 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitLLM: Collaborative Inference of LLMs for Model Placement and Throughput Optimization
Oct 14, 2024

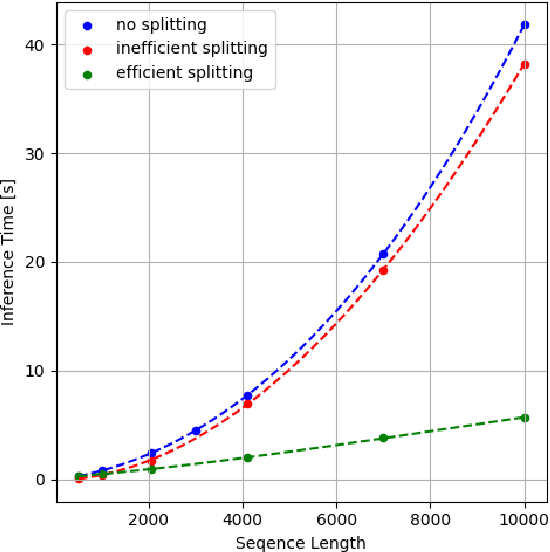
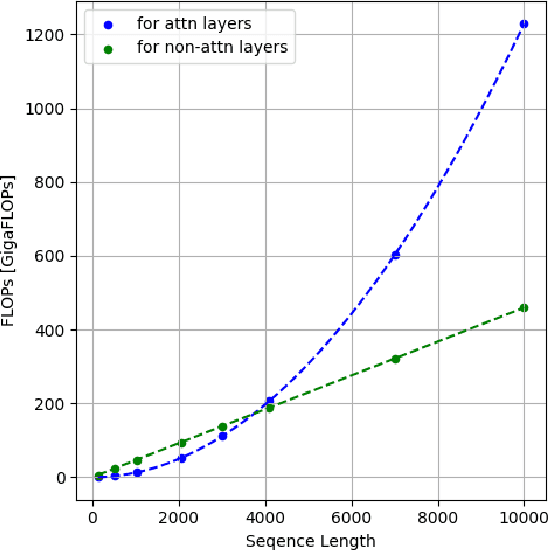
Large language models (LLMs) have been a disruptive innovation in recent years, and they play a crucial role in our daily lives due to their ability to understand and generate human-like text. Their capabilities include natural language understanding, information retrieval and search, translation, chatbots, virtual assistance, and many more. However, it is well known that LLMs are massive in terms of the number of parameters. Additionally, the self-attention mechanism in the underlying architecture of LLMs, Transformers, has quadratic complexity in terms of both computation and memory with respect to the input sequence length. For these reasons, LLM inference is resource-intensive, and thus, the throughput of LLM inference is limited, especially for the longer sequences. In this report, we design a collaborative inference architecture between a server and its clients to alleviate the throughput limit. In this design, we consider the available resources on both sides, i.e., the computation and communication costs. We develop a dynamic programming-based algorithm to optimally allocate computation between the server and the client device to increase the server throughput, while not violating the service level agreement (SLA). We show in the experiments that we are able to efficiently distribute the workload allowing for roughly 1/3 reduction in the server workload, while achieving 19 percent improvement over a greedy method. As a result, we are able to demonstrate that, in an environment with different types of LLM inference requests, the throughput of the server is improved.
Predictive Handover Strategy in 6G and Beyond: A Deep and Transfer Learning Approach
Apr 11, 2024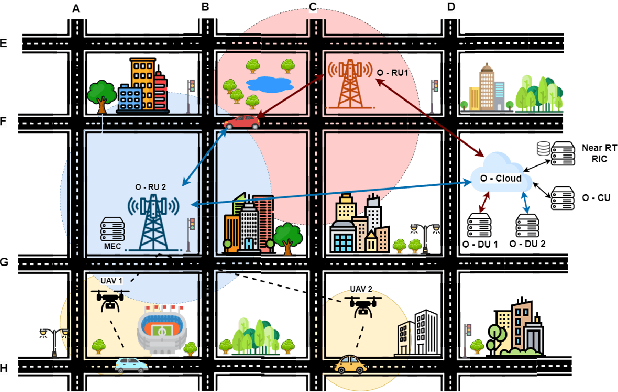
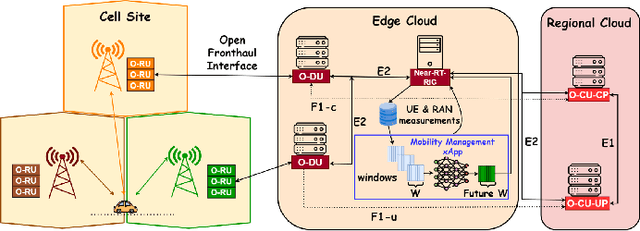
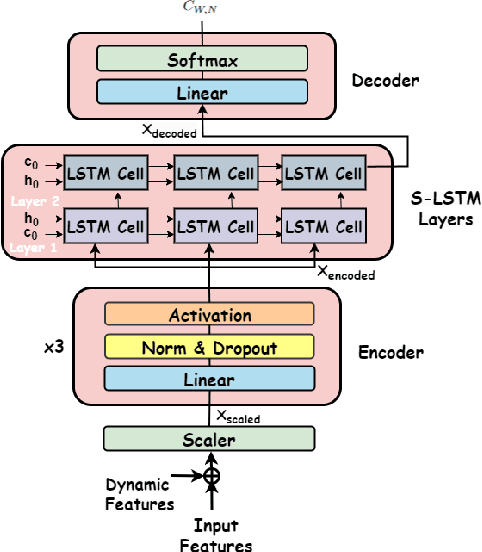

Next-generation cellular networks will evolve into more complex and virtualized systems, employing machine learning for enhanced optimization and leveraging higher frequency bands and denser deployments to meet varied service demands. This evolution, while bringing numerous advantages, will also pose challenges, especially in mobility management, as it will increase the overall number of handovers due to smaller coverage areas and the higher signal attenuation. To address these challenges, we propose a deep learning based algorithm for predicting the future serving cell utilizing sequential user equipment measurements to minimize the handover failures and interruption time. Our algorithm enables network operators to dynamically adjust handover triggering events or incorporate UAV base stations for enhanced coverage and capacity, optimizing network objectives like load balancing and energy efficiency through transfer learning techniques. Our framework complies with the O-RAN specifications and can be deployed in a Near-Real-Time RAN Intelligent Controller as an xApp leveraging the E2SM-KPM service model. The evaluation results demonstrate that our algorithm achieves a 92% accuracy in predicting future serving cells with high probability. Finally, by utilizing transfer learning, our algorithm significantly reduces the retraining time by 91% and 77% when new handover trigger decisions or UAV base stations are introduced to the network dynamically.
Deep Learning Architecture for Network-Efficiency at the Edge
Nov 09, 2023The growing number of AI-driven applications in the mobile devices has led to solutions that integrate deep learning models with the available edge-cloud resources; due to multiple benefits such as reduction in on-device energy consumption, improved latency, improved network usage, and certain privacy improvements, split learning, where deep learning models are split away from the mobile device and computed in a distributed manner, has become an extensively explored topic. Combined with compression-aware methods where learning adapts to compression of communicated data, the benefits of this approach have further improved and could serve as an alternative to established approaches like federated learning methods. In this work, we develop an adaptive compression-aware split learning method ('deprune') to improve and train deep learning models so that they are much more network-efficient (use less network resources and are faster), which would make them ideal to deploy in weaker devices with the help of edge-cloud resources. This method is also extended ('prune') to very quickly train deep learning models, through a transfer learning approach, that trades off little accuracy for much more network-efficient inference abilities. We show that the 'deprune' method can reduce network usage by 4x when compared with a split-learning approach (that does not use our method) without loss of accuracy, while also improving accuracy over compression-aware split-learning by 4 percent. Lastly, we show that the 'prune' method can reduce the training time for certain models by up to 6x without affecting the accuracy when compared against a compression-aware split-learning approach.