Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overview of the Data-Loader Landscape: Comparative Performance Analysis
Paper and Code
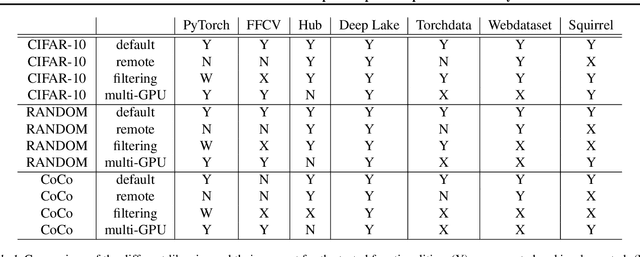
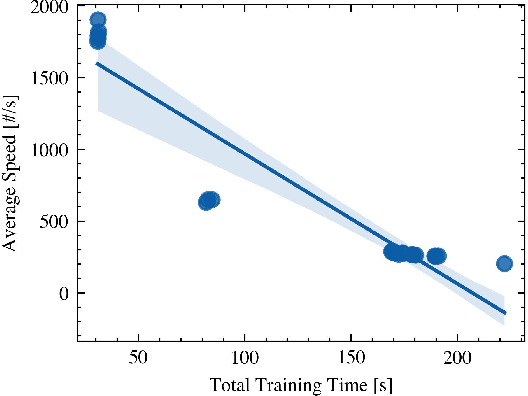
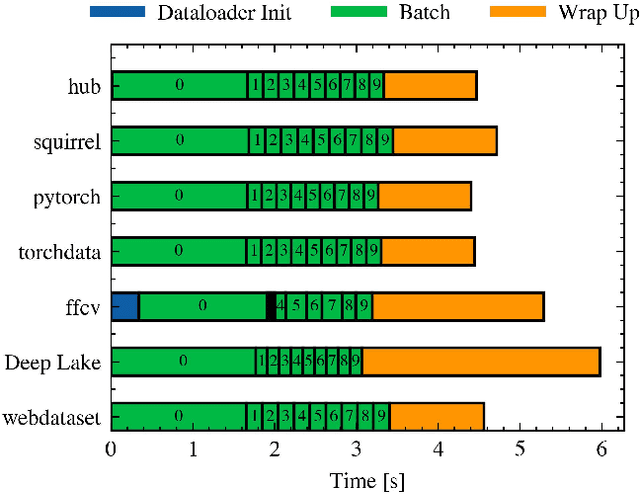
Dataloaders, in charge of moving data from storage into GPUs while training machine learning models, might hold the key to drastically improving the performance of training jobs. Recent advances have shown promise not only by considerably decreasing training time but also by offering new features such as loading data from remote storage like S3. In this paper, we are the first to distinguish the dataloader as a separate component in the Deep Learning (DL) workflow and to outline its structure and features. Finally, we offer a comprehensive comparison of the different dataloading libraries available, their trade-offs in terms of functionality, usability, and performance and the insights derived from them.
* 17 pages, 28 figures
View paper on