 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Literals in Link Prediction: A Critical Examination of Models and Datasets
Paper and Code
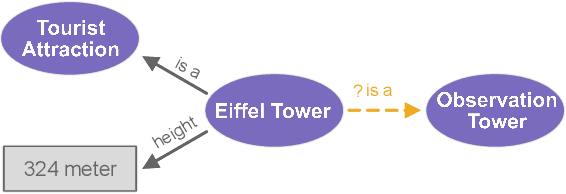
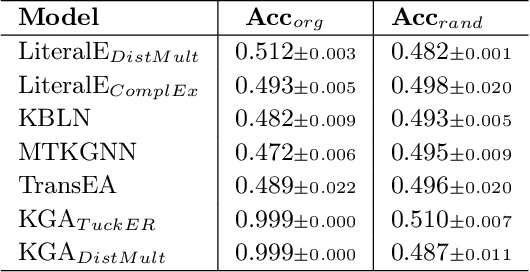
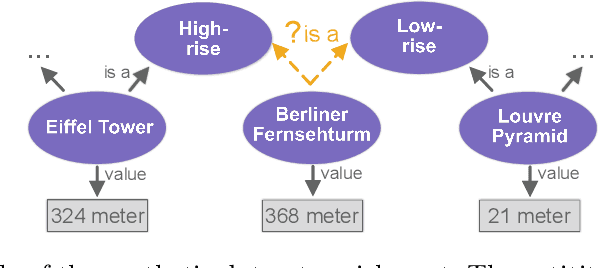
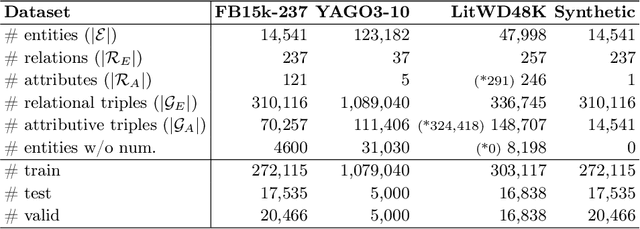
Link Prediction(LP) is an essential task over Knowledge Graphs(KGs), traditionally focussed on using and predicting the relations between entities. Textual entity descriptions have already been shown to be valuable, but models that incorporate numerical literals have shown minor improvements on existing benchmark datasets. It is unclear whether a model is actually better in using numerical literals, or better capable of utilizing the graph structure. This raises doubts about the effectiveness of these methods and about the suitability of the existing benchmark datasets. We propose a methodology to evaluate LP models that incorporate numerical literals. We propose i) a new synthetic dataset to better understand how well these models use numerical literals and ii) dataset ablations strategies to investigate potential difficulties with the existing datasets. We identify a prevalent trend: many models underutilize literal information and potentially rely on additional parameters for performance gains. Our investigation highlights the need for more extensive evaluations when releasing new models and datasets.