 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Online Data to Enhance Medical Knowledge in a Small Persian Language Model
May 21, 2025



The rapid advancement of language models has demonstrated the potential of artificial intelligence in the healthcare industry. However, small language models struggle with specialized domains in low-resource languages like Persian. While numerous medical-domain websites exist in Persian, no curated dataset or corpus has been available making ours the first of its kind. This study explores the enhancement of medical knowledge in a small language model by leveraging accessible online data, including a crawled corpus from medical magazines and a dataset of real doctor-patient QA pairs. We fine-tuned a baseline model using our curated data to improve its medical knowledge. Benchmark evaluations demonstrate that the fine-tuned model achieves improved accuracy in medical question answering and provides better responses compared to its baseline. This work highlights the potential of leveraging open-access online data to enrich small language models in medical fields, providing a novel solution for Persian medical AI applications suitable for resource-constrained environments.
CULL-MT: Compression Using Language and Layer pruning for Machine Translation
Nov 10, 2024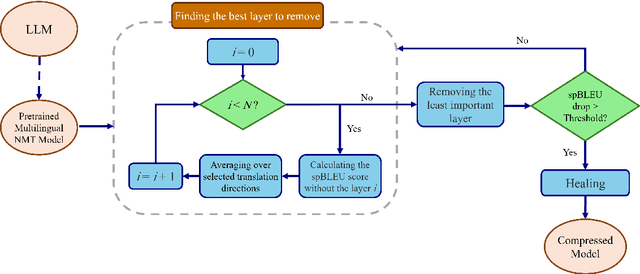
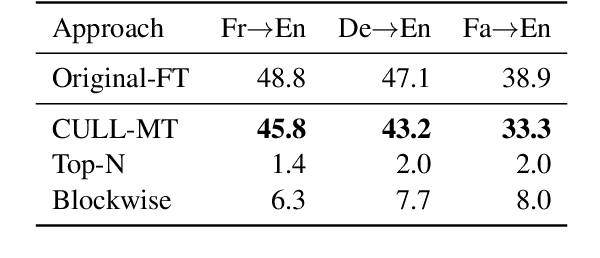
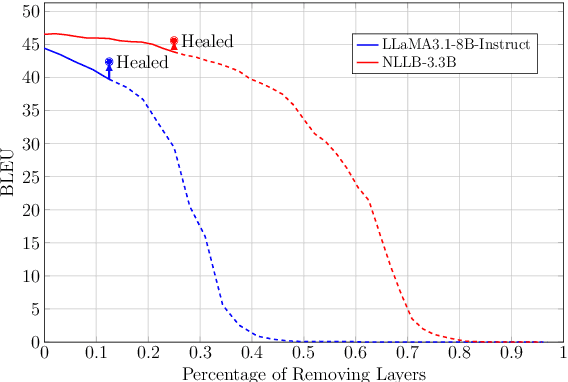
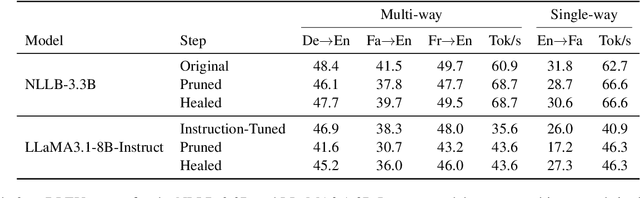
Multilingual machine translation models often outperform traditional bilingual models by leveraging translation knowledge transfer. Recent advancements have led to these models supporting hundreds of languages and achieving state-of-the-art results across various translation directions. However, as these models grow larger, their inference operations become increasingly costly. In many use cases, there is no need to support such a wide range of language pairs, as translation is typically needed in only a few selected directions. In this paper, we present CULL-MT, a compression method for machine translation models based on structural layer pruning and selected language directions. Our approach identifies and prunes unimportant layers using a greedy strategy, then mitigates the impact by applying knowledge distillation from the original model along with parameter-efficient fine-tuning. We apply CULL-MT to the NLLB-3.3B and LLaMA3.1-8B-Instruct models. In a multi-way translation scenario (Persian, French, and German to English), we find the NLLB-3.3B model to be robust, allowing 25% of layers to be pruned with only a 0.9 spBLEU drop. However, LLaMA3.1-8B-Instruct is more sensitive, with a 2.0 spBLEU drop after pruning 5 layers.
PersianMind: A Cross-Lingual Persian-English Large Language Model
Jan 12, 2024Large language models demonstrate remarkable proficiency in various linguistic tasks and have extensive knowledge across various domains. Although they perform best in English, their ability in other languages is notable too. In contrast, open-source models, such as LLaMa, are primarily trained on English datasets, resulting in poor performance in non-English languages. In this paper, we introduce PersianMind, an open-source bilingual large language model which demonstrates comparable performance to closed-source GPT-3.5-turbo in the Persian language. By expanding LLaMa2's vocabulary with 10,000 Persian tokens and training it on a dataset comprising nearly 2 billion Persian tokens, we show that our approach preserves the model's English knowledge and employs transfer learning to excel at transferring task knowledge from one language to another.