 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Metrics for Counterfactual Explanations Align with User Perception?
Mar 16, 2026Explainability is widely regarded as essential for trustworthy artificial intelligence systems. However, the metrics commonly used to evaluate counterfactual explanations are algorithmic evaluation metrics that are rarely validated against human judgments of explanation quality. This raises the question of whether such metrics meaningfully reflect user perceptions. We address this question through an empirical study that directly compares algorithmic evaluation metrics with human judgments across three datasets. Participants rated counterfactual explanations along multiple dimensions of perceived quality, which we relate to a comprehensive set of standard counterfactual metrics. We analyze both individual relationships and the extent to which combinations of metrics can predict human assessments. Our results show that correlations between algorithmic metrics and human ratings are generally weak and strongly dataset-dependent. Moreover, increasing the number of metrics used in predictive models does not lead to reliable improvements, indicating structural limitations in how current metrics capture criteria relevant for humans. Overall, our findings suggest that widely used counterfactual evaluation metrics fail to reflect key aspects of explanation quality as perceived by users, underscoring the need for more human-centered approaches to evaluating explainable artificial intelligence.
Graph Pattern-based Association Rules Evaluated Under No-repeated-anything Semantics in the Graph Transactional Setting
Dec 17, 2025We introduce graph pattern-based association rules (GPARs) for directed labeled multigraphs such as RDF graphs. GPARs support both generative tasks, where a graph is extended, and evaluative tasks, where the plausibility of a graph is assessed. The framework goes beyond related formalisms such as graph functional dependencies, graph entity dependencies, relational association rules, graph association rules, multi-relation and path association rules, and Horn rules. Given a collection of graphs, we evaluate graph patterns under no-repeated-anything semantics, which allows the topology of a graph to be taken into account more effectively. We define a probability space and derive confidence, lift, leverage, and conviction in a probabilistic setting. We further analyze how these metrics relate to their classical itemset-based counterparts and identify conditions under which their characteristic properties are preserved.
Numerical Literals in Link Prediction: A Critical Examination of Models and Datasets
Jul 25, 2024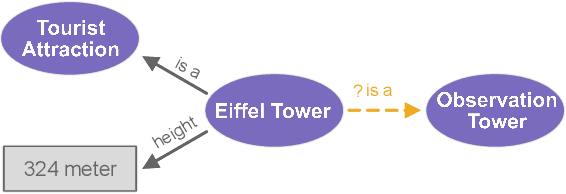
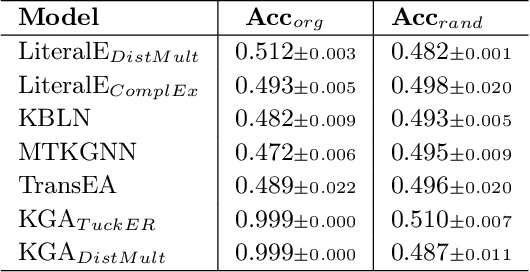
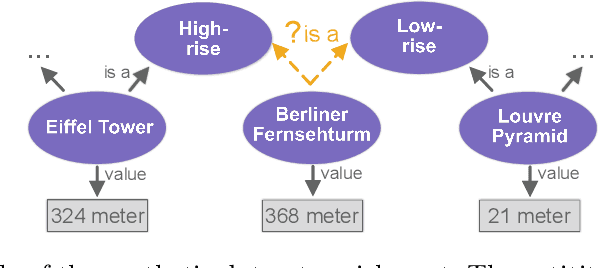
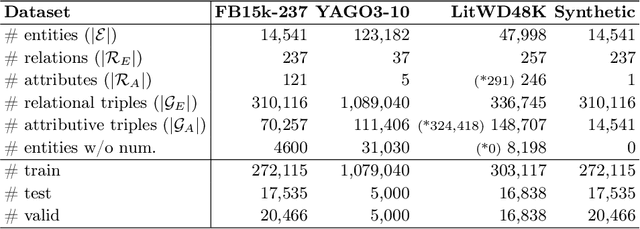
Link Prediction(LP) is an essential task over Knowledge Graphs(KGs), traditionally focussed on using and predicting the relations between entities. Textual entity descriptions have already been shown to be valuable, but models that incorporate numerical literals have shown minor improvements on existing benchmark datasets. It is unclear whether a model is actually better in using numerical literals, or better capable of utilizing the graph structure. This raises doubts about the effectiveness of these methods and about the suitability of the existing benchmark datasets. We propose a methodology to evaluate LP models that incorporate numerical literals. We propose i) a new synthetic dataset to better understand how well these models use numerical literals and ii) dataset ablations strategies to investigate potential difficulties with the existing datasets. We identify a prevalent trend: many models underutilize literal information and potentially rely on additional parameters for performance gains. Our investigation highlights the need for more extensive evaluations when releasing new models and datasets.
Pointing out the Shortcomings of Relation Extraction Models with Semantically Motivated Adversarials
Feb 29, 2024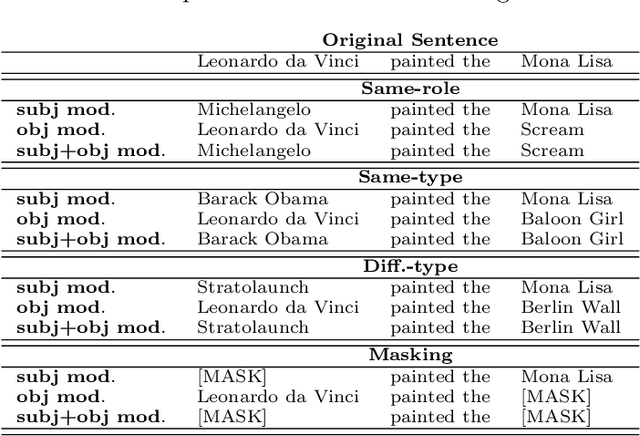

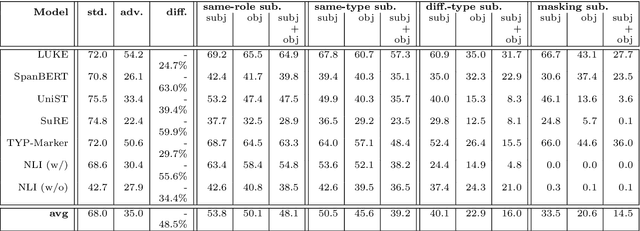
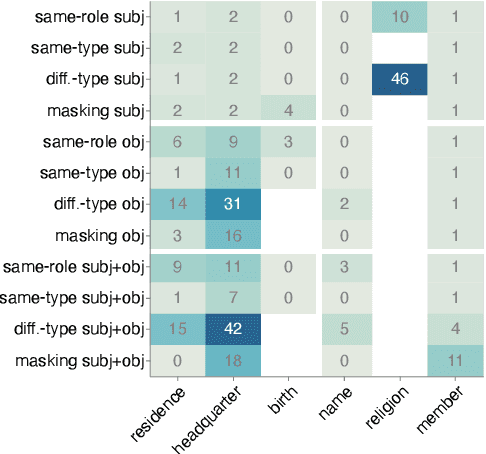
In recent years, large language models have achieved state-of-the-art performance across various NLP tasks. However, investigations have shown that these models tend to rely on shortcut features, leading to inaccurate predictions and causing the models to be unreliable at generalization to out-of-distribution (OOD) samples. For instance, in the context of relation extraction (RE), we would expect a model to identify the same relation independently of the entities involved in it. For example, consider the sentence "Leonardo da Vinci painted the Mona Lisa" expressing the created(Leonardo_da_Vinci, Mona_Lisa) relation. If we substiute "Leonardo da Vinci" with "Barack Obama", then the sentence still expresses the created relation. A robust model is supposed to detect the same relation in both cases. In this work, we describe several semantically-motivated strategies to generate adversarial examples by replacing entity mentions and investigate how state-of-the-art RE models perform under pressure. Our analyses show that the performance of these models significantly deteriorates on the modified datasets (avg. of -48.5% in F1), which indicates that these models rely to a great extent on shortcuts, such as surface forms (or patterns therein) of entities, without making full use of the information present in the sentences.
Insights from an OTTR-centric Ontology Engineering Methodology
Sep 22, 2023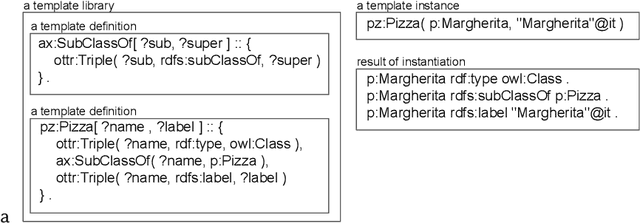
OTTR is a language for representing ontology modeling patterns, which enables to build ontologies or knowledge bases by instantiating templates. Thereby, particularities of the ontological representation language are hidden from the domain experts, and it enables ontology engineers to, to some extent, separate the processes of deciding about what information to model from deciding about how to model the information, e.g., which design patterns to use. Certain decisions can thus be postponed for the benefit of focusing on one of these processes. To date, only few works on ontology engineering where ontology templates are applied are described in the literature. In this paper, we outline our methodology and report findings from our ontology engineering activities in the domain of Material Science. In these activities, OTTR templates play a key role. Our ontology engineering process is bottom-up, as we begin modeling activities from existing data that is then, via templates, fed into a knowledge graph, and it is top-down, as we first focus on which data to model and postpone the decision of how to model the data. We find, among other things, that OTTR templates are especially useful as a means of communication with domain experts. Furthermore, we find that because OTTR templates encapsulate modeling decisions, the engineering process becomes flexible, meaning that design decisions can be changed at little cost.