 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
From Metaphor to Mechanism: How LLMs Decode Traditional Chinese Medicine Symbolic Language for Modern Clinical Relevance
Mar 04, 2025Metaphorical expressions are abundant in Traditional Chinese Medicine (TCM), conveying complex disease mechanisms and holistic health concepts through culturally rich and often abstract terminology. Bridging these metaphors to anatomically driven Western medical (WM) concepts poses significant challenges for both automated language processing and real-world clinical practice. To address this gap, we propose a novel multi-agent and chain-of-thought (CoT) framework designed to interpret TCM metaphors accurately and map them to WM pathophysiology. Specifically, our approach combines domain-specialized agents (TCM Expert, WM Expert) with a Coordinator Agent, leveraging stepwise chain-of-thought prompts to ensure transparent reasoning and conflict resolution. We detail a methodology for building a metaphor-rich TCM dataset, discuss strategies for effectively integrating multi-agent collaboration and CoT reasoning, and articulate the theoretical underpinnings that guide metaphor interpretation across distinct medical paradigms. We present a comprehensive system design and highlight both the potential benefits and limitations of our approach, while leaving placeholders for future experimental validation. Our work aims to support clinical decision-making, cross-system educational initiatives, and integrated healthcare research, ultimately offering a robust scaffold for reconciling TCM's symbolic language with the mechanistic focus of Western medicine.
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
Oct 15, 2024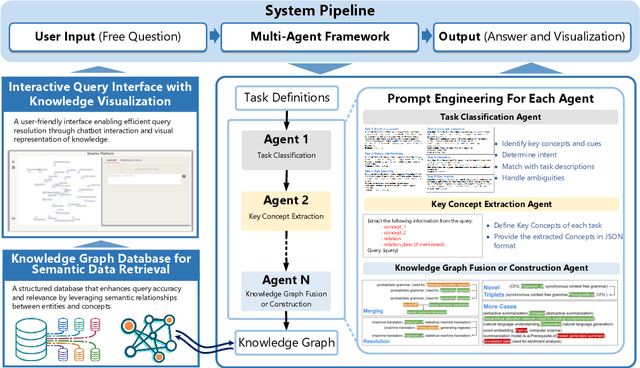
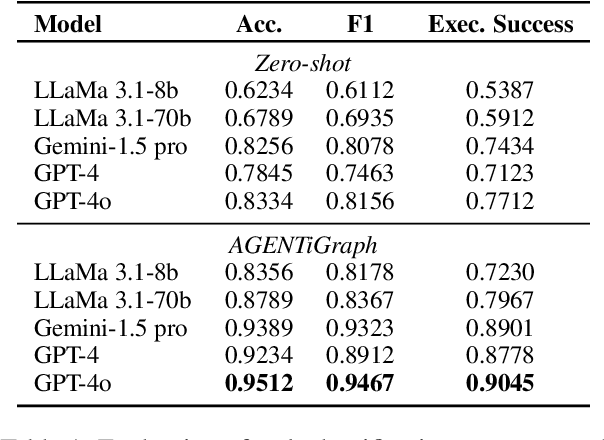
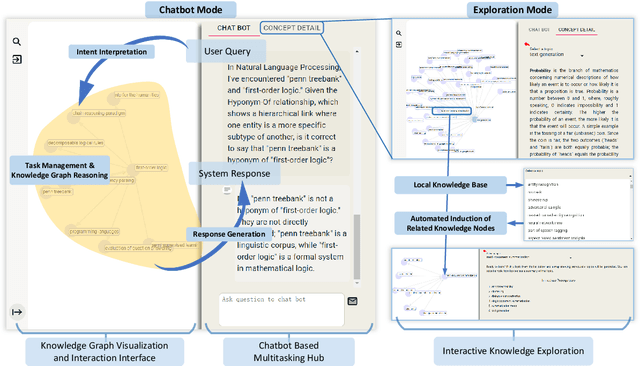
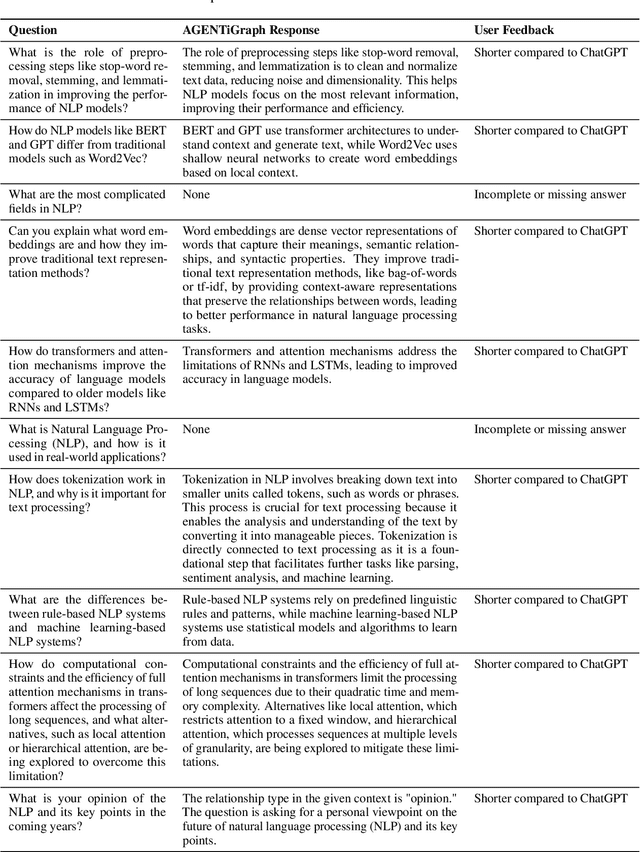
Large Language Models~(LLMs) have demonstrated capabilities across various applications but face challenges such as hallucination, limited reasoning abilities, and factual inconsistencies, especially when tackling complex, domain-specific tasks like question answering~(QA). While Knowledge Graphs~(KGs) have been shown to help mitigate these issues, research on the integration of LLMs with background KGs remains limited. In particular, user accessibility and the flexibility of the underlying KG have not been thoroughly explored. We introduce AGENTiGraph (Adaptive Generative ENgine for Task-based Interaction and Graphical Representation), a platform for knowledge management through natural language interaction. It integrates knowledge extraction, integration, and real-time visualization. AGENTiGraph employs a multi-agent architecture to dynamically interpret user intents, manage tasks, and integrate new knowledge, ensuring adaptability to evolving user requirements and data contexts. Our approach demonstrates superior performance in knowledge graph interactions, particularly for complex domain-specific tasks. Experimental results on a dataset of 3,500 test cases show AGENTiGraph significantly outperforms state-of-the-art zero-shot baselines, achieving 95.12\% accuracy in task classification and 90.45\% success rate in task execution. User studies corroborate its effectiveness in real-world scenarios. To showcase versatility, we extended AGENTiGraph to legislation and healthcare domains, constructing specialized KGs capable of answering complex queries in legal and medical contexts.