 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAD: A Clustered Label-Agnostic Federated Learning Framework for Joint Anomaly Detection and Attack Classification
May 07, 2026The rapid expansion of the Internet of Things (IoT) and Industrial IoT (IIoT) has created a massive, heterogeneous attack surface that challenges traditional network security mechanisms. While Federated Learning (FL) offers a privacy-preserving alternative to centralized Intrusion Detection Systems (IDS), standard approaches struggle to generalize across diverse device behaviors and typically fail to utilize the vast amounts of unlabeled data present in realistic edge environments. To bridge these gaps, we propose CLAD, a holistic framework that seamlessly incorporates Clustered Federated Learning (CFL) with a novel Dual-Mode Micro-Architecture ($\text{DM}^2\text{A}$). This unified approach simultaneously tackles the two primary bottlenecks of IoT security: device heterogeneity and label scarcity. The $\text{DM}^2\text{A}$ component features a shared encoder followed by two branches, enabling joint unsupervised anomaly detection and supervised attack classification; this allows the framework to harvest intelligence from both labeled and unlabeled clients. Concurrently, the clustering component dynamically groups devices with congruent traffic patterns, preventing global model divergence. By carefully combining these elements, CLAD ensures that no data is discarded and distinct operational patterns are preserved. Extensive evaluations demonstrate that this integrated approach significantly outperforms state-of-the-art baselines, achieving a 30% relative improvement in detection performance in scenarios with 80% unlabeled clients, with only half the communication cost.
Deep Learning Architecture for Network-Efficiency at the Edge
Nov 09, 2023The growing number of AI-driven applications in the mobile devices has led to solutions that integrate deep learning models with the available edge-cloud resources; due to multiple benefits such as reduction in on-device energy consumption, improved latency, improved network usage, and certain privacy improvements, split learning, where deep learning models are split away from the mobile device and computed in a distributed manner, has become an extensively explored topic. Combined with compression-aware methods where learning adapts to compression of communicated data, the benefits of this approach have further improved and could serve as an alternative to established approaches like federated learning methods. In this work, we develop an adaptive compression-aware split learning method ('deprune') to improve and train deep learning models so that they are much more network-efficient (use less network resources and are faster), which would make them ideal to deploy in weaker devices with the help of edge-cloud resources. This method is also extended ('prune') to very quickly train deep learning models, through a transfer learning approach, that trades off little accuracy for much more network-efficient inference abilities. We show that the 'deprune' method can reduce network usage by 4x when compared with a split-learning approach (that does not use our method) without loss of accuracy, while also improving accuracy over compression-aware split-learning by 4 percent. Lastly, we show that the 'prune' method can reduce the training time for certain models by up to 6x without affecting the accuracy when compared against a compression-aware split-learning approach.
An Overview of the Data-Loader Landscape: Comparative Performance Analysis
Sep 27, 2022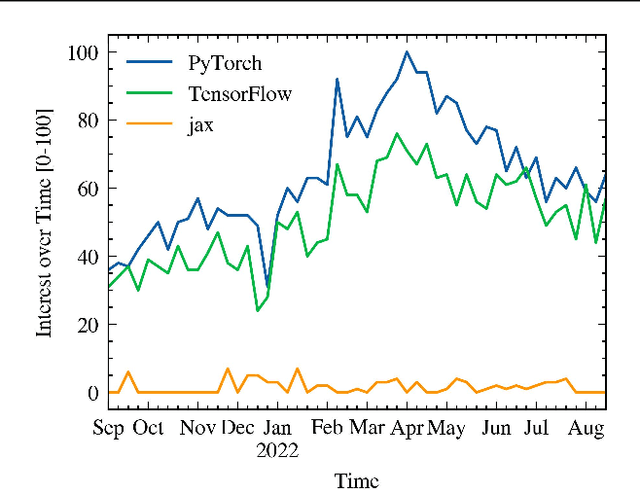
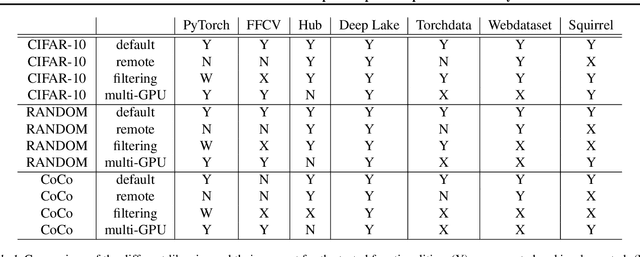
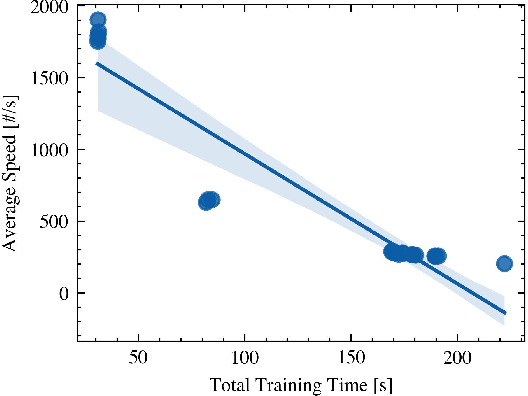
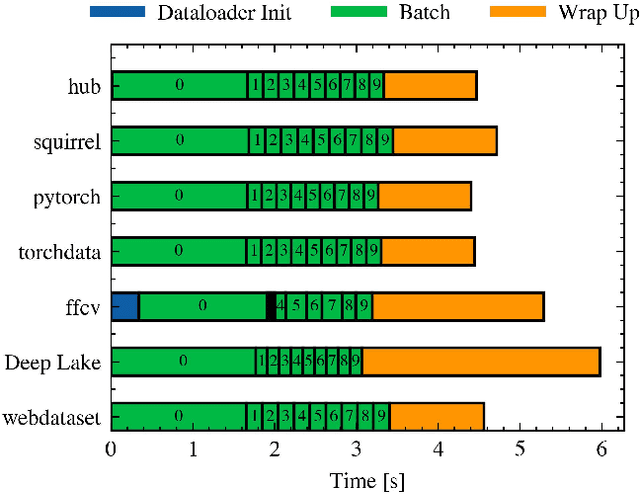
Dataloaders, in charge of moving data from storage into GPUs while training machine learning models, might hold the key to drastically improving the performance of training jobs. Recent advances have shown promise not only by considerably decreasing training time but also by offering new features such as loading data from remote storage like S3. In this paper, we are the first to distinguish the dataloader as a separate component in the Deep Learning (DL) workflow and to outline its structure and features. Finally, we offer a comprehensive comparison of the different dataloading libraries available, their trade-offs in terms of functionality, usability, and performance and the insights derived from them.