 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiReRAG: Indexing Similar and Related Information for Multihop Reasoning
Dec 09, 2024



Indexing is an important step towards strong performance in retrieval-augmented generation (RAG) systems. However, existing methods organize data based on either semantic similarity (similarity) or related information (relatedness), but do not cover both perspectives comprehensively. Our analysis reveals that modeling only one perspective results in insufficient knowledge synthesis, leading to suboptimal performance on complex tasks requiring multihop reasoning. In this paper, we propose SiReRAG, a novel RAG indexing approach that explicitly considers both similar and related information. On the similarity side, we follow existing work and explore some variances to construct a similarity tree based on recursive summarization. On the relatedness side, SiReRAG extracts propositions and entities from texts, groups propositions via shared entities, and generates recursive summaries to construct a relatedness tree. We index and flatten both similarity and relatedness trees into a unified retrieval pool. Our experiments demonstrate that SiReRAG consistently outperforms state-of-the-art indexing methods on three multihop datasets (MuSiQue, 2WikiMultiHopQA, and HotpotQA), with an average 1.9% improvement in F1 scores. As a reasonably efficient solution, SiReRAG enhances existing reranking methods significantly, with up to 7.8% improvement in average F1 scores.
Fair Abstractive Summarization of Diverse Perspectives
Nov 14, 2023



People from different social and demographic groups express diverse perspectives and conflicting opinions on a broad set of topics such as product reviews, healthcare, law, and politics. A fair summary should provide a comprehensive coverage of diverse perspectives without underrepresenting certain groups. However, current work in summarization metrics and Large Language Models (LLMs) evaluation has not explored fair abstractive summarization. In this paper, we systematically investigate fair abstractive summarization for user-generated data. We first formally define fairness in abstractive summarization as not underrepresenting perspectives of any groups of people and propose four reference-free automatic metrics measuring the differences between target and source perspectives. We evaluate five LLMs, including three GPT models, Alpaca, and Claude, on six datasets collected from social media, online reviews, and recorded transcripts. Experiments show that both the model-generated and the human-written reference summaries suffer from low fairness. We conduct a comprehensive analysis of the common factors influencing fairness and propose three simple but effective methods to alleviate unfair summarization. Our dataset and code are available at https://github.com/psunlpgroup/FairSumm.
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Sep 08, 2023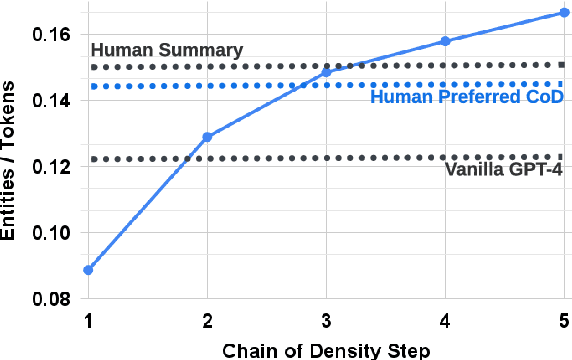



Selecting the ``right'' amount of information to include in a summary is a difficult task. A good summary should be detailed and entity-centric without being overly dense and hard to follow. To better understand this tradeoff, we solicit increasingly dense GPT-4 summaries with what we refer to as a ``Chain of Density'' (CoD) prompt. Specifically, GPT-4 generates an initial entity-sparse summary before iteratively incorporating missing salient entities without increasing the length. Summaries generated by CoD are more abstractive, exhibit more fusion, and have less of a lead bias than GPT-4 summaries generated by a vanilla prompt. We conduct a human preference study on 100 CNN DailyMail articles and find that that humans prefer GPT-4 summaries that are more dense than those generated by a vanilla prompt and almost as dense as human written summaries. Qualitative analysis supports the notion that there exists a tradeoff between informativeness and readability. 500 annotated CoD summaries, as well as an extra 5,000 unannotated summaries, are freely available on HuggingFace (https://huggingface.co/datasets/griffin/chain_of_density).
A Transfer Learning Pipeline for Educational Resource Discovery with Application in Leading Paragraph Generation
Jan 07, 2022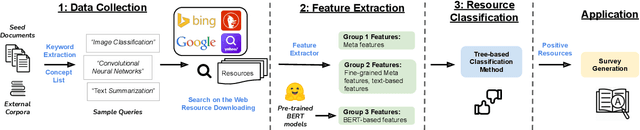

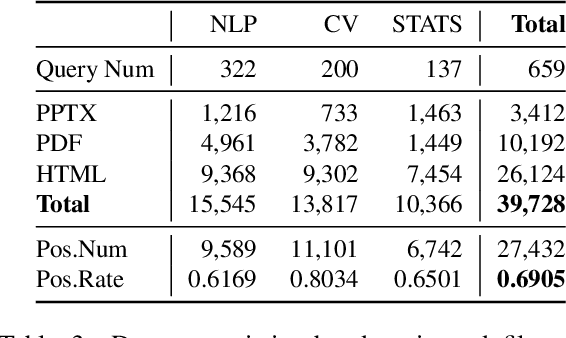

Effective human learning depends on a wide selection of educational materials that align with the learner's current understanding of the topic. While the Internet has revolutionized human learning or education, a substantial resource accessibility barrier still exists. Namely, the excess of online information can make it challenging to navigate and discover high-quality learning materials. In this paper, we propose the educational resource discovery (ERD) pipeline that automates web resource discovery for novel domains. The pipeline consists of three main steps: data collection, feature extraction, and resource classification. We start with a known source domain and conduct resource discovery on two unseen target domains via transfer learning. We first collect frequent queries from a set of seed documents and search on the web to obtain candidate resources, such as lecture slides and introductory blog posts. Then we introduce a novel pretrained information retrieval deep neural network model, query-document masked language modeling (QD-MLM), to extract deep features of these candidate resources. We apply a tree-based classifier to decide whether the candidate is a positive learning resource. The pipeline achieves F1 scores of 0.94 and 0.82 when evaluated on two similar but novel target domains. Finally, we demonstrate how this pipeline can benefit an application: leading paragraph generation for surveys. This is the first study that considers various web resources for survey generation, to the best of our knowledge. We also release a corpus of 39,728 manually labeled web resources and 659 queries from NLP, Computer Vision (CV), and Statistics (STATS).
CLICKER: A Computational LInguistics Classification Scheme for Educational Resources
Dec 16, 2021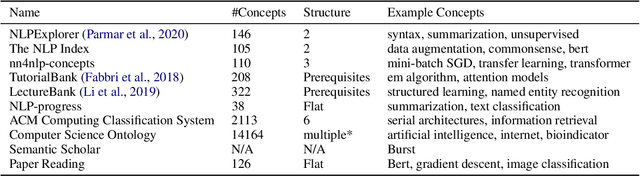
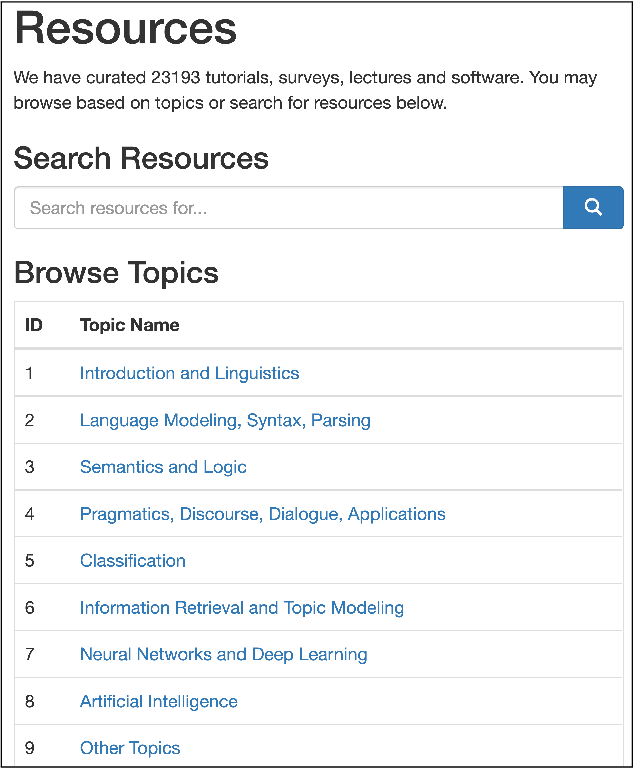
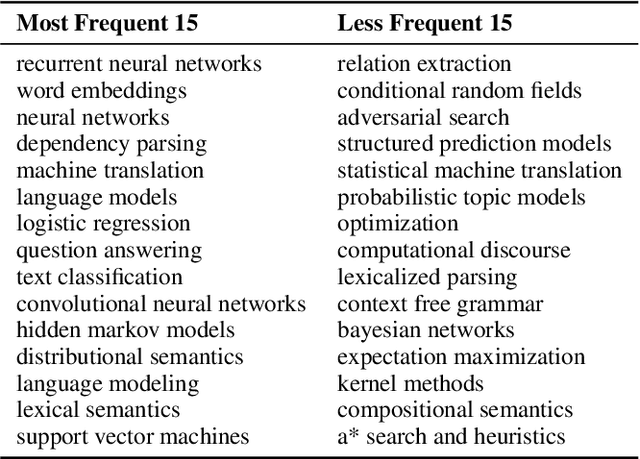
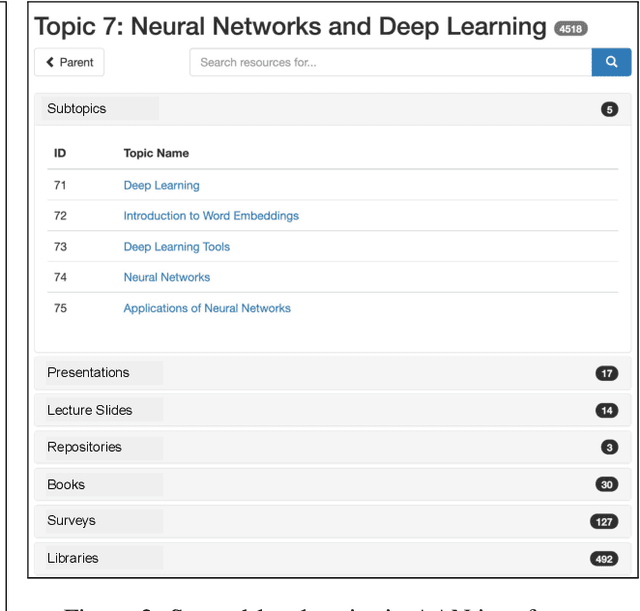
A classification scheme of a scientific subject gives an overview of its body of knowledge. It can also be used to facilitate access to research articles and other materials related to the subject. For example, the ACM Computing Classification System (CCS) is used in the ACM Digital Library search interface and also for indexing computer science papers. We observed that a comprehensive classification system like CCS or Mathematics Subject Classification (MSC) does not exist for Computational Linguistics (CL) and Natural Language Processing (NLP). We propose a classification scheme -- CLICKER for CL/NLP based on the analysis of online lectures from 77 university courses on this subject. The currently proposed taxonomy includes 334 topics and focuses on educational aspects of CL/NLP; it is based primarily, but not exclusively, on lecture notes from NLP courses. We discuss how such a taxonomy can help in various real-world applications, including tutoring platforms, resource retrieval, resource recommendation, prerequisite chain learning, and survey generation.
Surfer100: Generating Surveys From Web Resources on Wikipedia-style
Dec 13, 2021

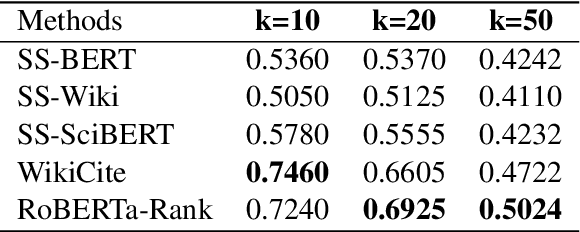
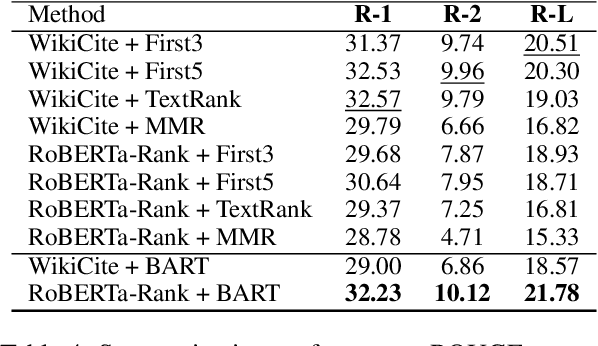
Fast-developing fields such as Artificial Intelligence (AI) often outpace the efforts of encyclopedic sources such as Wikipedia, which either do not completely cover recently-introduced topics or lack such content entirely. As a result, methods for automatically producing content are valuable tools to address this information overload. We show that recent advances in pretrained language modeling can be combined for a two-stage extractive and abstractive approach for Wikipedia lead paragraph generation. We extend this approach to generate longer Wikipedia-style summaries with sections and examine how such methods struggle in this application through detailed studies with 100 reference human-collected surveys. This is the first study on utilizing web resources for long Wikipedia-style summaries to the best of our knowledge.
R-VGAE: Relational-variational Graph Autoencoder for Unsupervised Prerequisite Chain Learning
Apr 22, 2020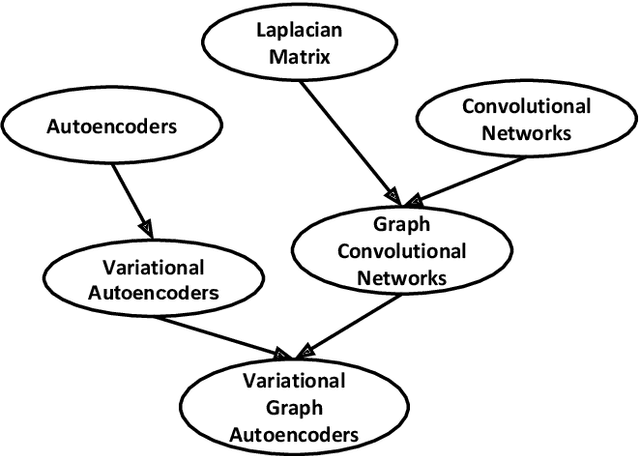
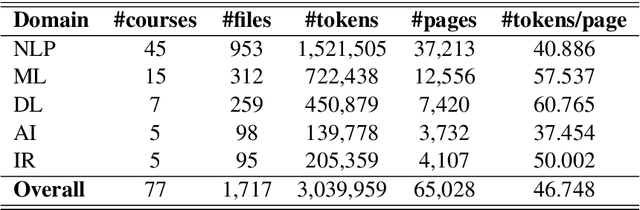
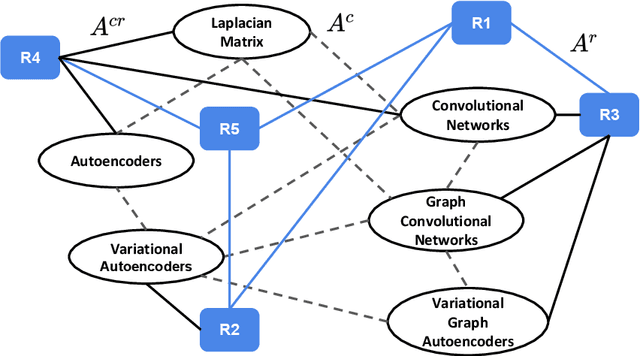
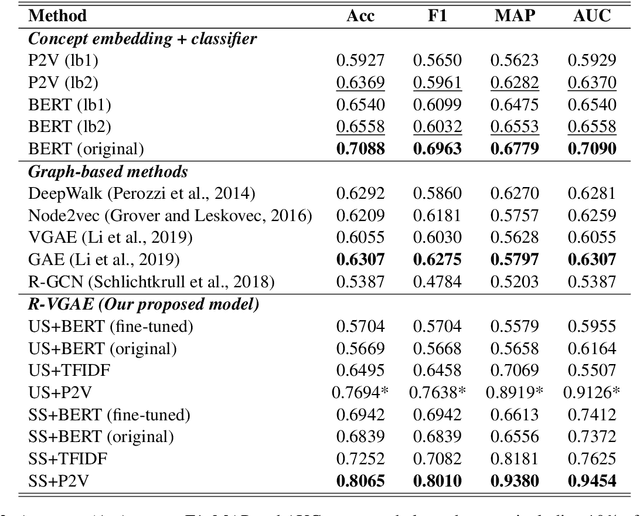
The task of concept prerequisite chain learning is to automatically determine the existence of prerequisite relationships among concept pairs. In this paper, we frame learning prerequisite relationships among concepts as an unsupervised task with no access to labeled concept pairs during training. We propose a model called the Relational-Variational Graph AutoEncoder (R-VGAE) to predict concept relations within a graph consisting of concept and resource nodes. Results show that our unsupervised approach outperforms graph-based semi-supervised methods and other baseline methods by up to 9.77% and 10.47% in terms of prerequisite relation prediction accuracy and F1 score. Our method is notably the first graph-based model that attempts to make use of deep learning representations for the task of unsupervised prerequisite learning. We also expand an existing corpus which totals 1,717 English Natural Language Processing (NLP)-related lecture slide files and manual concept pair annotations over 322 topics.
CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases
Sep 11, 2019
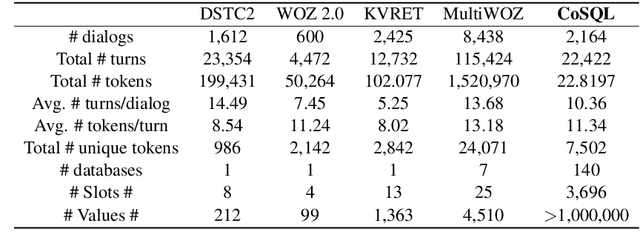
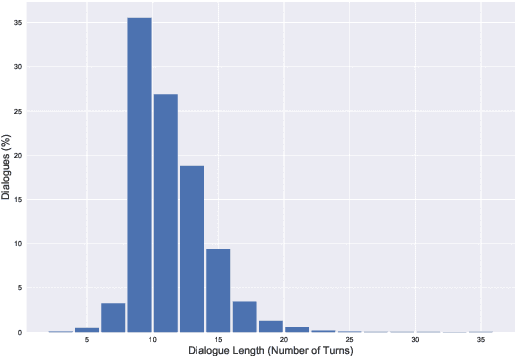
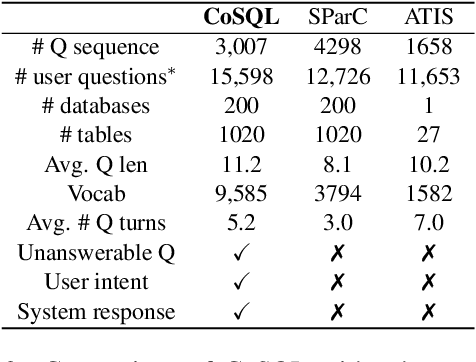
We present CoSQL, a corpus for building cross-domain, general-purpose database (DB) querying dialogue systems. It consists of 30k+ turns plus 10k+ annotated SQL queries, obtained from a Wizard-of-Oz (WOZ) collection of 3k dialogues querying 200 complex DBs spanning 138 domains. Each dialogue simulates a real-world DB query scenario with a crowd worker as a user exploring the DB and a SQL expert retrieving answers with SQL, clarifying ambiguous questions, or otherwise informing of unanswerable questions. When user questions are answerable by SQL, the expert describes the SQL and execution results to the user, hence maintaining a natural interaction flow. CoSQL introduces new challenges compared to existing task-oriented dialogue datasets:(1) the dialogue states are grounded in SQL, a domain-independent executable representation, instead of domain-specific slot-value pairs, and (2) because testing is done on unseen databases, success requires generalizing to new domains. CoSQL includes three tasks: SQL-grounded dialogue state tracking, response generation from query results, and user dialogue act prediction. We evaluate a set of strong baselines for each task and show that CoSQL presents significant challenges for future research. The dataset, baselines, and leaderboard will be released at https://yale-lily.github.io/cosql.
Improving Low-Resource Cross-lingual Document Retrieval by Reranking with Deep Bilingual Representations
Jun 08, 2019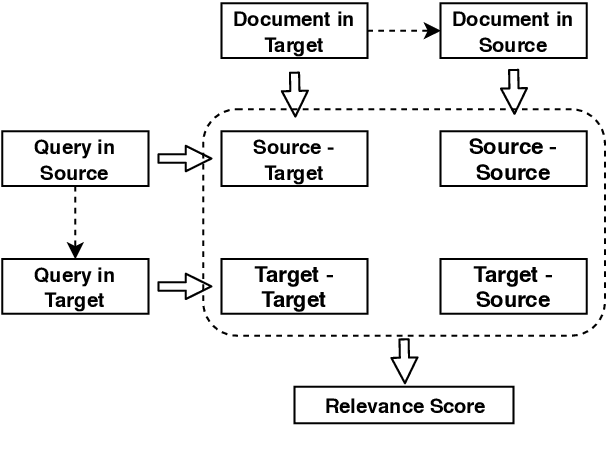
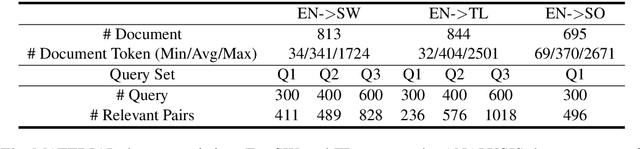

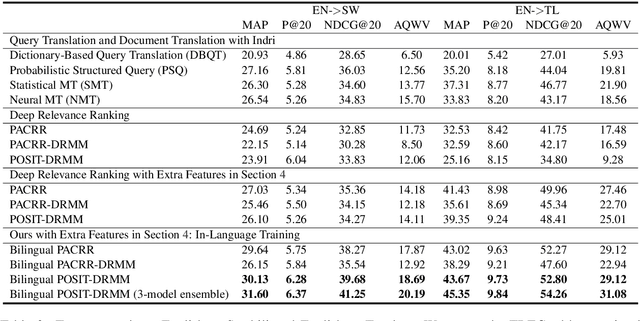
In this paper, we propose to boost low-resource cross-lingual document retrieval performance with deep bilingual query-document representations. We match queries and documents in both source and target languages with four components, each of which is implemented as a term interaction-based deep neural network with cross-lingual word embeddings as input. By including query likelihood scores as extra features, our model effectively learns to rerank the retrieved documents by using a small number of relevance labels for low-resource language pairs. Due to the shared cross-lingual word embedding space, the model can also be directly applied to another language pair without any training label. Experimental results on the MATERIAL dataset show that our model outperforms the competitive translation-based baselines on English-Swahili, English-Tagalog, and English-Somali cross-lingual information retrieval tasks.
Zero-shot Transfer Learning for Semantic Parsing
Aug 27, 2018
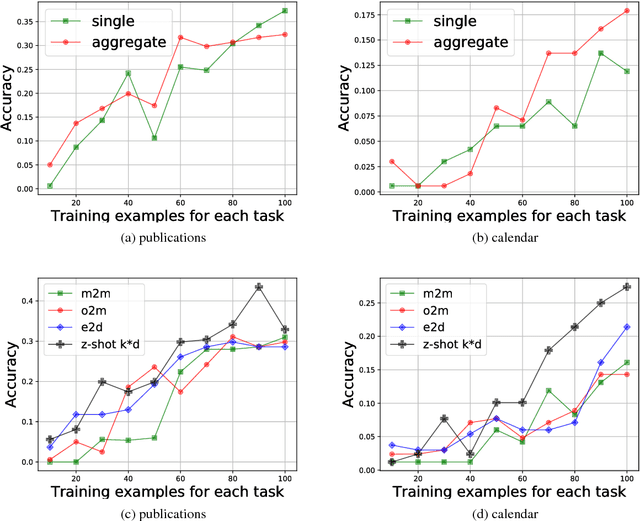
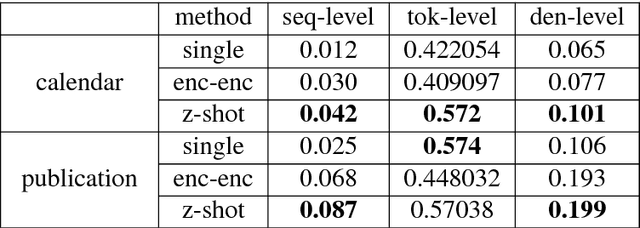
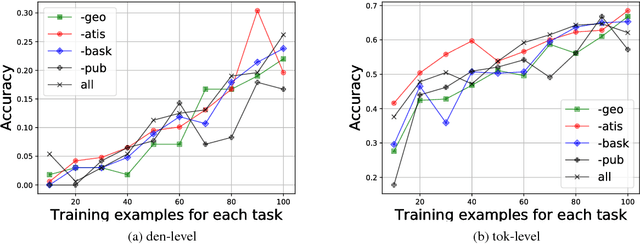
While neural networks have shown impressive performance on large datasets, applying these models to tasks where little data is available remains a challenging problem. In this paper we propose to use feature transfer in a zero-shot experimental setting on the task of semantic parsing. We first introduce a new method for learning the shared space between multiple domains based on the prediction of the domain label for each example. Our experiments support the superiority of this method in a zero-shot experimental setting in terms of accuracy metrics compared to state-of-the-art techniques. In the second part of this paper we study the impact of individual domains and examples on semantic parsing performance. We use influence functions to this aim and investigate the sensitivity of domain-label classification loss on each example. Our findings reveal that cross-domain adversarial attacks identify useful examples for training even from the domains the least similar to the target domain. Augmenting our training data with these influential examples further boosts our accuracy at both the token and the sequence level.