 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Jointly Batch Selection for Data Efficient Machine Translation Fine-Tuning
Nov 06, 2025Data quality and its effective selection are fundamental to improving the performance of machine translation models, serving as cornerstones for achieving robust and reliable translation systems. This paper presents a data selection methodology specifically designed for fine-tuning machine translation systems, which leverages the synergy between a learner model and a pre-trained reference model to enhance overall training effectiveness. By defining a learnability score, our approach systematically evaluates the utility of data points for training, ensuring that only the most relevant and impactful examples contribute to the fine-tuning process. Furthermore, our method employs a batch selection strategy which considers interdependencies among data points, optimizing the efficiency of the training process while maintaining a focus on data relevance. Experiments on English to Persian and several other language pairs using an mBART model fine-tuned on the CCMatrix dataset demonstrate that our method can achieve up to a fivefold improvement in data efficiency compared to an iid baseline. Experimental results indicate that our approach improves computational efficiency by 24 when utilizing cached embeddings, as it requires fewer training data points. Additionally, it enhances generalization, resulting in superior translation performance compared to random selection method.
DEEPQUESTION: Systematic Generation of Real-World Challenges for Evaluating LLMs Performance
May 30, 2025LLMs often excel on standard benchmarks but falter on real-world tasks. We introduce DeepQuestion, a scalable automated framework that augments existing datasets based on Bloom's taxonomy and creates novel questions that trace original solution paths to probe evaluative and creative skills. Extensive experiments across ten open-source and proprietary models, covering both general-purpose and reasoning LLMs, reveal substantial performance drops (even up to 70% accuracy loss) on higher-order tasks, underscoring persistent gaps in deep reasoning. Our work highlights the need for cognitively diverse benchmarks to advance LLM progress. DeepQuestion and related datasets will be released upon acceptance of the paper.
Towards Data-Efficient Language Models: A Child-Inspired Approach to Language Learning
Mar 06, 2025In this work, we explain our approach employed in the BabyLM Challenge, which uses various methods of training language models (LMs) with significantly less data compared to traditional large language models (LLMs) and are inspired by how human children learn. While a human child is exposed to far less linguistic input than an LLM, they still achieve remarkable language understanding and generation abilities. To this end, we develop a model trained on a curated dataset consisting of 10 million words, primarily sourced from child-directed transcripts. The 2024 BabyLM Challenge initial dataset of 10M words is filtered to 8.5M. Next, it is supplemented with a randomly selected subset of TVR dataset consisting of 1.5M words of television dialogues. The latter dataset ensures that similar to children, the model is also exposed to language through media. Furthermore, we reduce the vocabulary size to 32,000 tokens, aligning it with the limited vocabulary of children in the early stages of language acquisition. We use curriculum learning and is able to match the baseline on certain benchmarks while surpassing the baseline on others. Additionally, incorporating common LLM training datasets, such as MADLAD-400, degrades performance. These findings underscore the importance of dataset selection, vocabulary scaling, and curriculum learning in creating more data-efficient language models that better mimic human learning processes.
Optimizing Alignment with Less: Leveraging Data Augmentation for Personalized Evaluation
Dec 10, 2024



Automatic evaluation by large language models (LLMs) is a prominent topic today; however, judgment and evaluation tasks are often subjective and influenced by various factors, making adaptation challenging. While many studies demonstrate the capabilities of state-of-the-art proprietary LLMs in comparison to human evaluators, they often struggle to adapt to reference evaluators over time, a requirement for achieving personalized judgment. Additionally, numerous works have attempted to apply open LLMs as judges or evaluators, but these efforts frequently overlook the limitations of working with scarce data. Personalized judgment is inherently associated with limited data scenarios, which are common in many real-world problems. Our work aims to present a data augmentation technique to select a more effective sample from limited data in order to align an open LLM with human preference. Our work achieves approximately 7% improvements in Pearson correlation with a reference judge over the baseline,and 30% improvement over the base model (Llama3.1-8B-Instruct) in the mathematical reasoning evaluation task. demonstrating that augmenting selecting more effective preference data enables our approach to surpass baseline methods.
CoCoP: Enhancing Text Classification with LLM through Code Completion Prompt
Nov 13, 2024



Text classification is a fundamental task in natural language processing (NLP), and large language models (LLMs) have demonstrated their capability to perform this task across various domains. However, the performance of LLMs heavily depends on the quality of their input prompts. Recent studies have also shown that LLMs exhibit remarkable results in code-related tasks. To leverage the capabilities of LLMs in text classification, we propose the Code Completion Prompt (CoCoP) method, which transforms the text classification problem into a code completion task. CoCoP significantly improves text classification performance across diverse datasets by utilizing LLMs' code-completion capability. For instance, CoCoP enhances the accuracy of the SST2 dataset by more than 20%. Moreover, when CoCoP integrated with LLMs specifically designed for code-related tasks (code models), such as CodeLLaMA, this method demonstrates better or comparable performance to few-shot learning techniques while using only one-tenth of the model size. The source code of our proposed method will be available to the public upon the acceptance of the paper.
CULL-MT: Compression Using Language and Layer pruning for Machine Translation
Nov 10, 2024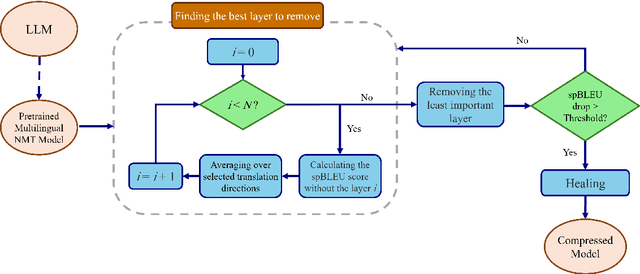
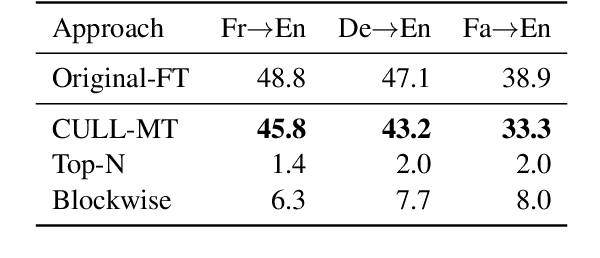
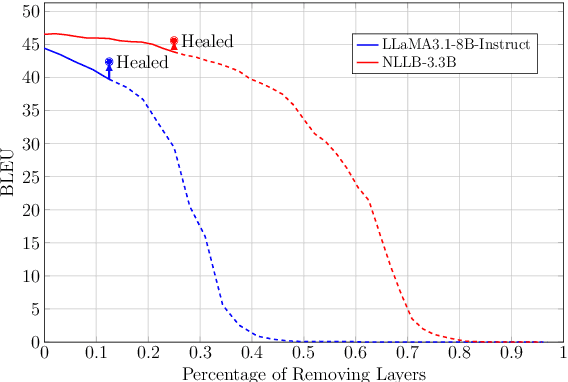
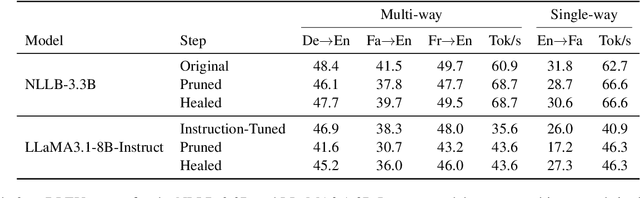
Multilingual machine translation models often outperform traditional bilingual models by leveraging translation knowledge transfer. Recent advancements have led to these models supporting hundreds of languages and achieving state-of-the-art results across various translation directions. However, as these models grow larger, their inference operations become increasingly costly. In many use cases, there is no need to support such a wide range of language pairs, as translation is typically needed in only a few selected directions. In this paper, we present CULL-MT, a compression method for machine translation models based on structural layer pruning and selected language directions. Our approach identifies and prunes unimportant layers using a greedy strategy, then mitigates the impact by applying knowledge distillation from the original model along with parameter-efficient fine-tuning. We apply CULL-MT to the NLLB-3.3B and LLaMA3.1-8B-Instruct models. In a multi-way translation scenario (Persian, French, and German to English), we find the NLLB-3.3B model to be robust, allowing 25% of layers to be pruned with only a 0.9 spBLEU drop. However, LLaMA3.1-8B-Instruct is more sensitive, with a 2.0 spBLEU drop after pruning 5 layers.
PersianMind: A Cross-Lingual Persian-English Large Language Model
Jan 12, 2024Large language models demonstrate remarkable proficiency in various linguistic tasks and have extensive knowledge across various domains. Although they perform best in English, their ability in other languages is notable too. In contrast, open-source models, such as LLaMa, are primarily trained on English datasets, resulting in poor performance in non-English languages. In this paper, we introduce PersianMind, an open-source bilingual large language model which demonstrates comparable performance to closed-source GPT-3.5-turbo in the Persian language. By expanding LLaMa2's vocabulary with 10,000 Persian tokens and training it on a dataset comprising nearly 2 billion Persian tokens, we show that our approach preserves the model's English knowledge and employs transfer learning to excel at transferring task knowledge from one language to another.
Mismatching-Aware Unsupervised Translation Quality Estimation For Low-Resource Languages
Jul 31, 2022

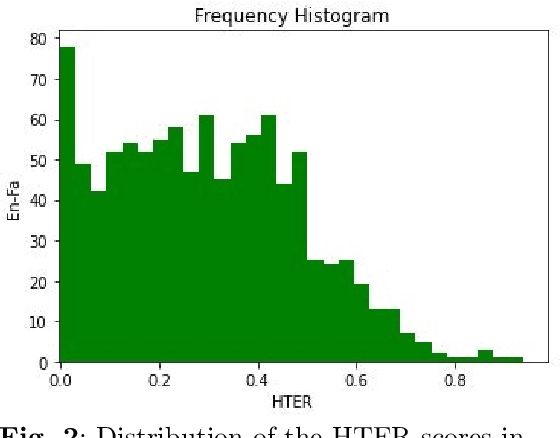
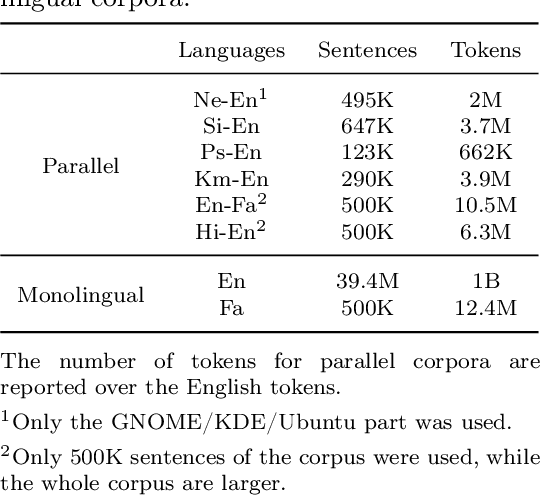
Translation Quality Estimation (QE) is the task of predicting the quality of machine translation (MT) output without any reference. This task has gained increasing attention as an important component in practical applications of MT. In this paper, we first propose XLMRScore, a simple unsupervised QE method based on the BERTScore computed using the XLM-RoBERTa (XLMR) model while discussing the issues that occur using this method. Next, we suggest two approaches to mitigate the issues: replacing untranslated words with the unknown token and the cross-lingual alignment of pre-trained model to represent aligned words closer to each other. We evaluate the proposed method on four low-resource language pairs of WMT21 QE shared task, as well as a new English-Farsi test dataset introduced in this paper. Experiments show that our method could get comparable results with the supervised baseline for two zero-shot scenarios, i.e., with less than 0.01 difference in Pearson correlation, while outperforming the unsupervised rivals in all the low-resource language pairs for above 8% in average.
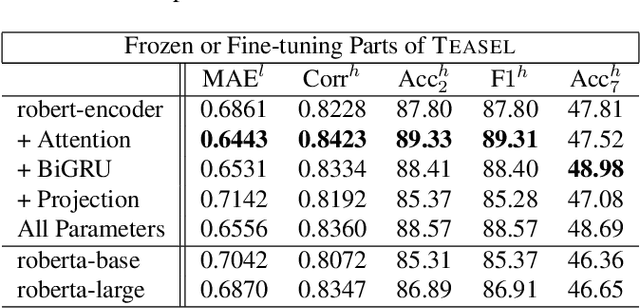
TEASEL: A Transformer-Based Speech-Prefixed Language Model
Sep 12, 2021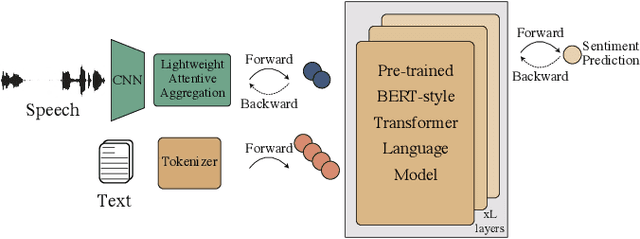
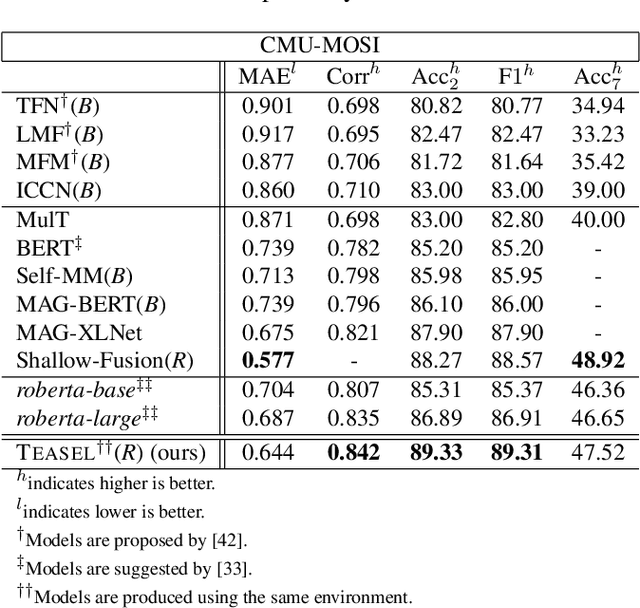
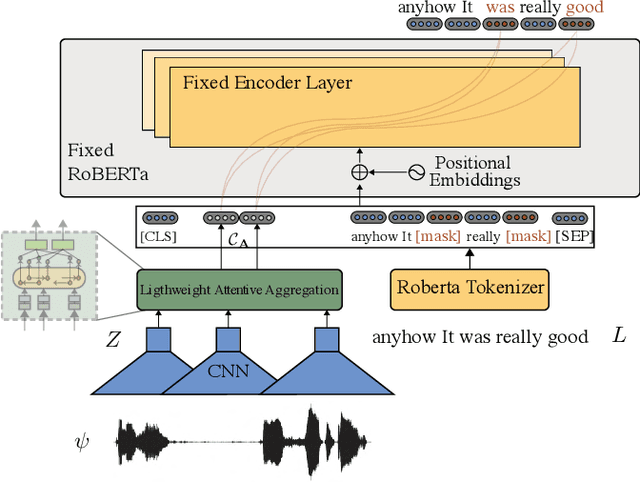
Multimodal language analysis is a burgeoning field of NLP that aims to simultaneously model a speaker's words, acoustical annotations, and facial expressions. In this area, lexicon features usually outperform other modalities because they are pre-trained on large corpora via Transformer-based models. Despite their strong performance, training a new self-supervised learning (SSL) Transformer on any modality is not usually attainable due to insufficient data, which is the case in multimodal language learning. This work proposes a Transformer-Based Speech-Prefixed Language Model called TEASEL to approach the mentioned constraints without training a complete Transformer model. TEASEL model includes speech modality as a dynamic prefix besides the textual modality compared to a conventional language model. This method exploits a conventional pre-trained language model as a cross-modal Transformer model. We evaluated TEASEL for the multimodal sentiment analysis task defined by CMU-MOSI dataset. Extensive experiments show that our model outperforms unimodal baseline language models by 4% and outperforms the current multimodal state-of-the-art (SoTA) model by 1% in F1-score. Additionally, our proposed method is 72% smaller than the SoTA model.
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020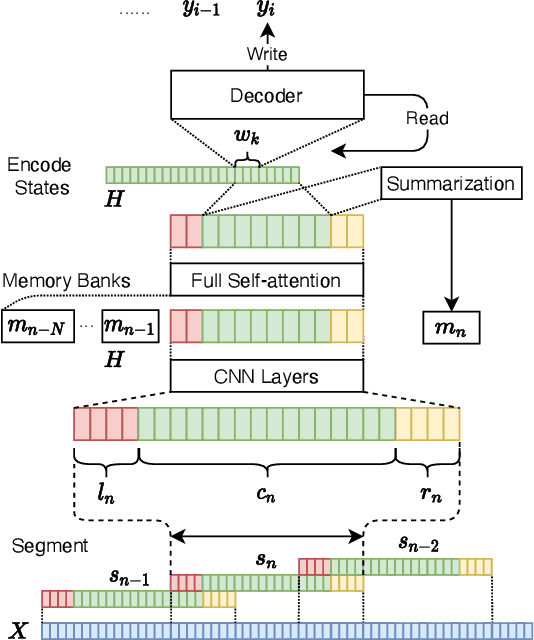
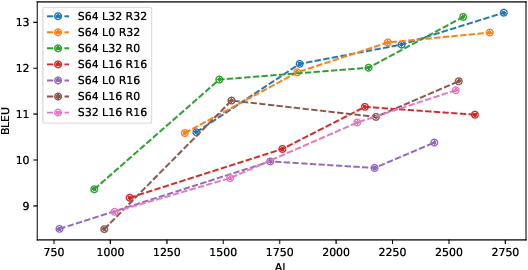
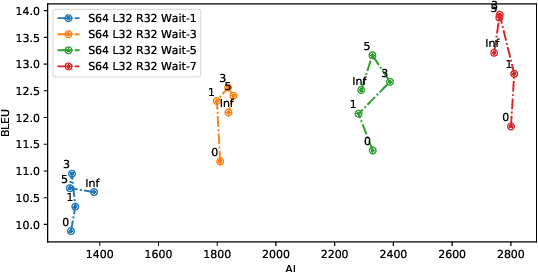
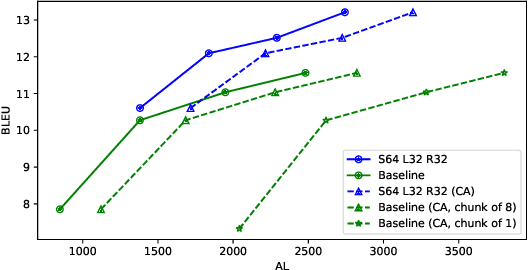
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.