 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transfer Learning Pipeline for Educational Resource Discovery with Application in Leading Paragraph Generation
Jan 07, 2022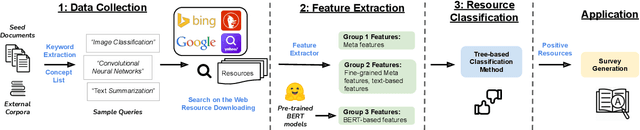

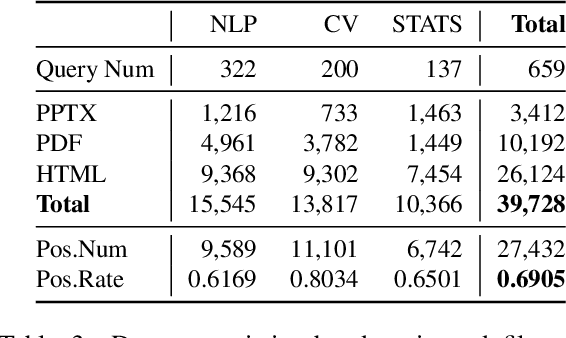

Effective human learning depends on a wide selection of educational materials that align with the learner's current understanding of the topic. While the Internet has revolutionized human learning or education, a substantial resource accessibility barrier still exists. Namely, the excess of online information can make it challenging to navigate and discover high-quality learning materials. In this paper, we propose the educational resource discovery (ERD) pipeline that automates web resource discovery for novel domains. The pipeline consists of three main steps: data collection, feature extraction, and resource classification. We start with a known source domain and conduct resource discovery on two unseen target domains via transfer learning. We first collect frequent queries from a set of seed documents and search on the web to obtain candidate resources, such as lecture slides and introductory blog posts. Then we introduce a novel pretrained information retrieval deep neural network model, query-document masked language modeling (QD-MLM), to extract deep features of these candidate resources. We apply a tree-based classifier to decide whether the candidate is a positive learning resource. The pipeline achieves F1 scores of 0.94 and 0.82 when evaluated on two similar but novel target domains. Finally, we demonstrate how this pipeline can benefit an application: leading paragraph generation for surveys. This is the first study that considers various web resources for survey generation, to the best of our knowledge. We also release a corpus of 39,728 manually labeled web resources and 659 queries from NLP, Computer Vision (CV), and Statistics (STATS).
CLICKER: A Computational LInguistics Classification Scheme for Educational Resources
Dec 16, 2021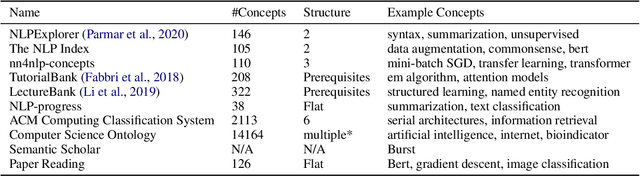
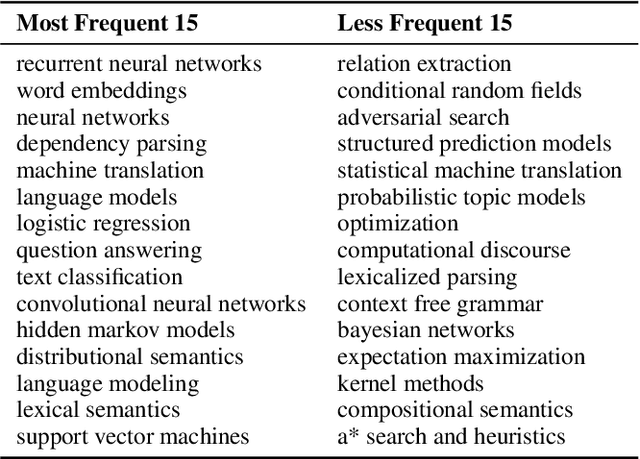
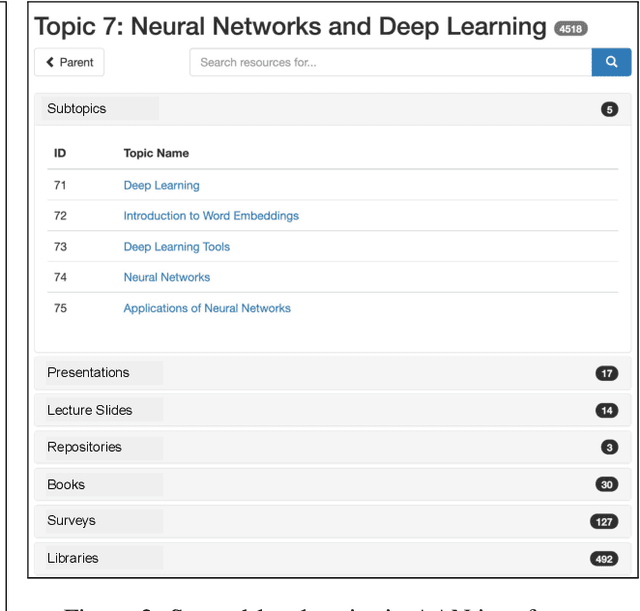
A classification scheme of a scientific subject gives an overview of its body of knowledge. It can also be used to facilitate access to research articles and other materials related to the subject. For example, the ACM Computing Classification System (CCS) is used in the ACM Digital Library search interface and also for indexing computer science papers. We observed that a comprehensive classification system like CCS or Mathematics Subject Classification (MSC) does not exist for Computational Linguistics (CL) and Natural Language Processing (NLP). We propose a classification scheme -- CLICKER for CL/NLP based on the analysis of online lectures from 77 university courses on this subject. The currently proposed taxonomy includes 334 topics and focuses on educational aspects of CL/NLP; it is based primarily, but not exclusively, on lecture notes from NLP courses. We discuss how such a taxonomy can help in various real-world applications, including tutoring platforms, resource retrieval, resource recommendation, prerequisite chain learning, and survey generation.
Efficient Variational Graph Autoencoders for Unsupervised Cross-domain Prerequisite Chains
Oct 06, 2021
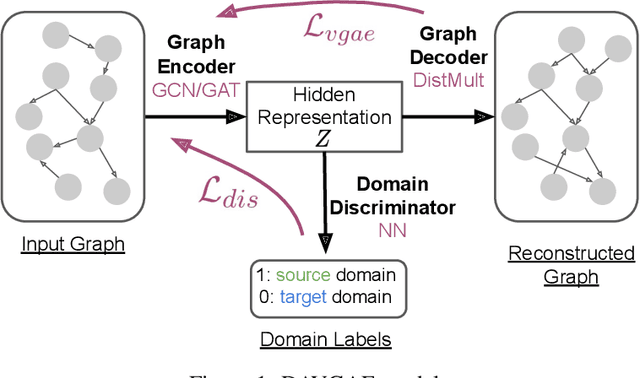
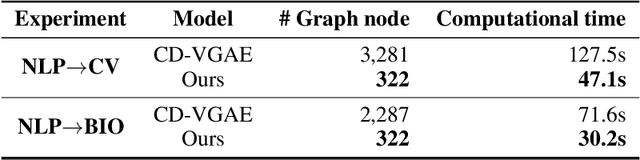
Prerequisite chain learning helps people acquire new knowledge efficiently. While people may quickly determine learning paths over concepts in a domain, finding such paths in other domains can be challenging. We introduce Domain-Adversarial Variational Graph Autoencoders (DAVGAE) to solve this cross-domain prerequisite chain learning task efficiently. Our novel model consists of a variational graph autoencoder (VGAE) and a domain discriminator. The VGAE is trained to predict concept relations through link prediction, while the domain discriminator takes both source and target domain data as input and is trained to predict domain labels. Most importantly, this method only needs simple homogeneous graphs as input, compared with the current state-of-the-art model. We evaluate our model on the LectureBankCD dataset, and results show that our model outperforms recent graph-based benchmarks while using only 1/10 of graph scale and 1/3 computation time.
Unsupervised Cross-Domain Prerequisite Chain Learning using Variational Graph Autoencoders
May 27, 2021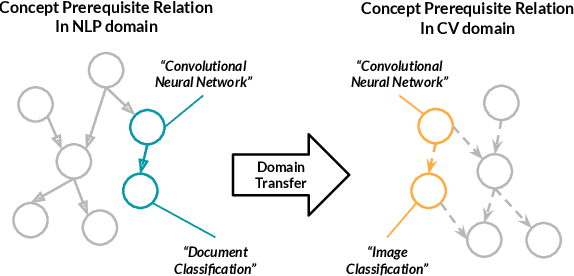

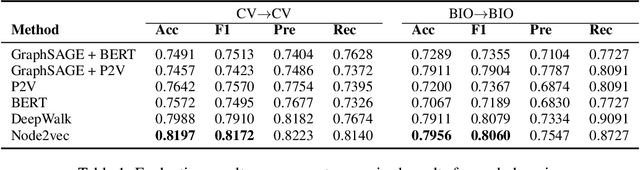
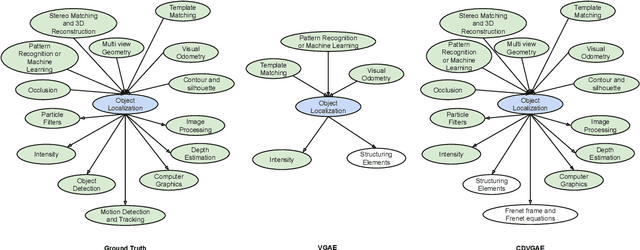
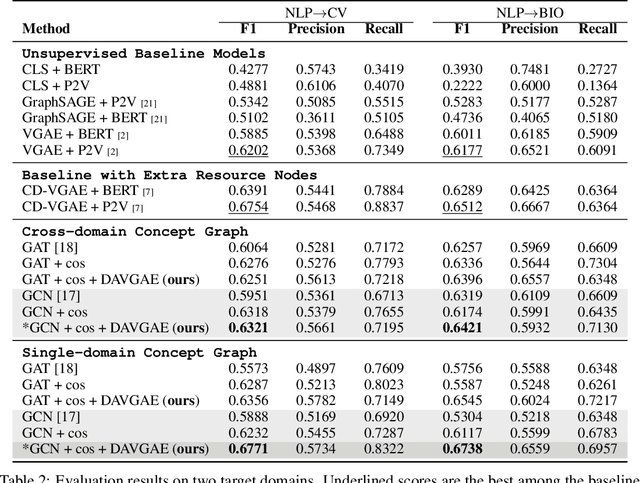
Learning prerequisite chains is an essential task for efficiently acquiring knowledge in both known and unknown domains. For example, one may be an expert in the natural language processing (NLP) domain but want to determine the best order to learn new concepts in an unfamiliar Computer Vision domain (CV). Both domains share some common concepts, such as machine learning basics and deep learning models. In this paper, we propose unsupervised cross-domain concept prerequisite chain learning using an optimized variational graph autoencoder. Our model learns to transfer concept prerequisite relations from an information-rich domain (source domain) to an information-poor domain (target domain), substantially surpassing other baseline models. Also, we expand an existing dataset by introducing two new domains: CV and Bioinformatics (BIO). The annotated data and resources, as well as the code, will be made publicly available.