 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Wide, Focus Deep: Automated Fetal Brain Extraction with Sparse Training Data
Oct 29, 2024



Automated fetal brain extraction from full-uterus MRI is a challenging task due to variable head sizes, orientations, complex anatomy, and prevalent artifacts. While deep-learning (DL) models trained on synthetic images have been successful in adult brain extraction, adapting these networks for fetal MRI is difficult due to the sparsity of labeled data, leading to increased false-positive predictions. To address this challenge, we propose a test-time strategy that reduces false positives in networks trained on sparse, synthetic labels. The approach uses a breadth-fine search (BFS) to identify a subvolume likely to contain the fetal brain, followed by a deep-focused sliding window (DFS) search to refine the extraction, pooling predictions to minimize false positives. We train models at different window sizes using synthetic images derived from a small number of fetal brain label maps, augmented with random geometric shapes. Each model is trained on diverse head positions and scales, including cases with partial or no brain tissue. Our framework matches state-of-the-art brain extraction methods on clinical HASTE scans of third-trimester fetuses and exceeds them by up to 5\% in terms of Dice in the second trimester as well as EPI scans across both trimesters. Our results demonstrate the utility of a sliding-window approach and combining predictions from several models trained on synthetic images, for improving brain-extraction accuracy by progressively refining regions of interest and minimizing the risk of missing brain mask slices or misidentifying other tissues as brain.
Enhancement attacks in biomedical machine learning
Jan 05, 2023
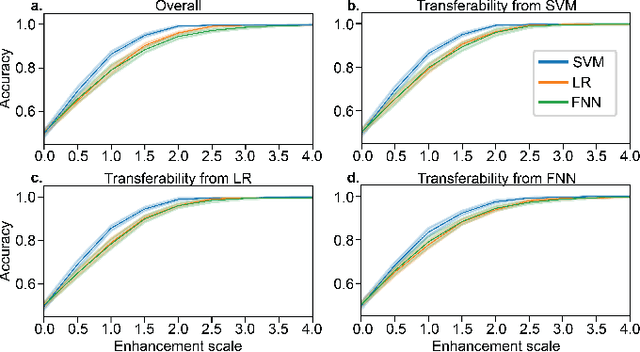

The prevalence of machine learning in biomedical research is rapidly growing, yet the trustworthiness of such research is often overlooked. While some previous works have investigated the ability of adversarial attacks to degrade model performance in medical imaging, the ability to falsely improve performance via recently-developed "enhancement attacks" may be a greater threat to biomedical machine learning. In the spirit of developing attacks to better understand trustworthiness, we developed three techniques to drastically enhance prediction performance of classifiers with minimal changes to features, including the enhancement of 1) within-dataset predictions, 2) a particular method over another, and 3) cross-dataset generalization. Our within-dataset enhancement framework falsely improved classifiers' accuracy from 50% to almost 100% while maintaining high feature similarities between original and enhanced data (Pearson's r's>0.99). Similarly, the method-specific enhancement framework was effective in falsely improving the performance of one method over another. For example, a simple neural network outperformed LR by 50% on our enhanced dataset, although no performance differences were present in the original dataset. Crucially, the original and enhanced data were still similar (r=0.95). Finally, we demonstrated that enhancement is not specific to within-dataset predictions but can also be adapted to enhance the generalization accuracy of one dataset to another by up to 38%. Overall, our results suggest that more robust data sharing and provenance tracking pipelines are necessary to maintain data integrity in biomedical machine learning research.
The Exact Class of Graph Functions Generated by Graph Neural Networks
Feb 17, 2022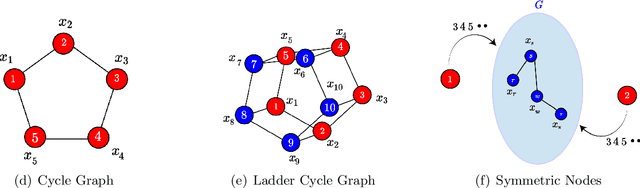
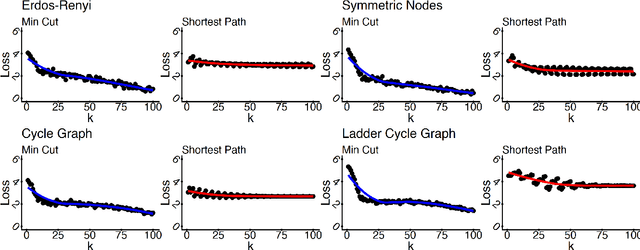
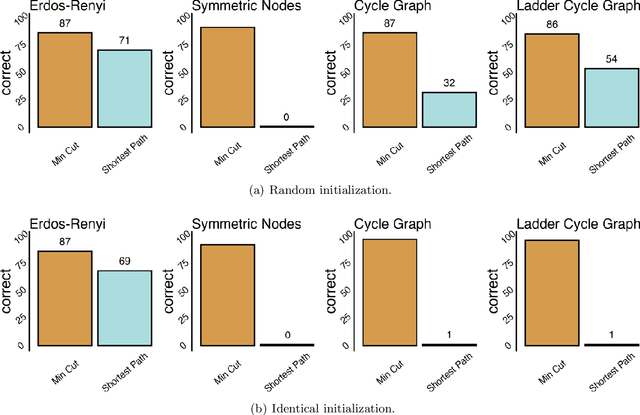
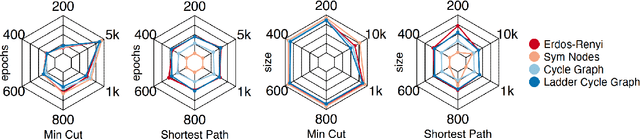
Given a graph function, defined on an arbitrary set of edge weights and node features, does there exist a Graph Neural Network (GNN) whose output is identical to the graph function? In this paper, we fully answer this question and characterize the class of graph problems that can be represented by GNNs. We identify an algebraic condition, in terms of the permutation of edge weights and node features, which proves to be necessary and sufficient for a graph problem to lie within the reach of GNNs. Moreover, we show that this condition can be efficiently verified by checking quadratically many constraints. Note that our refined characterization on the expressive power of GNNs are orthogonal to those theoretical results showing equivalence between GNNs and Weisfeiler-Lehman graph isomorphism heuristic. For instance, our characterization implies that many natural graph problems, such as min-cut value, max-flow value, and max-clique size, can be represented by a GNN. In contrast, and rather surprisingly, there exist very simple graphs for which no GNN can correctly find the length of the shortest paths between all nodes. Note that finding shortest paths is one of the most classical problems in Dynamic Programming (DP). Thus, the aforementioned negative example highlights the misalignment between DP and GNN, even though (conceptually) they follow very similar iterative procedures. Finally, we support our theoretical results by experimental simulations.
Data-driven mapping between functional connectomes using optimal transport
Jul 02, 2021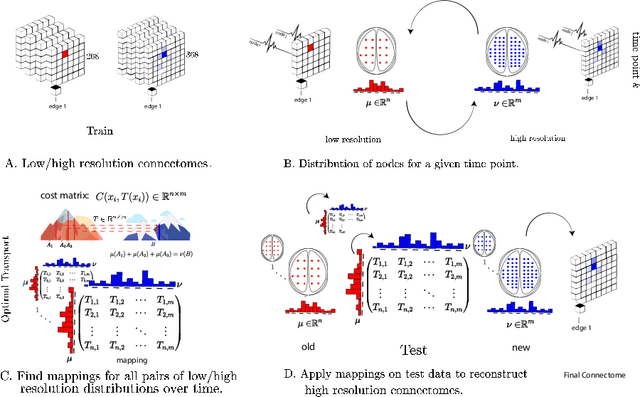
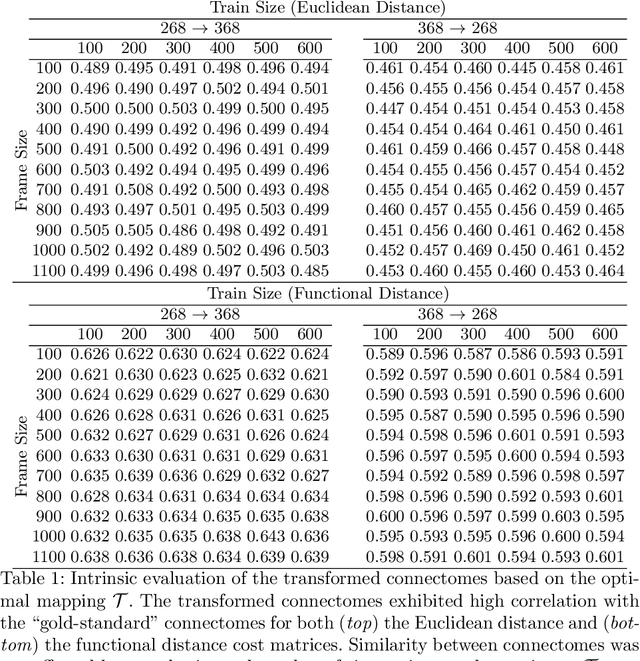

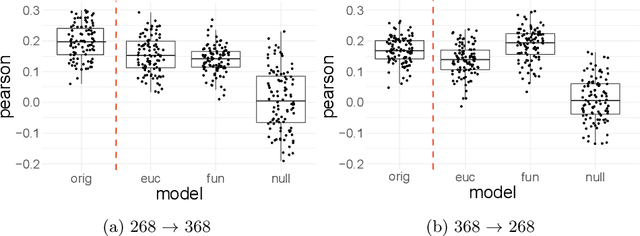
Functional connectomes derived from functional magnetic resonance imaging have long been used to understand the functional organization of the brain. Nevertheless, a connectome is intrinsically linked to the atlas used to create it. In other words, a connectome generated from one atlas is different in scale and resolution compared to a connectome generated from another atlas. Being able to map connectomes and derived results between different atlases without additional pre-processing is a crucial step in improving interpretation and generalization between studies that use different atlases. Here, we use optimal transport, a powerful mathematical technique, to find an optimum mapping between two atlases. This mapping is then used to transform time series from one atlas to another in order to reconstruct a connectome. We validate our approach by comparing transformed connectomes against their "gold-standard" counterparts (i.e., connectomes generated directly from an atlas) and demonstrate the utility of transformed connectomes by applying these connectomes to predictive models based on a different atlas. We show that these transformed connectomes are significantly similar to their "gold-standard" counterparts and maintain individual differences in brain-behavior associations, demonstrating both the validity of our approach and its utility in downstream analyses. Overall, our approach is a promising avenue to increase the generalization of connectome-based results across different atlases.
Zero-shot Transfer Learning for Semantic Parsing
Aug 27, 2018
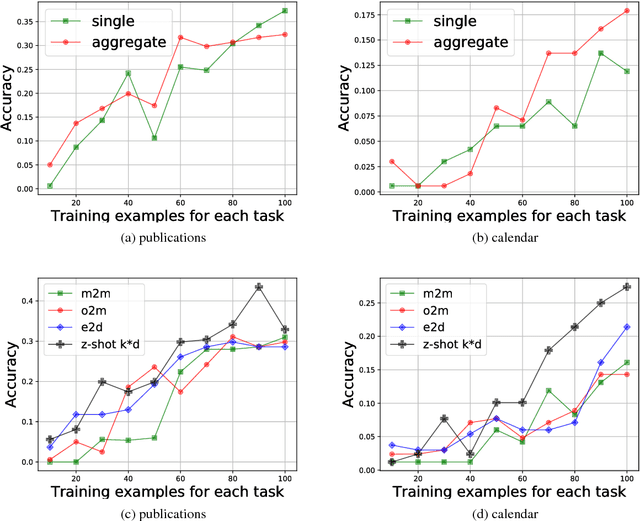
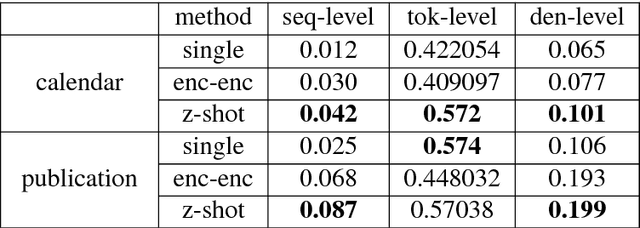
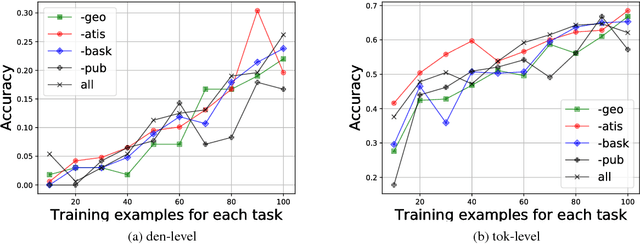
While neural networks have shown impressive performance on large datasets, applying these models to tasks where little data is available remains a challenging problem. In this paper we propose to use feature transfer in a zero-shot experimental setting on the task of semantic parsing. We first introduce a new method for learning the shared space between multiple domains based on the prediction of the domain label for each example. Our experiments support the superiority of this method in a zero-shot experimental setting in terms of accuracy metrics compared to state-of-the-art techniques. In the second part of this paper we study the impact of individual domains and examples on semantic parsing performance. We use influence functions to this aim and investigate the sensitivity of domain-label classification loss on each example. Our findings reveal that cross-domain adversarial attacks identify useful examples for training even from the domains the least similar to the target domain. Augmenting our training data with these influential examples further boosts our accuracy at both the token and the sequence level.
Sequence to Logic with Copy and Cache
Jul 19, 2018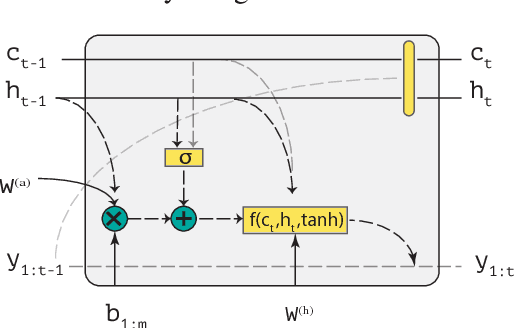
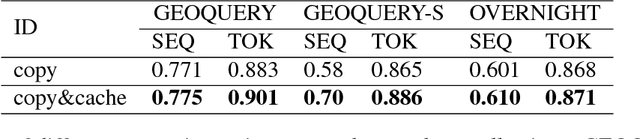
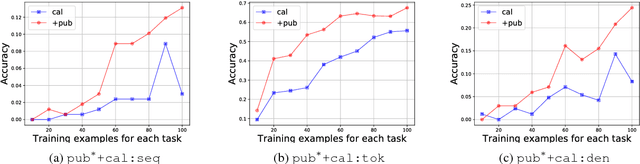

Generating logical form equivalents of human language is a fresh way to employ neural architectures where long short-term memory effectively captures dependencies in both encoder and decoder units. The logical form of the sequence usually preserves information from the natural language side in the form of similar tokens, and recently a copying mechanism has been proposed which increases the probability of outputting tokens from the source input through decoding. In this paper we propose a caching mechanism as a more general form of the copying mechanism which also weighs all the words from the source vocabulary according to their relation to the current decoding context. Our results confirm that the proposed method achieves improvements in sequence/token-level accuracy on sequence to logical form tasks. Further experiments on cross-domain adversarial attacks show substantial improvements when using the most influential examples of other domains for training.
Dimension Projection among Languages based on Pseudo-relevant Documents for Query Translation
Oct 08, 2016
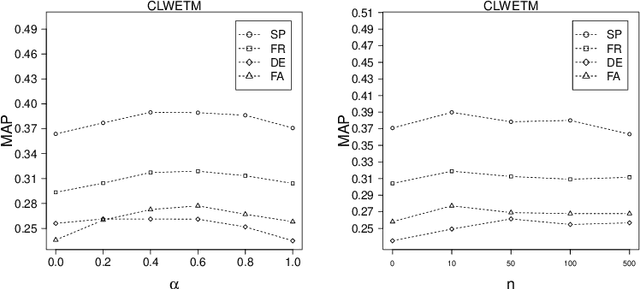
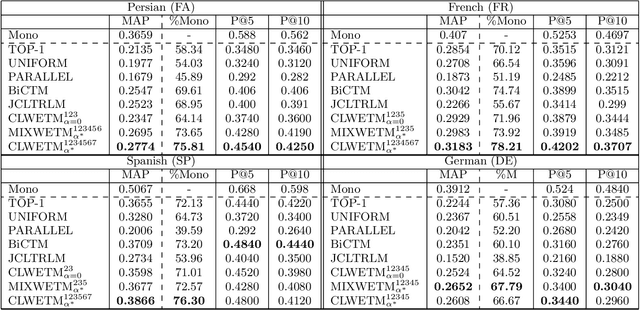
Using top-ranked documents in response to a query has been shown to be an effective approach to improve the quality of query translation in dictionary-based cross-language information retrieval. In this paper, we propose a new method for dictionary-based query translation based on dimension projection of embedded vectors from the pseudo-relevant documents in the source language to their equivalents in the target language. To this end, first we learn low-dimensional vectors of the words in the pseudo-relevant collections separately and then aim to find a query-dependent transformation matrix between the vectors of translation pairs appeared in the collections. At the next step, representation of each query term is projected to the target language and then, after using a softmax function, a query-dependent translation model is built. Finally, the model is used for query translation. Our experiments on four CLEF collections in French, Spanish, German, and Italian demonstrate that the proposed method outperforms a word embedding baseline based on bilingual shuffling and a further number of competitive baselines. The proposed method reaches up to 87% performance of machine translation (MT) in short queries and considerable improvements in verbose queries.
SS4MCT: A Statistical Stemmer for Morphologically Complex Texts
Jun 20, 2016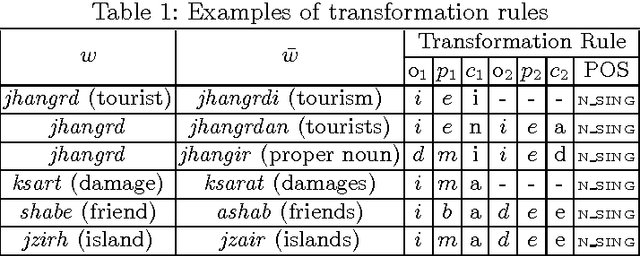

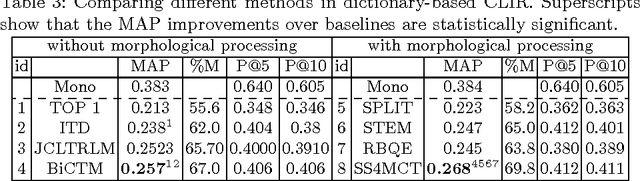
There have been multiple attempts to resolve various inflection matching problems in information retrieval. Stemming is a common approach to this end. Among many techniques for stemming, statistical stemming has been shown to be effective in a number of languages, particularly highly inflected languages. In this paper we propose a method for finding affixes in different positions of a word. Common statistical techniques heavily rely on string similarity in terms of prefix and suffix matching. Since infixes are common in irregular/informal inflections in morphologically complex texts, it is required to find infixes for stemming. In this paper we propose a method whose aim is to find statistical inflectional rules based on minimum edit distance table of word pairs and the likelihoods of the rules in a language. These rules are used to statistically stem words and can be used in different text mining tasks. Experimental results on CLEF 2008 and CLEF 2009 English-Persian CLIR tasks indicate that the proposed method significantly outperforms all the baselines in terms of MAP.
A Probabilistic Translation Method for Dictionary-based Cross-lingual Information Retrieval in Agglutinative Languages
Nov 05, 2014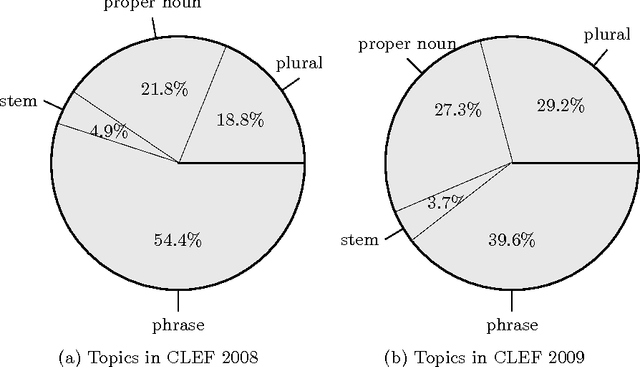


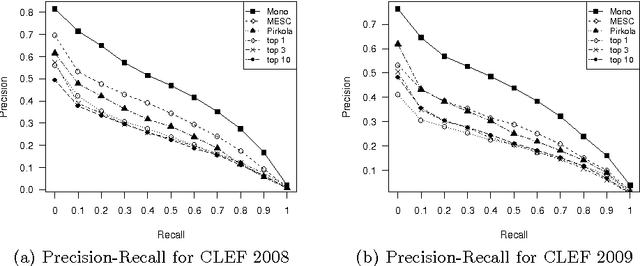
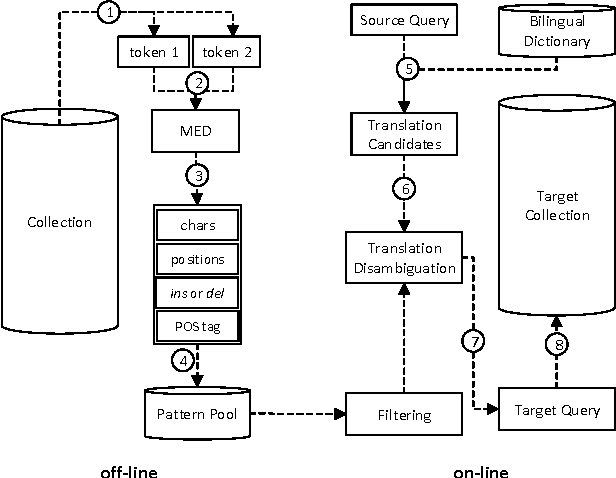
Translation ambiguity, out of vocabulary words and missing some translations in bilingual dictionaries make dictionary-based Cross-language Information Retrieval (CLIR) a challenging task. Moreover, in agglutinative languages which do not have reliable stemmers, missing various lexical formations in bilingual dictionaries degrades CLIR performance. This paper aims to introduce a probabilistic translation model to solve the ambiguity problem, and also to provide most likely formations of a dictionary candidate. We propose Minimum Edit Support Candidates (MESC) method that exploits a monolingual corpus and a bilingual dictionary to translate users' native language queries to documents' language. Our experiments show that the proposed method outperforms state-of-the-art dictionary-based English-Persian CLIR.