 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDP-GRPO: Stabilized Group Relative Policy Optimization for Multi-Constraint Instruction Following
Jun 04, 2026Reinforcement learning with verifiable rewards is ideal for multi-constraint instruction following, yet standard group-relative policy optimization (GRPO) becomes unstable under discrete, low-dispersion rewards, where within-group reward distributions are frequently homogeneous. We identify and formalize three pathologies of z-score group normalization in this regime: low-variance amplification, mean-centering blindness, and zero-variance collapse. To address them, we propose MDP-GRPO, which stabilizes learning through (1) multi-temperature sampling to increase reward dispersion, (2) dual-anchor advantages to restore gradients in homogeneous groups and stop mean-centering blindness, (3) prospect-theoretic shaping to bound updates and penalize violations based on Kahneman and Tversky's theory, and (4) asymmetric KL regularization. Evaluated on FollowBench, IFEval, and a curated multi-constraint dataset, MDP-GRPO outperforms standard GRPO, improving strict constraint satisfaction by up to 5.0% on Llama-3.2-3B. Our method also enables stable convergence with small group sizes while preserving general capabilities on MMLU and ARC.
PARSA-Bench: A Comprehensive Persian Audio-Language Model Benchmark
Mar 15, 2026Persian poses unique audio understanding challenges through its classical poetry, traditional music, and pervasive code-switching - none captured by existing benchmarks. We introduce PARSA-Bench (Persian Audio Reasoning and Speech Assessment Benchmark), the first benchmark for evaluating large audio-language models on Persian language and culture, comprising 16 tasks and over 8,000 samples across speech understanding, paralinguistic analysis, and cultural audio understanding. Ten tasks are newly introduced, including poetry meter and style detection, traditional Persian music understanding, and code-switching detection. Text-only baselines consistently outperform audio counterparts, suggesting models may not leverage audio-specific information beyond what transcription alone provides. Culturally-grounded tasks expose a qualitatively distinct failure mode: all models perform near random chance on vazn detection regardless of scale, suggesting prosodic perception remains beyond the reach of current models. The dataset is publicly available at https://huggingface.co/datasets/MohammadJRanjbar/PARSA-Bench
PersianPunc: A Large-Scale Dataset and BERT-Based Approach for Persian Punctuation Restoration
Mar 05, 2026Punctuation restoration is essential for improving the readability and downstream utility of automatic speech recognition (ASR) outputs, yet remains underexplored for Persian despite its importance. We introduce PersianPunc, a large-scale, high-quality dataset of 17 million samples for Persian punctuation restoration, constructed through systematic aggregation and filtering of existing textual resources. We formulate punctuation restoration as a token-level sequence labeling task and fine-tune ParsBERT to achieve strong performance. Through comparative evaluation, we demonstrate that while large language models can perform punctuation restoration, they suffer from critical limitations: over-correction tendencies that introduce undesired edits beyond punctuation insertion (particularly problematic for speech-to-text pipelines) and substantially higher computational requirements. Our lightweight BERT-based approach achieves a macro-averaged F1 score of 91.33% on our test set while maintaining efficiency suitable for real-time applications. We make our dataset (https://huggingface.co/datasets/MohammadJRanjbar/persian-punctuation-restoration) and model (https://huggingface.co/MohammadJRanjbar/parsbert-persian-punctuation) publicly available to facilitate future research in Persian NLP and provide a scalable framework applicable to other morphologically rich, low-resource languages.
DEEPQUESTION: Systematic Generation of Real-World Challenges for Evaluating LLMs Performance
May 30, 2025LLMs often excel on standard benchmarks but falter on real-world tasks. We introduce DeepQuestion, a scalable automated framework that augments existing datasets based on Bloom's taxonomy and creates novel questions that trace original solution paths to probe evaluative and creative skills. Extensive experiments across ten open-source and proprietary models, covering both general-purpose and reasoning LLMs, reveal substantial performance drops (even up to 70% accuracy loss) on higher-order tasks, underscoring persistent gaps in deep reasoning. Our work highlights the need for cognitively diverse benchmarks to advance LLM progress. DeepQuestion and related datasets will be released upon acceptance of the paper.
SchemaGraphSQL: Efficient Schema Linking with Pathfinding Graph Algorithms for Text-to-SQL on Large-Scale Databases
May 23, 2025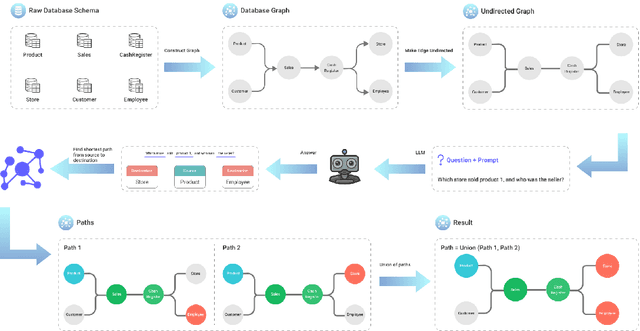
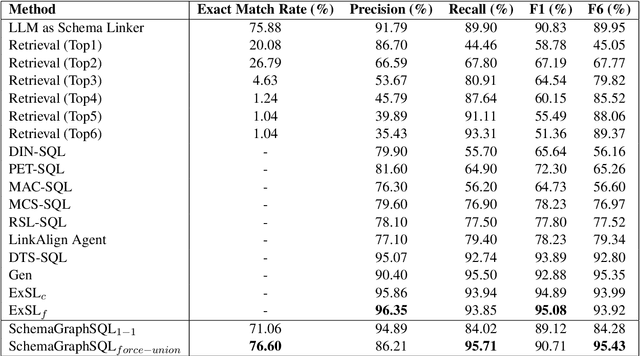
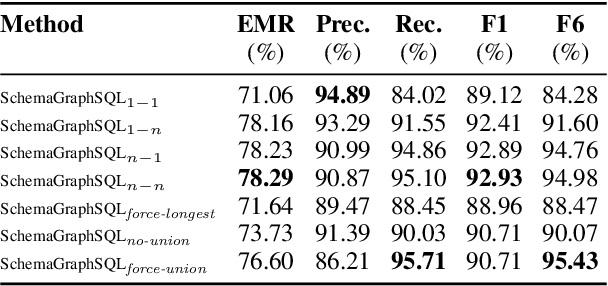
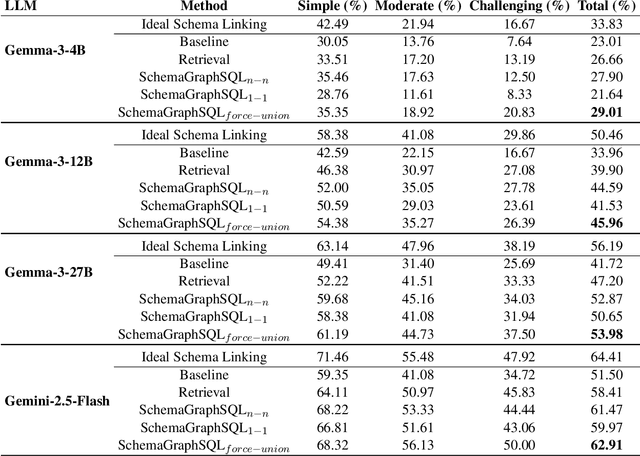
Text-to-SQL systems translate natural language questions into executable SQL queries, and recent progress with large language models (LLMs) has driven substantial improvements in this task. Schema linking remains a critical component in Text-to-SQL systems, reducing prompt size for models with narrow context windows and sharpening model focus even when the entire schema fits. We present a zero-shot, training-free schema linking approach that first constructs a schema graph based on foreign key relations, then uses a single prompt to Gemini 2.5 Flash to extract source and destination tables from the user query, followed by applying classical path-finding algorithms and post-processing to identify the optimal sequence of tables and columns that should be joined, enabling the LLM to generate more accurate SQL queries. Despite being simple, cost-effective, and highly scalable, our method achieves state-of-the-art results on the BIRD benchmark, outperforming previous specialized, fine-tuned, and complex multi-step LLM-based approaches. We conduct detailed ablation studies to examine the precision-recall trade-off in our framework. Additionally, we evaluate the execution accuracy of our schema filtering method compared to other approaches across various model sizes.
Matina: A Large-Scale 73B Token Persian Text Corpus
Feb 13, 2025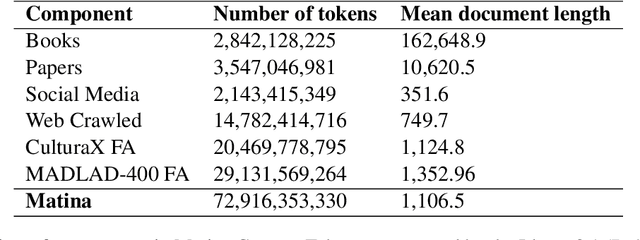
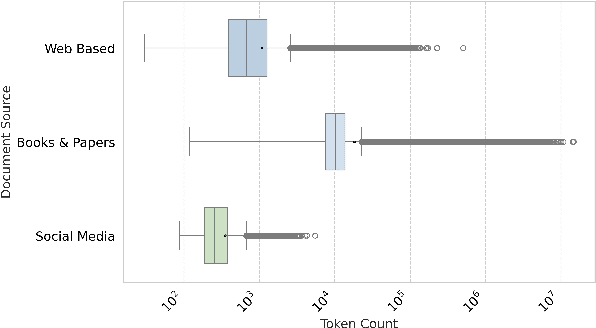

Text corpora are essential for training models used in tasks like summarization, translation, and large language models (LLMs). While various efforts have been made to collect monolingual and multilingual datasets in many languages, Persian has often been underrepresented due to limited resources for data collection and preprocessing. Existing Persian datasets are typically small and lack content diversity, consisting mainly of weblogs and news articles. This shortage of high-quality, varied data has slowed the development of NLP models and open-source LLMs for Persian. Since model performance depends heavily on the quality of training data, we address this gap by introducing the Matina corpus, a new Persian dataset of 72.9B tokens, carefully preprocessed and deduplicated to ensure high data quality. We further assess its effectiveness by training and evaluating transformer-based models on key NLP tasks. Both the dataset and preprocessing codes are publicly available, enabling researchers to build on and improve this resource for future Persian NLP advancements.
PerSHOP -- A Persian dataset for shopping dialogue systems modeling
Jan 01, 2024Nowadays, dialogue systems are used in many fields of industry and research. There are successful instances of these systems, such as Apple Siri, Google Assistant, and IBM Watson. Task-oriented dialogue system is a category of these, that are used in specific tasks. They can perform tasks such as booking plane tickets or making restaurant reservations. Shopping is one of the most popular areas on these systems. The bot replaces the human salesperson and interacts with the customers by speaking. To train the models behind the scenes of these systems, annotated data is needed. In this paper, we developed a dataset of dialogues in the Persian language through crowd-sourcing. We annotated these dialogues to train a model. This dataset contains nearly 22k utterances in 15 different domains and 1061 dialogues. This is the largest Persian dataset in this field, which is provided freely so that future researchers can use it. Also, we proposed some baseline models for natural language understanding (NLU) tasks. These models perform two tasks for NLU: intent classification and entity extraction. The F-1 score metric obtained for intent classification is around 91% and for entity extraction is around 93%, which can be a baseline for future research.
Persian Typographical Error Type Detection using Many-to-Many Deep Neural Networks on Algorithmically-Generated Misspellings
May 19, 2023Digital technologies have led to an influx of text created daily in a variety of languages, styles, and formats. A great deal of the popularity of spell-checking systems can be attributed to this phenomenon since they are crucial to polishing the digitally conceived text. In this study, we tackle Typographical Error Type Detection in Persian, which has been relatively understudied. In this paper, we present a public dataset named FarsTypo, containing 3.4 million chronologically ordered and part-of-speech tagged words of diverse topics and linguistic styles. An algorithm for applying Persian-specific errors is developed and applied to a scalable size of these words, forming a parallel dataset of correct and incorrect words. Using FarsTypo, we establish a firm baseline and compare different methodologies using various architectures. In addition, we present a novel Many-to-Many Deep Sequential Neural Network to perform token classification using both word and character embeddings in combination with bidirectional LSTM layers to detect typographical errors across 51 classes. We compare our approach with highly-advanced industrial systems that, unlike this study, have been developed utilizing a variety of resources. The results of our final method were competitive in that we achieved an accuracy of 97.62%, a precision of 98.83%, a recall of 98.61%, and outperformed the rest in terms of speed.
Mismatching-Aware Unsupervised Translation Quality Estimation For Low-Resource Languages
Jul 31, 2022

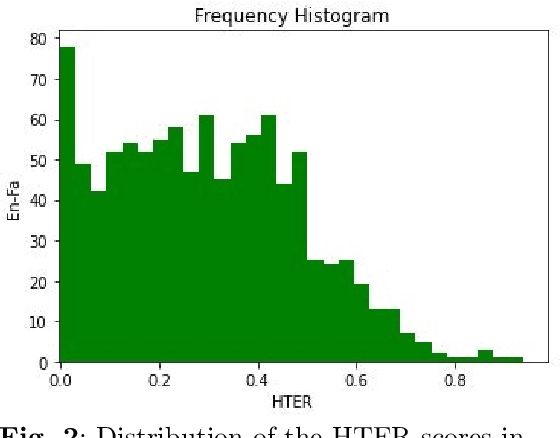
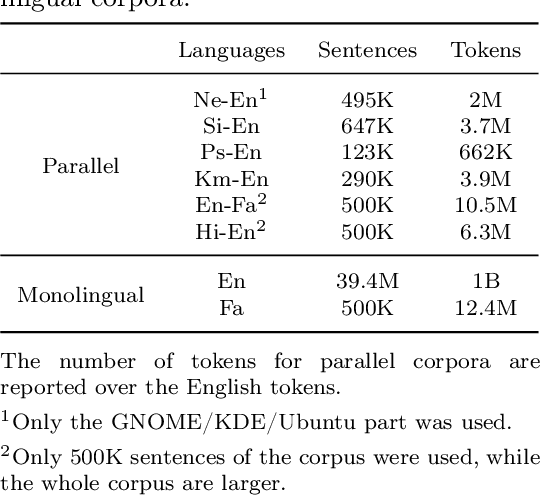
Translation Quality Estimation (QE) is the task of predicting the quality of machine translation (MT) output without any reference. This task has gained increasing attention as an important component in practical applications of MT. In this paper, we first propose XLMRScore, a simple unsupervised QE method based on the BERTScore computed using the XLM-RoBERTa (XLMR) model while discussing the issues that occur using this method. Next, we suggest two approaches to mitigate the issues: replacing untranslated words with the unknown token and the cross-lingual alignment of pre-trained model to represent aligned words closer to each other. We evaluate the proposed method on four low-resource language pairs of WMT21 QE shared task, as well as a new English-Farsi test dataset introduced in this paper. Experiments show that our method could get comparable results with the supervised baseline for two zero-shot scenarios, i.e., with less than 0.01 difference in Pearson correlation, while outperforming the unsupervised rivals in all the low-resource language pairs for above 8% in average.
Pruned Graph Neural Network for Short Story Ordering
Mar 13, 2022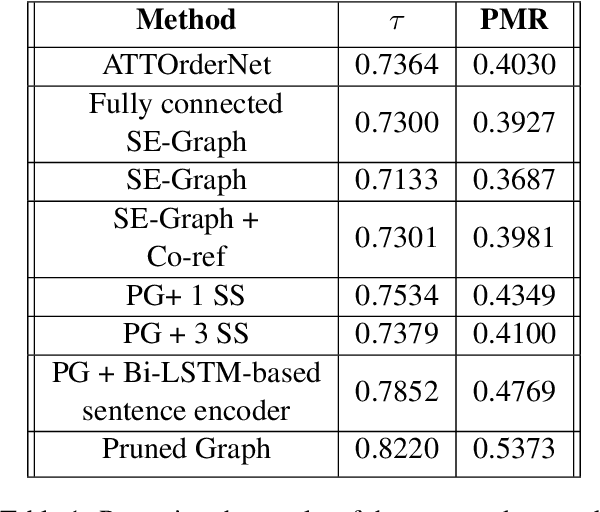
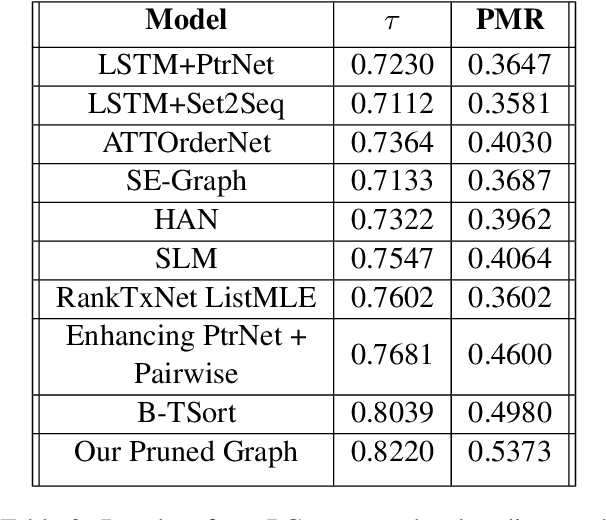
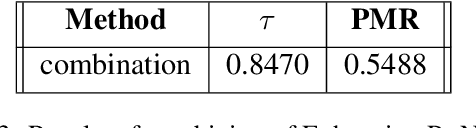
Text coherence is a fundamental problem in natural language generation and understanding. Organizing sentences into an order that maximizes coherence is known as sentence ordering. This paper is proposing a new approach based on the graph neural network approach to encode a set of sentences and learn orderings of short stories. We propose a new method for constructing sentence-entity graphs of short stories to create the edges between sentences and reduce noise in our graph by replacing the pronouns with their referring entities. We improve the sentence ordering by introducing an aggregation method based on majority voting of state-of-the-art methods and our proposed one. Our approach employs a BERT-based model to learn semantic representations of the sentences. The results demonstrate that the proposed method significantly outperforms existing baselines on a corpus of short stories with a new state-of-the-art performance in terms of Perfect Match Ratio (PMR) and Kendall's Tau (Tau) metrics. More precisely, our method increases PMR and Tau criteria by more than 5% and 4.3%, respectively. These outcomes highlight the benefit of forming the edges between sentences based on their cosine similarity. We also observe that replacing pronouns with their referring entities effectively encodes sentences in sentence-entity graphs.