect the same relation in both cases. In this work, we describe several semantically-motivated strategies to generate adversarial examples by replacing entity mentions and investigate how state-of-the-art RE models perform under pressure. Our analyses show that the performance of these models significantly deteriorates on the modified datasets (avg. of -48.5% in F1), which indicates that these models rely to a great extent on shortcuts, such as surface forms (or patterns therein) of entities, without making full use of the information present in the sentences.
Insights from an OTTR-centric Ontology Engineering Methodology
Sep 22, 2023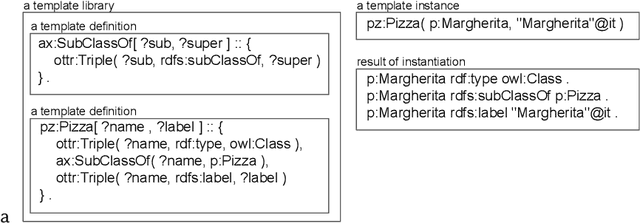
OTTR is a language for representing ontology modeling patterns, which enables to build ontologies or knowledge bases by instantiating templates. Thereby, particularities of the ontological representation language are hidden from the domain experts, and it enables ontology engineers to, to some extent, separate the processes of deciding about what information to model from deciding about how to model the information, e.g., which design patterns to use. Certain decisions can thus be postponed for the benefit of focusing on one of these processes. To date, only few works on ontology engineering where ontology templates are applied are described in the literature. In this paper, we outline our methodology and report findings from our ontology engineering activities in the domain of Material Science. In these activities, OTTR templates play a key role. Our ontology engineering process is bottom-up, as we begin modeling activities from existing data that is then, via templates, fed into a knowledge graph, and it is top-down, as we first focus on which data to model and postpone the decision of how to model the data. We find, among other things, that OTTR templates are especially useful as a means of communication with domain experts. Furthermore, we find that because OTTR templates encapsulate modeling decisions, the engineering process becomes flexible, meaning that design decisions can be changed at little cost.
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Sep 06, 2023Large Language Models (LLMs) have achieved significant success across various natural language processing (NLP) tasks, encompassing question-answering, summarization, and machine translation, among others. While LLMs excel in general tasks, their efficacy in domain-specific applications remains under exploration. Additionally, LLM-generated text sometimes exhibits issues like hallucination and disinformation. In this study, we assess LLMs' capability of producing concise survey articles within the computer science-NLP domain, focusing on 20 chosen topics. Automated evaluations indicate that GPT-4 outperforms GPT-3.5 when benchmarked against the ground truth. Furthermore, four human evaluators provide insights from six perspectives across four model configurations. Through case studies, we demonstrate that while GPT often yields commendable results, there are instances of shortcomings, such as incomplete information and the exhibition of lapses in factual accuracy.