 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Metrics for Counterfactual Explanations Align with User Perception?
Mar 16, 2026Explainability is widely regarded as essential for trustworthy artificial intelligence systems. However, the metrics commonly used to evaluate counterfactual explanations are algorithmic evaluation metrics that are rarely validated against human judgments of explanation quality. This raises the question of whether such metrics meaningfully reflect user perceptions. We address this question through an empirical study that directly compares algorithmic evaluation metrics with human judgments across three datasets. Participants rated counterfactual explanations along multiple dimensions of perceived quality, which we relate to a comprehensive set of standard counterfactual metrics. We analyze both individual relationships and the extent to which combinations of metrics can predict human assessments. Our results show that correlations between algorithmic metrics and human ratings are generally weak and strongly dataset-dependent. Moreover, increasing the number of metrics used in predictive models does not lead to reliable improvements, indicating structural limitations in how current metrics capture criteria relevant for humans. Overall, our findings suggest that widely used counterfactual evaluation metrics fail to reflect key aspects of explanation quality as perceived by users, underscoring the need for more human-centered approaches to evaluating explainable artificial intelligence.
Balancing Quality and Variation: Spam Filtering Distorts Data Label Distributions
Sep 10, 2025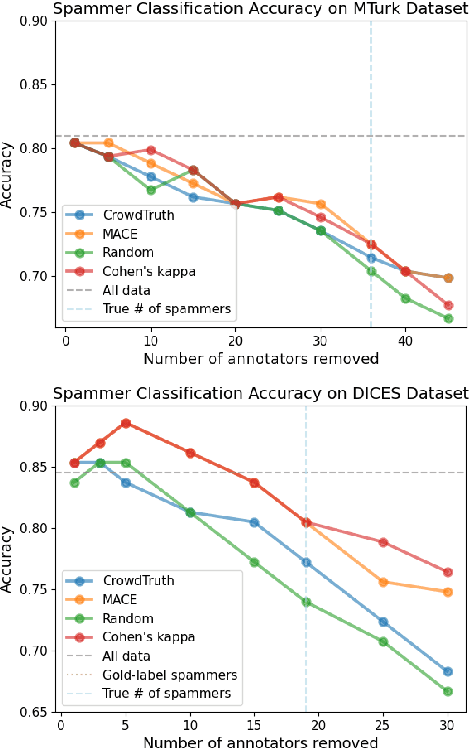
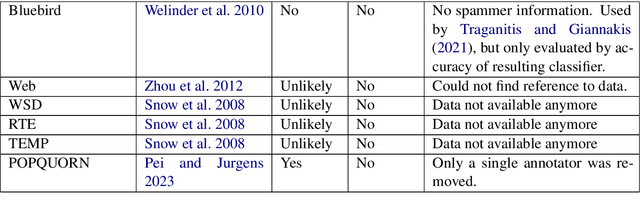
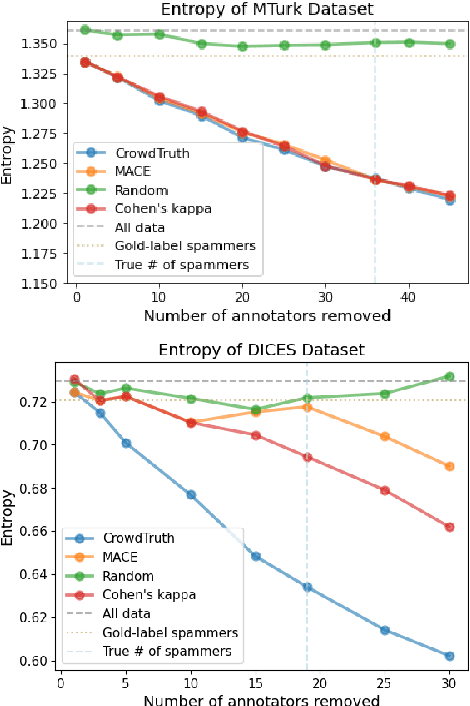
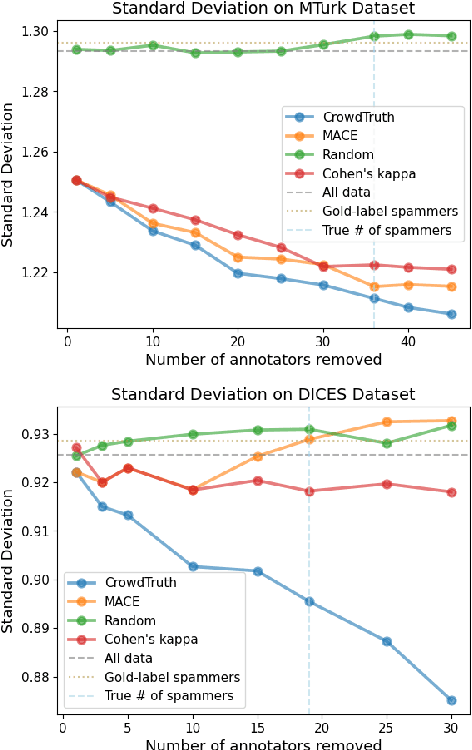
For machine learning datasets to accurately represent diverse opinions in a population, they must preserve variation in data labels while filtering out spam or low-quality responses. How can we balance annotator reliability and representation? We empirically evaluate how a range of heuristics for annotator filtering affect the preservation of variation on subjective tasks. We find that these methods, designed for contexts in which variation from a single ground-truth label is considered noise, often remove annotators who disagree instead of spam annotators, introducing suboptimal tradeoffs between accuracy and label diversity. We find that conservative settings for annotator removal (<5%) are best, after which all tested methods increase the mean absolute error from the true average label. We analyze performance on synthetic spam to observe that these methods often assume spam annotators are less random than real spammers tend to be: most spammers are distributionally indistinguishable from real annotators, and the minority that are distinguishable tend to give fixed answers, not random ones. Thus, tasks requiring the preservation of variation reverse the intuition of existing spam filtering methods: spammers tend to be less random than non-spammers, so metrics that assume variation is spam fare worse. These results highlight the need for spam removal methods that account for label diversity.
A User Study Evaluating Argumentative Explanations in Diagnostic Decision Support
May 15, 2025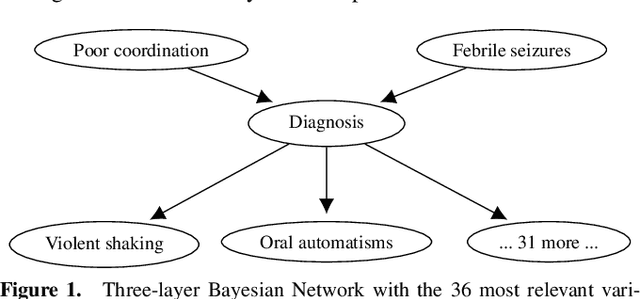



As the field of healthcare increasingly adopts artificial intelligence, it becomes important to understand which types of explanations increase transparency and empower users to develop confidence and trust in the predictions made by machine learning (ML) systems. In shared decision-making scenarios where doctors cooperate with ML systems to reach an appropriate decision, establishing mutual trust is crucial. In this paper, we explore different approaches to generating explanations in eXplainable AI (XAI) and make their underlying arguments explicit so that they can be evaluated by medical experts. In particular, we present the findings of a user study conducted with physicians to investigate their perceptions of various types of AI-generated explanations in the context of diagnostic decision support. The study aims to identify the most effective and useful explanations that enhance the diagnostic process. In the study, medical doctors filled out a survey to assess different types of explanations. Further, an interview was carried out post-survey to gain qualitative insights on the requirements of explanations incorporated in diagnostic decision support. Overall, the insights gained from this study contribute to understanding the types of explanations that are most effective.
A Factorized Probabilistic Model of the Semantics of Vague Temporal Adverbials Relative to Different Event Types
May 02, 2025Vague temporal adverbials, such as recently, just, and a long time ago, describe the temporal distance between a past event and the utterance time but leave the exact duration underspecified. In this paper, we introduce a factorized model that captures the semantics of these adverbials as probabilistic distributions. These distributions are composed with event-specific distributions to yield a contextualized meaning for an adverbial applied to a specific event. We fit the model's parameters using existing data capturing judgments of native speakers regarding the applicability of these vague temporal adverbials to events that took place a given time ago. Comparing our approach to a non-factorized model based on a single Gaussian distribution for each pair of event and temporal adverbial, we find that while both models have similar predictive power, our model is preferable in terms of Occam's razor, as it is simpler and has better extendability.
TRAVELER: A Benchmark for Evaluating Temporal Reasoning across Vague, Implicit and Explicit References
May 02, 2025Understanding and resolving temporal references is essential in Natural Language Understanding as we often refer to the past or future in daily communication. Although existing benchmarks address a system's ability to reason about and resolve temporal references, systematic evaluation of specific temporal references remains limited. Towards closing this gap, we introduce TRAVELER, a novel synthetic benchmark dataset that follows a Question Answering paradigm and consists of questions involving temporal references with the corresponding correct answers. TRAVELER assesses models' abilities to resolve explicit, implicit relative to speech time, and vague temporal references. Beyond investigating the performance of state-of-the-art LLMs depending on the type of temporal reference, our benchmark also allows evaluation of performance in relation to the length of the set of events. For the category of vague temporal references, ground-truth answers were established via human surveys on Prolific, following a procedure similar to the one from Kenneweg et al. To demonstrate the benchmark's applicability, we evaluate four state-of-the-art LLMs using a question-answering task encompassing 3,300 questions. Our findings show that while the benchmarked LLMs can answer questions over event sets with a handful of events and explicit temporal references successfully, performance clearly deteriorates with larger event set length and when temporal references get less explicit. Notably, the vague question category exhibits the lowest performance across all models. The benchmark is publicly available at: https://gitlab.ub.uni-bielefeld.de/s.kenneweg/TRAVELER
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
Feb 28, 2025People naturally vary in their annotations for subjective questions and some of this variation is thought to be due to the person's sociodemographic characteristics. LLMs have also been used to label data, but recent work has shown that models perform poorly when prompted with sociodemographic attributes, suggesting limited inherent sociodemographic knowledge. Here, we ask whether LLMs can be trained to be accurate sociodemographic models of annotator variation. Using a curated dataset of five tasks with standardized sociodemographics, we show that models do improve in sociodemographic prompting when trained but that this performance gain is largely due to models learning annotator-specific behaviour rather than sociodemographic patterns. Across all tasks, our results suggest that models learn little meaningful connection between sociodemographics and annotation, raising doubts about the current use of LLMs for simulating sociodemographic variation and behaviour.
Lexicalization Is All You Need: Examining the Impact of Lexical Knowledge in a Compositional QALD System
Nov 06, 2024In this paper, we examine the impact of lexicalization on Question Answering over Linked Data (QALD). It is well known that one of the key challenges in interpreting natural language questions with respect to SPARQL lies in bridging the lexical gap, that is mapping the words in the query to the correct vocabulary elements. We argue in this paper that lexicalization, that is explicit knowledge about the potential interpretations of a word with respect to the given vocabulary, significantly eases the task and increases the performance of QA systems. Towards this goal, we present a compositional QA system that can leverage explicit lexical knowledge in a compositional manner to infer the meaning of a question in terms of a SPARQL query. We show that such a system, given lexical knowledge, has a performance well beyond current QA systems, achieving up to a $35.8\%$ increase in the micro $F_1$ score compared to the best QA system on QALD-9. This shows the importance and potential of including explicit lexical knowledge. In contrast, we show that LLMs have limited abilities to exploit lexical knowledge, with only marginal improvements compared to a version without lexical knowledge. This shows that LLMs have no ability to compositionally interpret a question on the basis of the meaning of its parts, a key feature of compositional approaches. Taken together, our work shows new avenues for QALD research, emphasizing the importance of lexicalization and compositionality.
Measuring User Understanding in Dialogue-based XAI Systems
Aug 14, 2024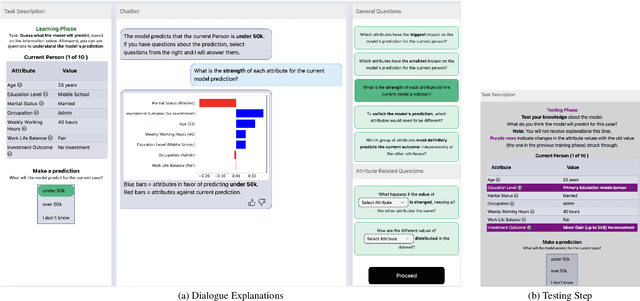
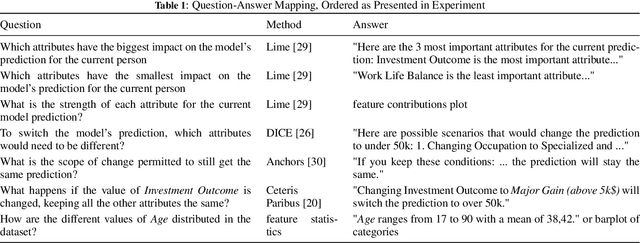
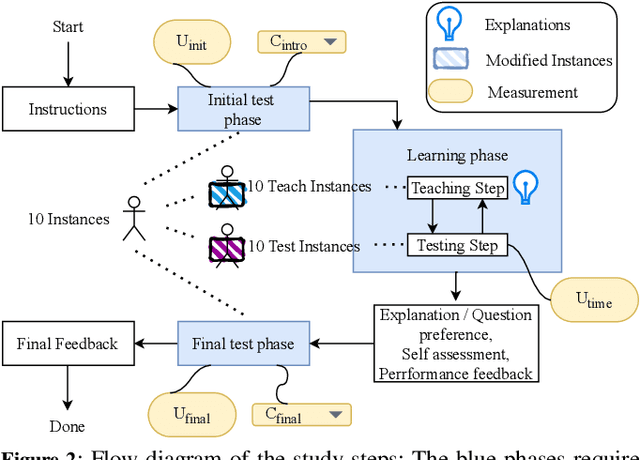
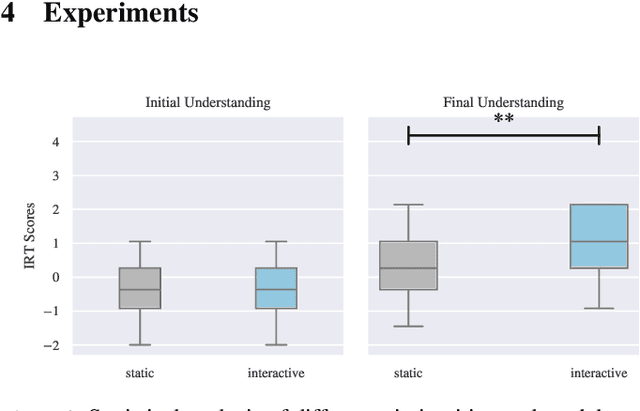
The field of eXplainable Artificial Intelligence (XAI) is increasingly recognizing the need to personalize and/or interactively adapt the explanation to better reflect users' explanation needs. While dialogue-based approaches to XAI have been proposed recently, the state-of-the-art in XAI is still characterized by what we call one-shot, non-personalized and one-way explanations. In contrast, dialogue-based systems that can adapt explanations through interaction with a user promise to be superior to GUI-based or dashboard explanations as they offer a more intuitive way of requesting information. In general, while interactive XAI systems are often evaluated in terms of user satisfaction, there are limited studies that access user's objective model understanding. This is in particular the case for dialogue-based XAI approaches. In this paper, we close this gap by carrying out controlled experiments within a dialogue framework in which we measure understanding of users in three phases by asking them to simulate the predictions of the model they are learning about. By this, we can quantify the level of (improved) understanding w.r.t. how the model works, comparing the state prior, and after the interaction. We further analyze the data to reveal patterns of how the interaction between groups with high vs. low understanding gain differ. Overall, our work thus contributes to our understanding about the effectiveness of XAI approaches.
Numerical Literals in Link Prediction: A Critical Examination of Models and Datasets
Jul 25, 2024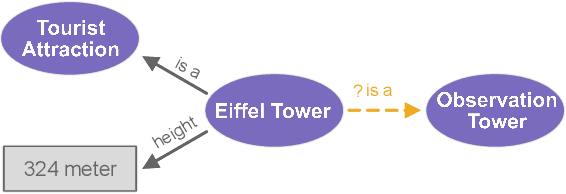
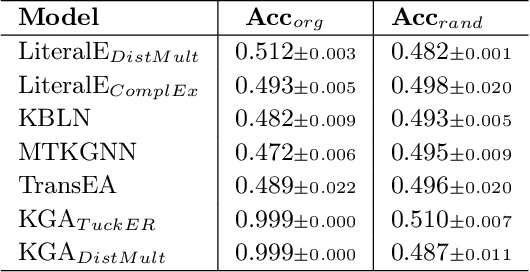
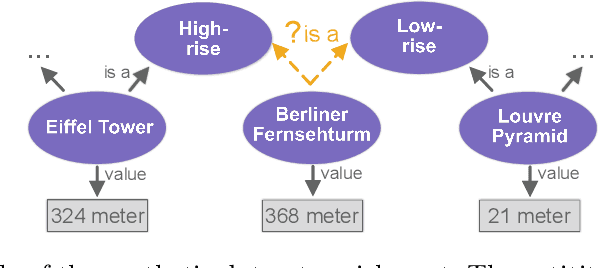
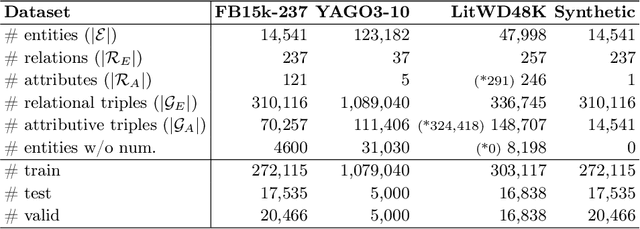
Link Prediction(LP) is an essential task over Knowledge Graphs(KGs), traditionally focussed on using and predicting the relations between entities. Textual entity descriptions have already been shown to be valuable, but models that incorporate numerical literals have shown minor improvements on existing benchmark datasets. It is unclear whether a model is actually better in using numerical literals, or better capable of utilizing the graph structure. This raises doubts about the effectiveness of these methods and about the suitability of the existing benchmark datasets. We propose a methodology to evaluate LP models that incorporate numerical literals. We propose i) a new synthetic dataset to better understand how well these models use numerical literals and ii) dataset ablations strategies to investigate potential difficulties with the existing datasets. We identify a prevalent trend: many models underutilize literal information and potentially rely on additional parameters for performance gains. Our investigation highlights the need for more extensive evaluations when releasing new models and datasets.
Modeling the Quality of Dialogical Explanations
Mar 01, 2024Explanations are pervasive in our lives. Mostly, they occur in dialogical form where an {\em explainer} discusses a concept or phenomenon of interest with an {\em explainee}. Leaving the explainee with a clear understanding is not straightforward due to the knowledge gap between the two participants. Previous research looked at the interaction of explanation moves, dialogue acts, and topics in successful dialogues with expert explainers. However, daily-life explanations often fail, raising the question of what makes a dialogue successful. In this work, we study explanation dialogues in terms of the interactions between the explainer and explainee and how they correlate with the quality of explanations in terms of a successful understanding on the explainee's side. In particular, we first construct a corpus of 399 dialogues from the Reddit forum {\em Explain Like I am Five} and annotate it for interaction flows and explanation quality. We then analyze the interaction flows, comparing them to those appearing in expert dialogues. Finally, we encode the interaction flows using two language models that can handle long inputs, and we provide empirical evidence for the effectiveness boost gained through the encoding in predicting the success of explanation dialogues.