 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Delighting Prior for Facial Appearance Capture in the Wild
May 07, 2026High-quality facial appearance capture has traditionally required costly studio recording. Recent works consider an in-the-wild smartphone-based setup; however, their model-based inverse rendering paradigm struggles with the complex disentanglement of reflectance from unknown illumination. To bridge this gap, we propose to shift the paradigm into training a powerful delighting network as a prior to constrain the optimization. We leverage the OLAT dataset and the rendered Light Stage scans for training, and propose Dataset Latent Modulation (DLM) to seamlessly integrate these heterogeneous data sources. Specifically, by conditioning the core network on learnable source-aware tokens, we decouple dataset-specific styles from physical delighting principles, enabling the emergence of a delighting prior that outperforms existing proprietary models. This powerful delighting prior enables a simple and automatic appearance capture pipeline that achieves high-quality reflectance estimation from casual video inputs, outperforming prior arts by a large margin. Furthermore, we leverage our appearance capture method to transform the multi-view NeRSemble dataset into NeRSemble-Scan, a large-scale collection of 4K-resolution relightable scans. By open-sourcing our model and the NeRSemble-Scan dataset, we democratize high-end facial capture and provide a new foundation for the research community to build photorealistic digital humans.
WildCap: Facial Appearance Capture in the Wild via Hybrid Inverse Rendering
Dec 12, 2025Existing methods achieve high-quality facial appearance capture under controllable lighting, which increases capture cost and limits usability. We propose WildCap, a novel method for high-quality facial appearance capture from a smartphone video recorded in the wild. To disentangle high-quality reflectance from complex lighting effects in in-the-wild captures, we propose a novel hybrid inverse rendering framework. Specifically, we first apply a data-driven method, i.e., SwitchLight, to convert the captured images into more constrained conditions and then adopt model-based inverse rendering. However, unavoidable local artifacts in network predictions, such as shadow-baking, are non-physical and thus hinder accurate inverse rendering of lighting and material. To address this, we propose a novel texel grid lighting model to explain non-physical effects as clean albedo illuminated by local physical lighting. During optimization, we jointly sample a diffusion prior for reflectance maps and optimize the lighting, effectively resolving scale ambiguity between local lights and albedo. Our method achieves significantly better results than prior arts in the same capture setup, closing the quality gap between in-the-wild and controllable recordings by a large margin. Our code will be released \href{https://yxuhan.github.io/WildCap/index.html}{\textcolor{magenta}{here}}.
RAIDX: A Retrieval-Augmented Generation and GRPO Reinforcement Learning Framework for Explainable Deepfake Detection
Aug 06, 2025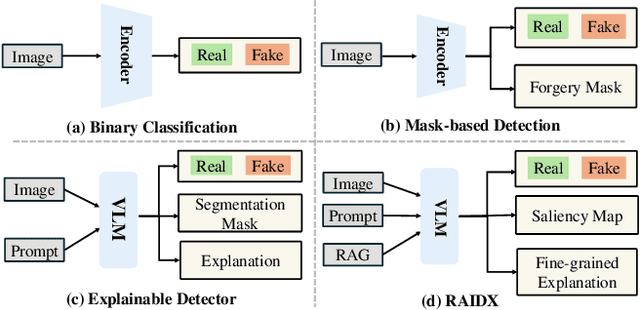
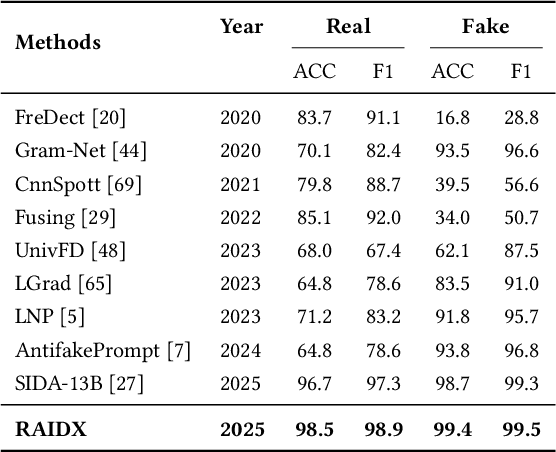
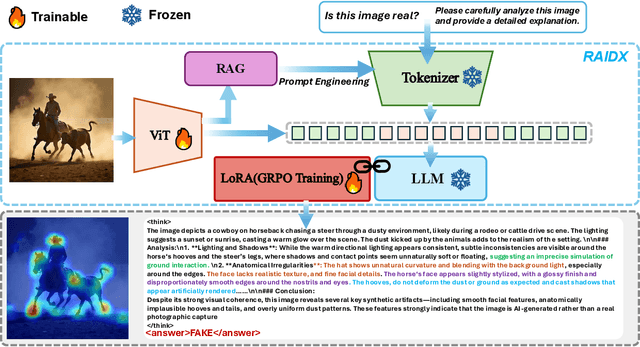
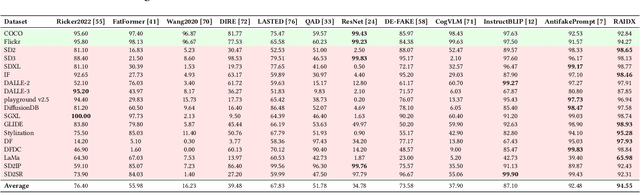
The rapid advancement of AI-generation models has enabled the creation of hyperrealistic imagery, posing ethical risks through widespread misinformation. Current deepfake detection methods, categorized as face specific detectors or general AI-generated detectors, lack transparency by framing detection as a classification task without explaining decisions. While several LLM-based approaches offer explainability, they suffer from coarse-grained analyses and dependency on labor-intensive annotations. This paper introduces RAIDX (Retrieval-Augmented Image Deepfake Detection and Explainability), a novel deepfake detection framework integrating Retrieval-Augmented Generation (RAG) and Group Relative Policy Optimization (GRPO) to enhance detection accuracy and decision explainability. Specifically, RAIDX leverages RAG to incorporate external knowledge for improved detection accuracy and employs GRPO to autonomously generate fine-grained textual explanations and saliency maps, eliminating the need for extensive manual annotations. Experiments on multiple benchmarks demonstrate RAIDX's effectiveness in identifying real or fake, and providing interpretable rationales in both textual descriptions and saliency maps, achieving state-of-the-art detection performance while advancing transparency in deepfake identification. RAIDX represents the first unified framework to synergize RAG and GRPO, addressing critical gaps in accuracy and explainability. Our code and models will be publicly available.
So-Fake: Benchmarking and Explaining Social Media Image Forgery Detection
May 24, 2025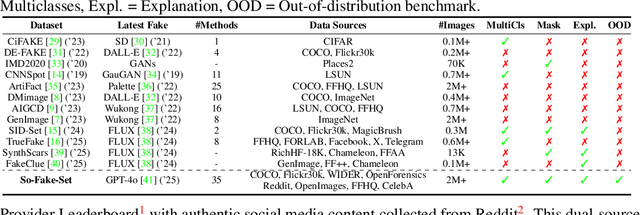
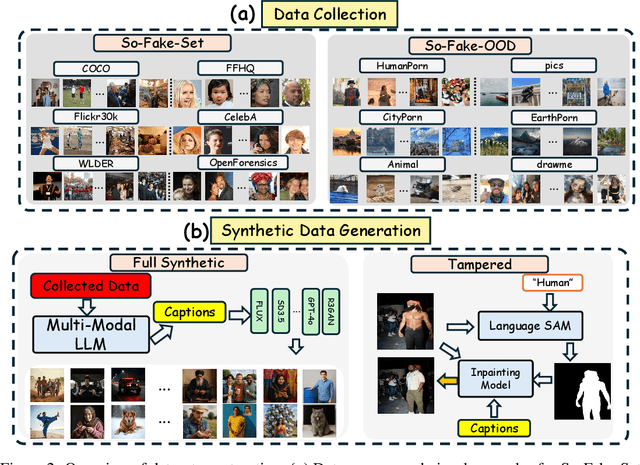
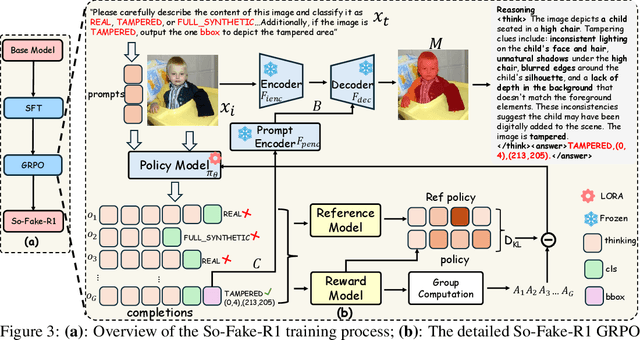
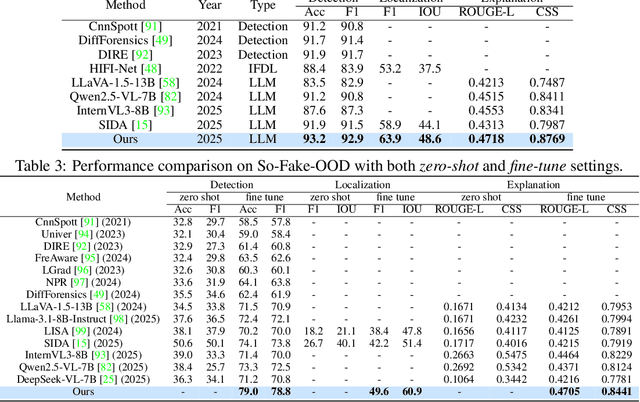
Recent advances in AI-powered generative models have enabled the creation of increasingly realistic synthetic images, posing significant risks to information integrity and public trust on social media platforms. While robust detection frameworks and diverse, large-scale datasets are essential to mitigate these risks, existing academic efforts remain limited in scope: current datasets lack the diversity, scale, and realism required for social media contexts, while detection methods struggle with generalization to unseen generative technologies. To bridge this gap, we introduce So-Fake-Set, a comprehensive social media-oriented dataset with over 2 million high-quality images, diverse generative sources, and photorealistic imagery synthesized using 35 state-of-the-art generative models. To rigorously evaluate cross-domain robustness, we establish a novel and large-scale (100K) out-of-domain benchmark (So-Fake-OOD) featuring synthetic imagery from commercial models explicitly excluded from the training distribution, creating a realistic testbed for evaluating real-world performance. Leveraging these resources, we present So-Fake-R1, an advanced vision-language framework that employs reinforcement learning for highly accurate forgery detection, precise localization, and explainable inference through interpretable visual rationales. Extensive experiments show that So-Fake-R1 outperforms the second-best method, with a 1.3% gain in detection accuracy and a 4.5% increase in localization IoU. By integrating a scalable dataset, a challenging OOD benchmark, and an advanced detection framework, this work establishes a new foundation for social media-centric forgery detection research. The code, models, and datasets will be released publicly.
BusterX: MLLM-Powered AI-Generated Video Forgery Detection and Explanation
May 19, 2025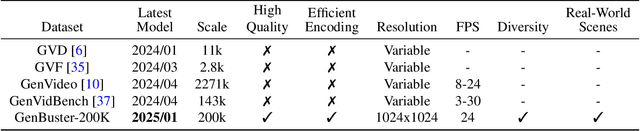
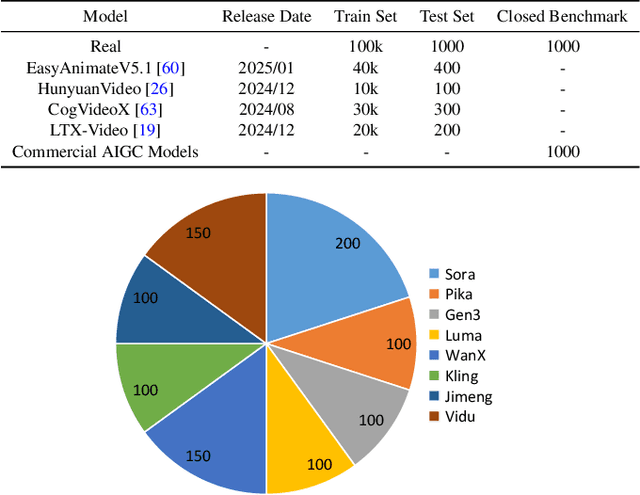
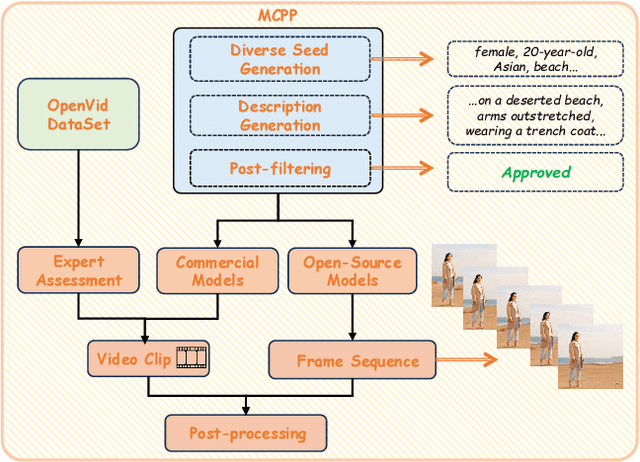
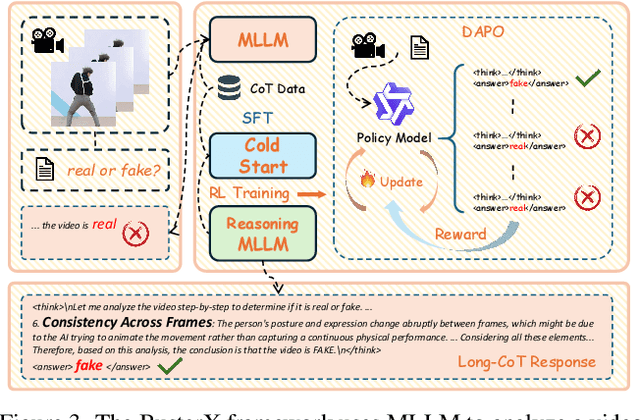
Advances in AI generative models facilitate super-realistic video synthesis, amplifying misinformation risks via social media and eroding trust in digital content. Several research works have explored new deepfake detection methods on AI-generated images to alleviate these risks. However, with the fast development of video generation models, such as Sora and WanX, there is currently a lack of large-scale, high-quality AI-generated video datasets for forgery detection. In addition, existing detection approaches predominantly treat the task as binary classification, lacking explainability in model decision-making and failing to provide actionable insights or guidance for the public. To address these challenges, we propose \textbf{GenBuster-200K}, a large-scale AI-generated video dataset featuring 200K high-resolution video clips, diverse latest generative techniques, and real-world scenes. We further introduce \textbf{BusterX}, a novel AI-generated video detection and explanation framework leveraging multimodal large language model (MLLM) and reinforcement learning for authenticity determination and explainable rationale. To our knowledge, GenBuster-200K is the {\it \textbf{first}} large-scale, high-quality AI-generated video dataset that incorporates the latest generative techniques for real-world scenarios. BusterX is the {\it \textbf{first}} framework to integrate MLLM with reinforcement learning for explainable AI-generated video detection. Extensive comparisons with state-of-the-art methods and ablation studies validate the effectiveness and generalizability of BusterX. The code, models, and datasets will be released.
Exploring the Role of Knowledge Graph-Based RAG in Japanese Medical Question Answering with Small-Scale LLMs
Apr 16, 2025Large language models (LLMs) perform well in medical QA, but their effectiveness in Japanese contexts is limited due to privacy constraints that prevent the use of commercial models like GPT-4 in clinical settings. As a result, recent efforts focus on instruction-tuning open-source LLMs, though the potential of combining them with retrieval-augmented generation (RAG) remains underexplored. To bridge this gap, we are the first to explore a knowledge graph-based (KG) RAG framework for Japanese medical QA small-scale open-source LLMs. Experimental results show that KG-based RAG has only a limited impact on Japanese medical QA using small-scale open-source LLMs. Further case studies reveal that the effectiveness of the RAG is sensitive to the quality and relevance of the external retrieved content. These findings offer valuable insights into the challenges and potential of applying RAG in Japanese medical QA, while also serving as a reference for other low-resource languages.
MKG-Rank: Enhancing Large Language Models with Knowledge Graph for Multilingual Medical Question Answering
Mar 21, 2025Large Language Models (LLMs) have shown remarkable progress in medical question answering (QA), yet their effectiveness remains predominantly limited to English due to imbalanced multilingual training data and scarce medical resources for low-resource languages. To address this critical language gap in medical QA, we propose Multilingual Knowledge Graph-based Retrieval Ranking (MKG-Rank), a knowledge graph-enhanced framework that enables English-centric LLMs to perform multilingual medical QA. Through a word-level translation mechanism, our framework efficiently integrates comprehensive English-centric medical knowledge graphs into LLM reasoning at a low cost, mitigating cross-lingual semantic distortion and achieving precise medical QA across language barriers. To enhance efficiency, we introduce caching and multi-angle ranking strategies to optimize the retrieval process, significantly reducing response times and prioritizing relevant medical knowledge. Extensive evaluations on multilingual medical QA benchmarks across Chinese, Japanese, Korean, and Swahili demonstrate that MKG-Rank consistently outperforms zero-shot LLMs, achieving maximum 35.03% increase in accuracy, while maintaining an average retrieval time of only 0.0009 seconds.
Learning Disentangled Equivariant Representation for Explicitly Controllable 3D Molecule Generation
Dec 19, 2024We consider the conditional generation of 3D drug-like molecules with \textit{explicit control} over molecular properties such as drug-like properties (e.g., Quantitative Estimate of Druglikeness or Synthetic Accessibility score) and effectively binding to specific protein sites. To tackle this problem, we propose an E(3)-equivariant Wasserstein autoencoder and factorize the latent space of our generative model into two disentangled aspects: molecular properties and the remaining structural context of 3D molecules. Our model ensures explicit control over these molecular attributes while maintaining equivariance of coordinate representation and invariance of data likelihood. Furthermore, we introduce a novel alignment-based coordinate loss to adapt equivariant networks for auto-regressive de-novo 3D molecule generation from scratch. Extensive experiments validate our model's effectiveness on property-guided and context-guided molecule generation, both for de-novo 3D molecule design and structure-based drug discovery against protein targets.
Exploring Foundation Models in Remote Sensing Image Change Detection: A Comprehensive Survey
Oct 10, 2024Change detection, as an important and widely applied technique in the field of remote sensing, aims to analyze changes in surface areas over time and has broad applications in areas such as environmental monitoring, urban development, and land use analysis.In recent years, deep learning, especially the development of foundation models, has provided more powerful solutions for feature extraction and data fusion, effectively addressing these complexities. This paper systematically reviews the latest advancements in the field of change detection, with a focus on the application of foundation models in remote sensing tasks.
A Survey of Generative AI for De Novo Drug Design: New Frontiers in Molecule and Protein Generation
Feb 13, 2024



Artificial intelligence (AI)-driven methods can vastly improve the historically costly drug design process, with various generative models already in widespread use. Generative models for de novo drug design, in particular, focus on the creation of novel biological compounds entirely from scratch, representing a promising future direction. Rapid development in the field, combined with the inherent complexity of the drug design process, creates a difficult landscape for new researchers to enter. In this survey, we organize de novo drug design into two overarching themes: small molecule and protein generation. Within each theme, we identify a variety of subtasks and applications, highlighting important datasets, benchmarks, and model architectures and comparing the performance of top models. We take a broad approach to AI-driven drug design, allowing for both micro-level comparisons of various methods within each subtask and macro-level observations across different fields. We discuss parallel challenges and approaches between the two applications and highlight future directions for AI-driven de novo drug design as a whole. An organized repository of all covered sources is available at https://github.com/gersteinlab/GenAI4Drug.