 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Appliances: A Robot in the Refrigerator for Home-Based Health Promotion
Feb 26, 2026Kitchen appliances are frequently used domestic artifacts situated at the point of everyday dietary decision making, making them a promising but underexplored site for health promotion. We explore the concept of relational appliances: everyday household devices designed as embodied social actors that engage users through ongoing, personalized interaction. We focus on the refrigerator, whose unique affordances, including a fixed, sensor-rich environment, private interaction space, and close coupling to food items, support contextualized, conversational engagement during snack choices. We present an initial exploration of this concept through a pilot study deploying an anthropomorphic robotic head inside a household refrigerator. In a home-lab apartment, participants repeatedly retrieved snacks during simulated TV "commercial breaks" while interacting with a human-sized robotic head. Participants were randomized to either a health-promotion condition, in which the robot made healthy snack recommendations, or a social-chat control condition. Outcomes included compliance with recommendations, nutritional quality of selected snacks, and psychosocial measures related to acceptance of the robot. Results suggest that participants found the robot persuasive, socially engaging, and increasingly natural over time, often describing it as helpful, aware, and companionable. Most participants reported greater awareness of their snack decisions and expressed interest in having such a robot in their own home. We discuss implications for designing relational appliances that leverage anthropomorphism, trust, and long-term human-technology relationships for home-based health promotion.
Virtual Agents for Alcohol Use Counseling: Exploring LLM-Powered Motivational Interviewing
Jul 10, 2024



We introduce a novel application of large language models (LLMs) in developing a virtual counselor capable of conducting motivational interviewing (MI) for alcohol use counseling. Access to effective counseling remains limited, particularly for substance abuse, and virtual agents offer a promising solution by leveraging LLM capabilities to simulate nuanced communication techniques inherent in MI. Our approach combines prompt engineering and integration into a user-friendly virtual platform to facilitate realistic, empathetic interactions. We evaluate the effectiveness of our virtual agent through a series of studies focusing on replicating MI techniques and human counselor dialog. Initial findings suggest that our LLM-powered virtual agent matches human counselors' empathetic and adaptive conversational skills, presenting a significant step forward in virtual health counseling and providing insights into the design and implementation of LLM-based therapeutic interactions.
Empathic Grounding: Explorations using Multimodal Interaction and Large Language Models with Conversational Agents
Jul 01, 2024We introduce the concept of "empathic grounding" in conversational agents as an extension of Clark's conceptualization of grounding in conversation in which the grounding criterion includes listener empathy for the speaker's affective state. Empathic grounding is generally required whenever the speaker's emotions are foregrounded and can make the grounding process more efficient and reliable by communicating both propositional and affective understanding. Both speaker expressions of affect and listener empathic grounding can be multimodal, including facial expressions and other nonverbal displays. Thus, models of empathic grounding for embodied agents should be multimodal to facilitate natural and efficient communication. We describe a multimodal model that takes as input user speech and facial expression to generate multimodal grounding moves for a listening agent using a large language model. We also describe a testbed to evaluate approaches to empathic grounding, in which a humanoid robot interviews a user about a past episode of pain and then has the user rate their perception of the robot's empathy. We compare our proposed model to one that only generates non-affective grounding cues in a between-subjects experiment. Findings demonstrate that empathic grounding increases user perceptions of empathy, understanding, emotional intelligence, and trust. Our work highlights the role of emotion awareness and multimodality in generating appropriate grounding moves for conversational agents.
Keeping Users Engaged During Repeated Administration of the Same Questionnaire: Using Large Language Models to Reliably Diversify Questions
Nov 21, 2023Standardized, validated questionnaires are vital tools in HCI research and healthcare, offering dependable self-report data. However, their repeated use in longitudinal or pre-post studies can induce respondent fatigue, impacting data quality via response biases and decreased response rates. We propose utilizing large language models (LLMs) to generate diverse questionnaire versions while retaining good psychometric properties. In a longitudinal study, participants engaged with our agent system and responded daily for two weeks to either a standardized depression questionnaire or one of two LLM-generated questionnaire variants, alongside a validated depression questionnaire. Psychometric testing revealed consistent covariation between the external criterion and the focal measure administered across the three conditions, demonstrating the reliability and validity of the LLM-generated variants. Participants found the repeated administration of the standardized questionnaire significantly more repetitive compared to the variants. Our findings highlight the potential of LLM-generated variants to invigorate questionnaires, fostering engagement and interest without compromising validity.
TEASEL: A Transformer-Based Speech-Prefixed Language Model
Sep 12, 2021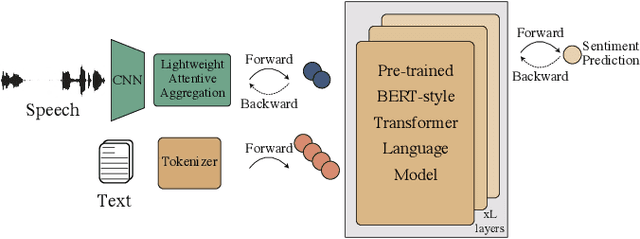
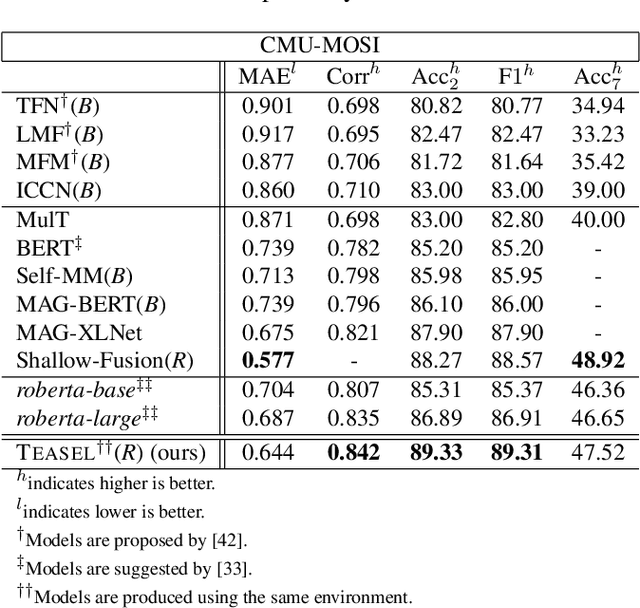
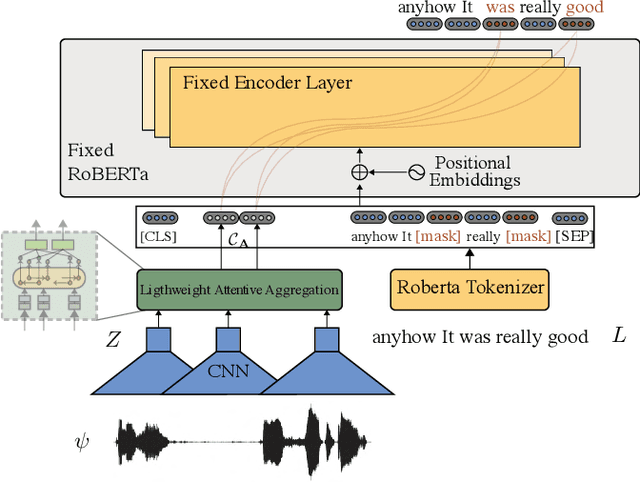
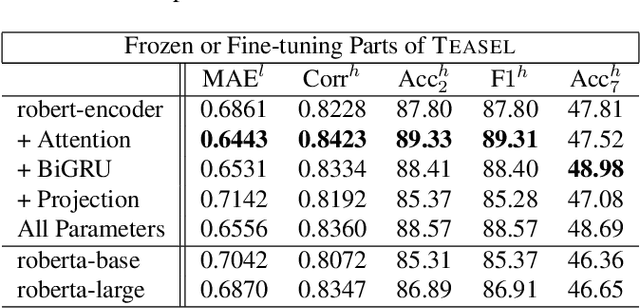
Multimodal language analysis is a burgeoning field of NLP that aims to simultaneously model a speaker's words, acoustical annotations, and facial expressions. In this area, lexicon features usually outperform other modalities because they are pre-trained on large corpora via Transformer-based models. Despite their strong performance, training a new self-supervised learning (SSL) Transformer on any modality is not usually attainable due to insufficient data, which is the case in multimodal language learning. This work proposes a Transformer-Based Speech-Prefixed Language Model called TEASEL to approach the mentioned constraints without training a complete Transformer model. TEASEL model includes speech modality as a dynamic prefix besides the textual modality compared to a conventional language model. This method exploits a conventional pre-trained language model as a cross-modal Transformer model. We evaluated TEASEL for the multimodal sentiment analysis task defined by CMU-MOSI dataset. Extensive experiments show that our model outperforms unimodal baseline language models by 4% and outperforms the current multimodal state-of-the-art (SoTA) model by 1% in F1-score. Additionally, our proposed method is 72% smaller than the SoTA model.