 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONGRAD:Conflicting Gradient Filtering for Multilingual Preference Alignment
Mar 31, 2025Naive joint training of large language models (LLMs) for multilingual preference alignment can suffer from negative interference. This is a known issue in multilingual training, where conflicting objectives degrade overall performance. However, the impact of this phenomenon in the context of multilingual preference alignment remains largely underexplored. To address this issue, we propose CONGRAD, a scalable and effective filtering method that selects high-quality preference samples with minimal gradient conflicts across languages. Our method leverages gradient surgery to retain samples aligned with an aggregated multilingual update direction. Additionally, we incorporate a sublinear gradient compression strategy that reduces memory overhead during gradient accumulation. We integrate CONGRAD into self-rewarding framework and evaluate on LLaMA3-8B and Gemma2-2B across 10 languages. Results show that CONGRAD consistently outperforms strong baselines in both seen and unseen languages, with minimal alignment tax.
Machine Translation for Machines: the Sentiment Classification Use Case
Oct 01, 2019
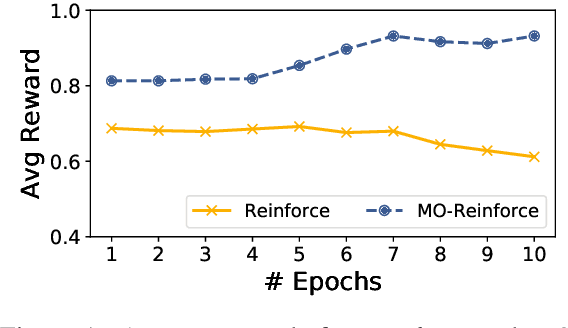
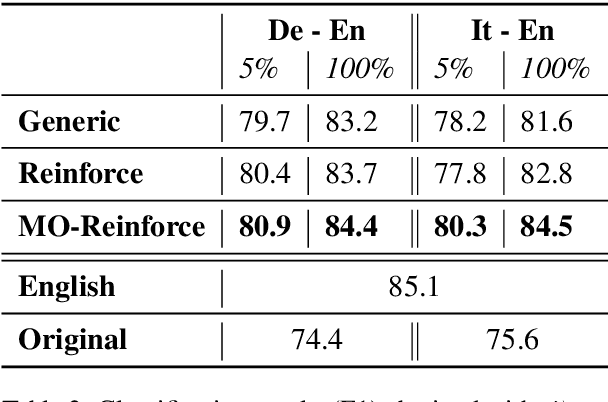
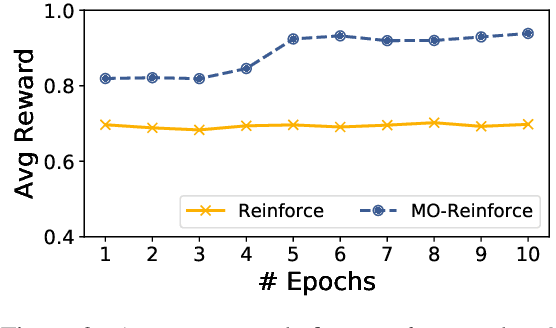
We propose a neural machine translation (NMT) approach that, instead of pursuing adequacy and fluency ("human-oriented" quality criteria), aims to generate translations that are best suited as input to a natural language processing component designed for a specific downstream task (a "machine-oriented" criterion). Towards this objective, we present a reinforcement learning technique based on a new candidate sampling strategy, which exploits the results obtained on the downstream task as weak feedback. Experiments in sentiment classification of Twitter data in German and Italian show that feeding an English classifier with machine-oriented translations significantly improves its performance. Classification results outperform those obtained with translations produced by general-purpose NMT models as well as by an approach based on reinforcement learning. Moreover, our results on both languages approximate the classification accuracy computed on gold standard English tweets.
Dimension Projection among Languages based on Pseudo-relevant Documents for Query Translation
Oct 08, 2016
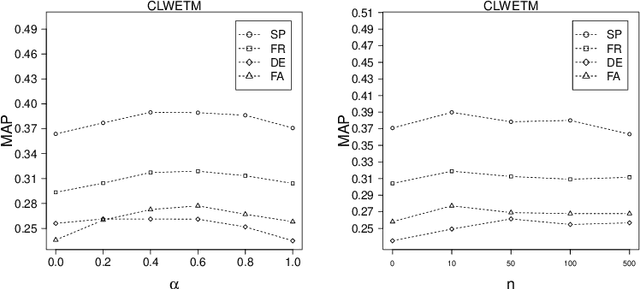
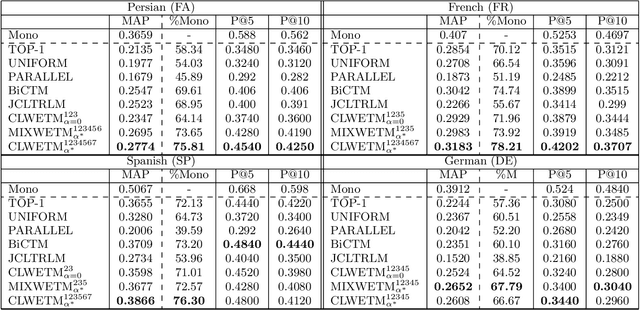
Using top-ranked documents in response to a query has been shown to be an effective approach to improve the quality of query translation in dictionary-based cross-language information retrieval. In this paper, we propose a new method for dictionary-based query translation based on dimension projection of embedded vectors from the pseudo-relevant documents in the source language to their equivalents in the target language. To this end, first we learn low-dimensional vectors of the words in the pseudo-relevant collections separately and then aim to find a query-dependent transformation matrix between the vectors of translation pairs appeared in the collections. At the next step, representation of each query term is projected to the target language and then, after using a softmax function, a query-dependent translation model is built. Finally, the model is used for query translation. Our experiments on four CLEF collections in French, Spanish, German, and Italian demonstrate that the proposed method outperforms a word embedding baseline based on bilingual shuffling and a further number of competitive baselines. The proposed method reaches up to 87% performance of machine translation (MT) in short queries and considerable improvements in verbose queries.